
In the 21st century, it's quite easy to manipulate machines and computers. Our worries are no longer if something is doable, but if something can be perfected. Therefore, we mostly search for new ideas and ways to make our work impeccable. For example, if you're using a particular software and you realize that the software is excellent, but it could be better in some ways that would allow you to work even faster, you'll explore the alternatives. There are all kinds to choose from, and you will search for the one that is most suitable for your own needs. Every one of them has some perks of their own, and in others, you'll notice some faults.
In this article, we'll make a brief introduction, and we'll also talk about the differences between CloudWatch alerts vs. Dashbird alerts. Which one is better and why?
What is AWS CloudWatch Used For?
AWS CloudWatch is built for system operators, site reliability engineers (SRE), IT managers, and developers. CloudWatch allows you to monitor your applications via data access and insights it provides. It can also recognize, understand and respond to all changes happening throughout the entire system.
CloudWatch is also collecting monitoring and operational data through metrics, events, and logs which further provides you with a unique view over the AWS resources, services, and apps that run on AWS, as well as in the localized servers. CloudWatch enables you to set alarms (or alerts), troubleshoot for issues, and discover the insights for application optimization which will ensure that the application runs smooth.
AWS CloudWatch Alerts Explained
A CloudWatch alert (a.k.a. alarm) can watch over a single CloudWatch metric or even a result of math expression found in CloudWatch metrics. Alerts will perform single or multiple actions based on the value of metric or expression which is relative to a threshold over a number of time periods. Adding alarms to AWS CloudWatch dashboard is enabled and that way you'll be able to monitor them visually. There are three alarm states:
- OK -- meaning that the expression or metric is found inside the already defined threshold;
- ALARM -- implies that the expression or metric are located outside of the specified threshold;
- INSUFFICIENT_DATA -- this alert is shown when the alarm has already started but the metric is not available, or there's not enough data for the metric to realize in which state the alarm is.
When creating an alarm, you are able to specify three settings which will allow CloudWatch to evaluate when to change the alarm state:
- Period -- will enable you to evaluate the time length of metric or expression in order to create an individual data point for an alarm;
- Evaluation Period -- is the number of the recent data points you need to evaluate to be able to determine the state of the alarm;
- Datapoints to Alarm -- is the number of data points in the evaluation period which must be breached, so it's causing the alarm to go to the ALARM state. These breaching data points must all be within the last number of data points which is equal to the Evaluation Period.
There are a lot of features that apply to all AWS CloudWatch alarms, and we'll go through some of them. For example, the number of evaluation periods for an alarm if multiplied by the length of every evaluation period can't surpass the one-day limit. Another feature worth mentioning is that ASCII characters must be included in alarm naming. You are also able to create 5,000 alarms within every region per a single AWS account.
Metrics
CloudWatch gathers basic metrics, which further allows you to monitor how the entire system performs. The collected metrics for Lambda functions are latency, invocations, errors, and concurrency. Since the chances of you checking the metrics precisely at the same time when something goes wrong are pretty slim, it would be wise to configure alarms upfront (more on this and best practices below). Do this in case an unexpected event meets a condition or threshold so the alarm could notify you in time.
How to Set Up Your Metric Alarms on AWS CloudWatch?
You should first configure a CloudWatch metric alarm to trigger an SNS topic, but only if the predefined condition is fully met. The SNS trigger will then invoke a Lambda function to take action. This action will send notifications so you can further investigate the issue.
Setting Up Metric Alerting on AWS (Best Practices)
Can you recognize the optimal time to configure a metric alarm? The answer depends on whether you'd like to receive alerts only in cases that require your immediate attention or not. Even if you set them up to alert you often, responding to each and every alert is not feasible. It means that it won't be long before you miss a crucial alert, which is bound to happen either because of the noise or because you began ignoring alerts entirely.
Try to understand all of it this way:
- Do you think it's okay if 1% of all requests fail due to a single function?
- Is it of vital importance that all requests take no longer than 1 second?
In these cases, you'd probably want to know if your Lambda is reaching a concurrency limit (account-wide). All these settings are completely individual for each application, and it usually takes some time and iterations before you can get it to an acceptable level.
Another thing you should think about is configuring naturally preventive alerts. These alerts will trigger even when nothing has failed yet, but it might happen soon. A good example will be if a Lambda function is close to a timeout or even closer to fill its memory capacity -- remember that CloudWatch attains metrics for invocation counts, latency, memory usage, and failures by default.
