Intro
Programmatic and scalable web scraping is hard to do. There's a lot of build and maintenance involved that has nothing to do with the actual scraping task.
Serverless computing makes it quite a lot easier.
All you need to worry about is scraping the website in a friendly manner.
Let's jump into creating a serverless web scraper with Python and hosting it on AWS Lambda by using Chalice to do all the heavy lifting for us.
We are going to create a small scraper that returns today's #1 product on ProductHunt. (BTW: this is 100% doable using the ProductHunt API)
Here is the repo for the project: https://github.com/DannyAziz/serverless-product-hunt-scraper
1. Set up Dev environment 🛠
Set up your python virtual environment and install chalice
mkivrtualenv serverless_scraping
pip install chalice
Make sure to install this dependency via pip, we will be using this to make our scraping life easier:
pip install requests_html
2. Set up Chalice with AWS 🔑
You need to authenticate your machine with your AWS account. If you've done this before, move on to the next step.
First, you need access keys, to get these: Go to the Security Credentials page from the dropdown in the top right corner
Expand the "Access Keys" dropdown and click "Create New Access Key"
Make sure to note these down somewhere as you won't be able to see these again.
Now you need to save these keys into a AWS config file:
Create the AWS config folder
mkdir ~/.aws
Create and open a new file
nano ~/.aws/config
Paste this in, making sure to replace the keys and region with your own keys and region
[default]
aws_access_key_id=YOUR_ACCESS_KEY_HERE
aws_secret_access_key=YOUR_SECRET_ACCESS_KEY
region=YOUR_REGION (such as us-west-2, us-west-1, etc)
3. Create Scraping Script 🕸
Create the chalice project
chalice new-project producthunt-scraper
Inside your chalice project there will be an app.py file, replace the file with the following code:
from chalice import Chalice
from requests_html import HTMLSession
app = Chalice(app_name='producthunt-scraper')
@app.route("/product-hunt/top-product")
def get_top_product_product_hunt():
session = HTMLSession()
url = 'https://www.producthunt.com/'
resp = session.get(url)
product_list_containers = resp.html.find(".postsList_b2208")
if len(product_list_containers) == 1:
product_list = product_list_containers[0]
else:
product_list = product_list_containers[1]
if product_list:
top_product = product_list.find("li")[0]
product_obj = {
"name": top_product.find(".content_31491", first=True).find("h3", first=True).text,
"url": "https://producthunt.com{url}".format(url=top_product.find("a", first=True).attrs["href"]),
"description": top_product.find(".content_31491", first=True).find("p", first=True).text,
"upvote_count": top_product.find(".voteButtonWrap_4c515", first=True).text,
}
return product_obj
else:
return {"error": "Product List Element Not Found"}
Let's break down the code a little.

All serverless functions in chalice are regular python functions, they need an @app decorator applied to them for the function to be called. In this example, we are using @app.route as we want our function to be called when it's requested via HTTP but you could do @app.schedule to run the function on a schedule or the other methods which you can find out about here: https://github.com/aws/chalice

The main part of our function uses the requests_html package to do all the heavy lifting for parsing the HTML document and pulling out the elements based on class names and HTML tags.
Finally, we either return an object which contains the top product or an error.
4. Deploy 🚀
You can test this scraper out locally via the chalice local command, this will create a local server reachable via http://localhost:8000 that you can test your endpoints with.
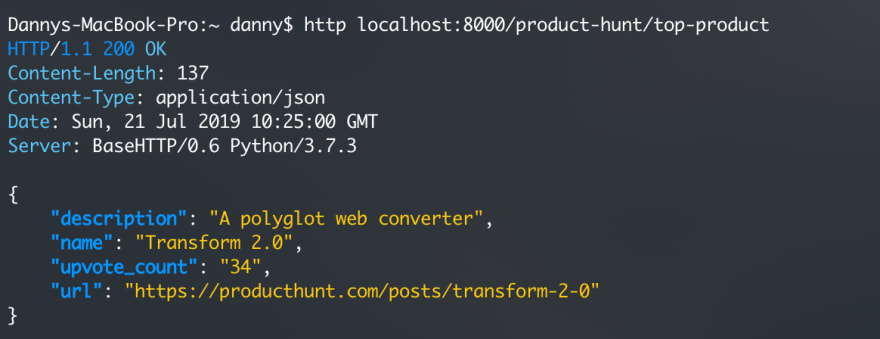
Once you're ready to go, use this command: chalice deploy
Chalice will now take care of everything, including creating the AWS lambda function in the console and packaging up all the dependencies for AWS lambda to use.
5. Done 🎉
The deploy command should have spat out a URL, this is the public reachable URL for your serverless function and for our ProductHunt scraper.
You've just created your first serverless scraper!
More Reading 📖
Check out the Chalice docs here - https://github.com/aws/chalice
Check out the AWS Lambda docs here - https://docs.aws.amazon.com/lambda/latest/dg/welcome.html
This post was originally created seen over at https://blog.dannyaziz.com





Top comments (0)