I'll begin this article with a question. How do you test the HTTP requests generated by your app?
There are many approaches that can come to mind. All of them have their pros and cons.
Most of them rely on totally stubbing the HTTP calls to the external services and returning fake and controlled responses. With that, we make sure that tests are performed in isolation and never hit the real external APIs.
These are important points to consider, since reaching for the real APIs is hardly a good idea. It can make your tests slow and flaky, depending on availability of external services. Also, by stubbing the requests with fake responses, it's easy to test different happy and unhappy paths by easily switching the fake responses being used in each of your test scenarios.
Other cons of having real HTTP calls on tests are (taken from here):
- Flaky tests due to connectivity issues.
- Dramatically slower test suites.
- Hitting API rate limits on 3rd party sites.
There are many gems available to help you avoiding making real requests, like webmock, vcr, fakeweb, no matter if you're using Rspec or Minitest.
Another good pattern which we should always do when using an external API in our code is to wrap the calls in a FooClient class, which has the sole responsability of knowing how the API is used, what are the request parameters and their formats, how to parse the responses, etc. So everything regarding the API specs are well encapsulated in one single class. Normally, this class will be directly linked to the API's official documentation and will change following the API changes. Example:
##
# Encapsulates the HTTP requests to Acme Corp. official API.
#
# For more info please refer to https://url.to.acme.api.documentaion
class AcmeAPI::Client
def products
response = get("#{BASE_URL}/products", default_headers)
# Parses the response and returns it, ideally in an easy-to-use
# object like an array of AcmeAPI::Product or something else.
end
end
With this abstraction, when unit testing a consumer of this client object, if you're using good practices like dependency injection, it's easy to provide in the tests a stubbed FooClient instance which provides controlled responses and allows different scenarios to be tested in isolation.
describe Coyote do
let(:coyote) { Coyote.new(acme: acme_client) }
let(:acme_client) { AcmeApi::Client.new }
before { acme_client.stubs(:products).returns(%w[dynamite spikes]) }
it 'sets up a trap successfully' do
assert_instance_of Trap, coyote.set_trap
end
context 'when Acme does not have any products' do
before { acme_client.stubs(:products).returns(%w[]) }
it 'raises an error' do
assert_raises(LackOfResourcesError) { coyote.set_trap }
end
end
end
Normally, well-used 3rd party services already provide their own SDKs in different programming languages, abstracting away all the API calls and responses. In this case, you would only need to add the gem and use stubbed versions of the SDK classes in the tests.
"Ok, but what about asserting at runtime? You wrote it in your article's title, right?"
You're right. But first I had to set the ground and describe the most used approaches when it comes to test code when external API calls are involved.
The reason I asked "How do you test the HTTP requests generated by your app?" it's because there is some debate on whether the real API should be tested at all in your automated tests.
Normally you would do that in an end-to-end integration test. Since these tests are slow, you could mark them in a way that they are not always executed, but only when explicitally so. You could do that with Rspec for example, my marking them with a special type: :integration tag and running them not so often. Maybe just a few times in your CI pipeline to make sure that the API your code is using and the response it relyies didn't change suddenly and everything should be working normally. Something that the quick and stubbed tests wouldn't be able to catch, since they are relying on pre-defined responses you came up based on the documentation checked at the time of implementation.
But since these integration tests are reaching for the real API, they would still present the same problems mentioned in the beginning of this post, like flakiness, accessility issues, etc.
What to do then to catch possible integration issues as early as possible?
Testing at runtime
Let's bring back the previous Acme example. Suppose we have an additional endpoint where the Coyote fetches the product details in order to read the user manual and to know how use it before setting up a trap.
When we run the application, we would see the following output.