High-Resolution Metric Alarms
If you set the alarm on a high-resolution metric, you're allowed to specify a high-resolution alarm in specific time groups (10 or 30 seconds). Moreover, you can set up a standard 60-second alarm multiple times. It's also essential to know that high-resolution alarms are charged at a higher rate so be sure to do a cost analysis if that could be a potential issue.
Standard AWS CloudWatch Alerts Features
CloudWatch alarms have numerous features, and the ones listed below are common and apply to all alarms:
- Each AWS account can create up to 5,000 alarms for each Region. You should use the CloudWatch console if you wish to update an existing alarm or create a new one. Use the command put-metric-alarm in AWS CLI or utilize an API action called PutMetricAlarm that's also available.
- Only ASCII characters are allowed in alarm name fields.
- You can either enlist some or even all of the alarms that are currently configured. You can also list any alarms within a particular state by utilizing the CW console by looking for an API action DescribeAlarms. Alternatively, look in AWS CLI for the command describe-alarms.
- You can also enable or disable alarms via the CloudWatch console. To do so requires you to look for API actions EnableAlarmActions and DisableAlarmActions. As an alternative, you can look for the following commands in AWS CLI: enable-alarm-actions and disable-alarm-actions.
- Set the alarm to any state to test it by utilizing either an API action: SetAlarmState, or by utilizing command in AWS CLI: set-alarm-state. Remember that when the next alarm comparison happens, this temporary state change will be over.
- It's possible to create a custom metric alarm even before making this particular custom metric. You have to include all of the custom metric's dimensions along with the metric name and metric namespace within the alarm definition to make it valid. You can do this via a command in the AWS CLI: put-metric-alarm, or via API action: PutMetricAlarm.
- Viewing an alarm's history is possible via CloudWatch console as it saves alarm history for 14 days. You can either use a command in AWS CLI: describe-alarm-history, or an API action: DescribeAlarmHistory within the console. You should know that every state transition has its unique mark in the form of a timestamp. Make note that your history might show even more than one notification for a single state change. However, that's quite rare. Also, you can confirm all unique state changes as the timestamp enables you to do so.
- The evaluation periods' quantity for each alarm multiplied by the length of each and every evaluation period can't exceed 24 hours.
Dashbird Alarms and Notifications Explained
Dashbird's instant alerting system will notify you if any issue shows up within any part of your application. Issues such as crashes, cold starts, runtime errors, timeouts, configuration errors, and early exits. Its system offers messages and realistic logs that humans can easily read and understand, which saves you and your company meaningful debugging time. Dashbird monitors your application and is able to detect all kinds of errors in various runtime environments.
The Events page does everything an observability tool should -- showcase all errors occurring within your system. With Dashbird, you can customize which events to track and how you want to get notified. Everything mentioned above works for programming languages supported by AWS Lambda, including Node.js, Python, Java, and C#.
All the required data to successfully go through troubleshooting events and resolve any app issues are entirely at your disposal. A human-friendly interface will present you with any previous occurrences, stack traces, etc. Logs and trends for every error or problem are also available. You can use a "more info" button for every single error you face, and that way, you'll see the error page with all the needed info for debugging the current issue.
Configuring an Alert Policy (Alarms) with Dashbird
To configure an alert policy, simply visit Events from the left navigation menu and click on the Settings tab on the Events panel. From here, click on Alarms and click + ADD:

Dashbird gives you complete control over Alarms as it allows you to choose which error reports you should receive. You're required to set and configure the Alarms rules. That way, you're adding a new policy to the list, and from there, you can start configuring how you want to be notified of Alarms.
Defining Alarms for any 'error overall functions' is possible, but you can also set the system to alert you when a specific microservice or function experiences invocation timeouts.
Setting Up Notifications
Proactive alerts are another one of Dashbird's features. You could set up an email notification system or seamlessly integrate it with Slack. We also support SNS and webhooks.
All policies require at least one alert condition along with one notification channel. An alert state consists of different functions and error conditions, while a notification channel can either be an email address or even Slack.
The Best Ways to Handle Alerts
Consider alerting as an ongoing process. Therefore, we at Dashbird recommend you to test different policies. These are some basic principles and suggestions on how to handle alerts when they emerge:
- You should add new Alarms whenever you need them, but you should also mute or delete unnecessary ones so you would avoid alarm fatigue.
- Even if you think production Lambdas will never fail, you should set alerts for them too, as unexpected circumstances tend to happen from time to time.
- If you've fixed alerts within the code, it's always mandatory to resolve them as well. By doing so, if the same problem happens again, you'll receive a new notification.
Conclusion
Both CloudWatch and Dashbird have their pros and cons, and we'll wrap up here after mentioning a few.
While Cloudwatch is mostly an excellent choice for users who are already inside the AWS ecosystem, it's not all that great for the ones who aren't, and they should find a simpler solution. The alerting options for CloudWatch are not as boundless since they're available with third-party services.
Moreover, CloudWatch doesn't offer pre-configured alerts.
It would be best if you create custom alerts by yourself, which means you must be very familiar with how everything works in order to create them properly. On the other hand, Dashbird's alert notification system is automated and instant, which undoubtedly provides you comfort and ease if something happens within your application.
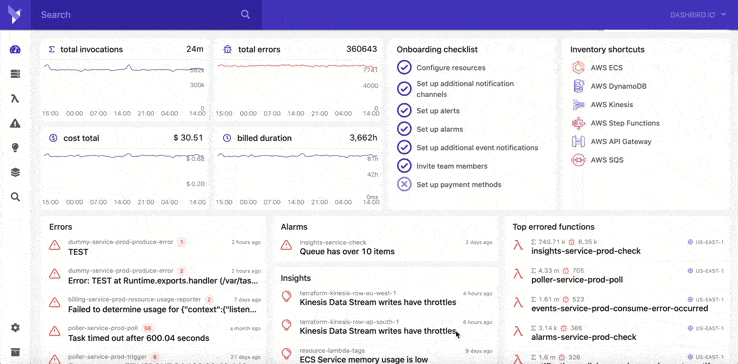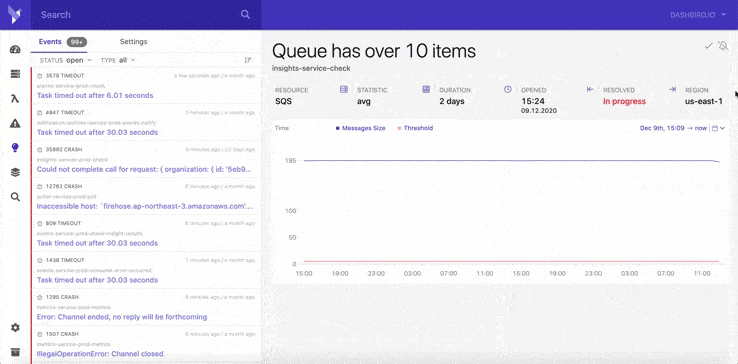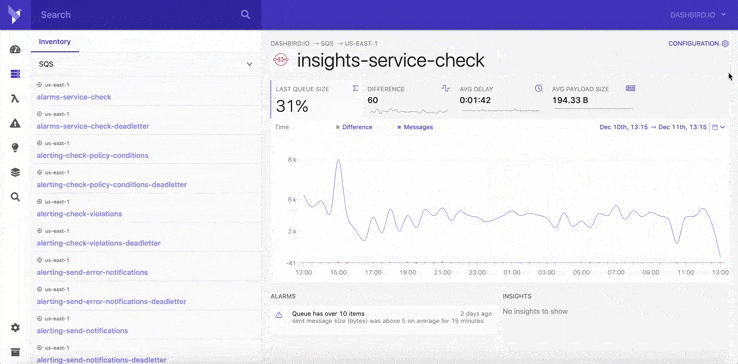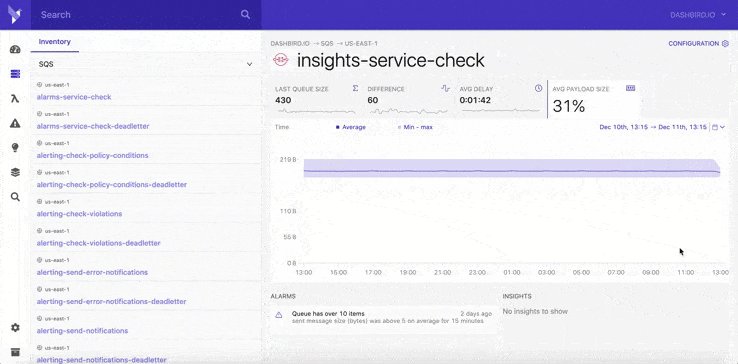
During the past three years, we've heavily invested in the new Dashbird app interface and building the next stages of our platform. We've expanded our offer, and it now includes services like API Gateway, Step-Functions, DynamoDB, Kinesis, ECS, and SQS, and many more to come soon.
See how you can set up your own alarms by signing up.





Top comments (0)