The coyote reached for the Acme API to fetch a product, in this case a dynamite, then fetched the product manual and read it before setting up the trap.
One simple approach I'm very happy with is to assert the responses from the API whenever they are performed during runtime.
So in the Acme API Client, when fetching for a product's details, we would assert that the user_manual is there, since this is required by the app.
def product_details(product_name)
response = get!(
url: "#{BASE_URL}/product_details/#{product_name}",
headers: default_headers,
expects: %i[user_manual]
)
# process the response and return
end
private
def get!(url:, headers:, expects: {})
http_response = RestClient.get(url, headers)
json_response = JSON.parse(http_response.body)
check_expectations!(json_response, expects)
json_response
end
def check_expectations!(json_response, expectations)
expectations.each do |expected_attr|
next unless json_response[expected_attr.to_s].nil?
raise ExpectationError, expected_attr
end
end
This makes sure that, whenever we hit the Products API to fetch the details of a specific product, apart from other attributes that might be present in the response, we assert that user_manual is included, since this is the data we're interested in.
In case the attribute is not present, we fail loud with an error. This adds an additional safety check in case the API changes unexpectedly and this data is not there or the attribute key changed, etc.
You might ask what benefit does this bring, since even without this additional expectations check, if the data is not there, an error would be raised anyway, most problably down the road by whoever is making use of this API client's response.
This is the catch and the issue is in that exact last sentence: most probably and down the road.
If we don't have that check, we have to make sure that, whoever is using the Acme client, be the Coyote class or any other, diligently check that the response returned from the client is in a good state and raise the approptiate error in case the data is not there. This can be very brittle.
Suppose that the API changed unexpectedly and the user_manual is now being returned as user_guide instead (bad job of Acme dev team on failing to maintain a consistent API spec).
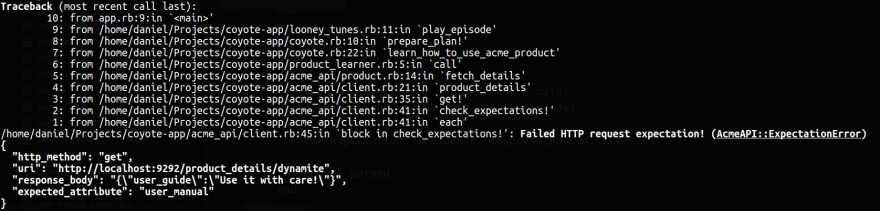
If Coyote is diligently checking the data it got back in the response, it could raise an error when it sees that the user manual is not there and we would catch that in the bug reporting tool. The problem is that we would see this error being raised in the Coyote class and would need to track down of what went wrong, hopefully finding that the problem was in the request's response.

The image above represents what the error could look like. The stack trace is small and still relatively easy to track down the culprit. Since Coyote is the direct consumer of the API client, this is not a big issue. But can be particularly annoying if this data is only being passing forward to other objects, making the error being raised much farther down the road. Since more indirections are involved, the stack trace would be bigger and tracking down the root cause would be a bit harder.

Another more serious problem would be in the case this user_manual data is not being checked in case it gets back empty. If the Coyote (or whoever is processing this information) realizes that this user_manual is empty and assumes it's because the product does not have any user manual set up, this mean that we now have a silent bug happening in our application. A wrong assumption is being made that the product does not have user manual and the app is behaving on top of this assumption, even though the user manual exists, it's only being returned as user_guide instead.
The image below represents the Coyote making the wrong assumption about dynamites and using it without ever reading the user manual!

What the expectation check step in the Client class gives us is the guarantee that it'll fail in case anything that we expect to be there is missing. By failing loud with a nice error message, we know what went wrong and where it happened. We can then act quick and make sure to update the Client implementation to conform with the new state of the API specs.
It's also very nicely encapsulated in the API Client class, which is the one responsible to know, not only the requests URLs and parameters, but also which response attributes are supposed to be there, since these are all part from the API specifications.
The example in this article was kept simple on purpose. We're only checking the attributes in the JSON response in the first layer. But it can be easily extended to check nested attributes, array responses, not only the presence of attributes but also formats, etc.
Not to forget that this is just another layer of checking the API integration and its correct usage. It does not mean that the isolated unit tests and possibly any end-to-end test (as mentioned in the beginning of the post) should cease to exist. Theye are all suppose to work alongside each other.
Does that approach make sense to you? For me it's working great and I was able to catch errors beautifully in my bug reporting tool. Let me know in the comments.
Note: you can check the Coyote App example used in this article if it helps. Just make sure to read the README :)





Top comments (0)