
Make Database Studies Great Again!!!
Table Of Contents
- 1. Prologue
- 2. There's much more possibilities than MySQL
- 3. SQL vs NoSQL
- 4. Choose Wisely
- 5. The Coolest Database Paradigm
- 6. Final Considerations
TL:DR
In this article I will share what I've learned during my database study sessions about what fascinated me on Database topic until now.
1. Prologue
In the end of 2022 I decided to make things more clear when the subject is Databases, because this was always a pain, as a Backend Developer, have the pleasure to hate complex database queries. With that in mind I challenged myself to start from scratch and learn about this poorly explored world just for fun.
2. There are many possibilities than MySQL
I didn't finish college and I didn't see anything about Databases when I was there, so I don't have any theoretical background and on these 4 years coding at enterprise level my focus was totally in things like: Clean Code, SOLID, Design Patterns and other stuff code related and my only Database knowledge was about SQL/MySQL and Cache/Redis.
In the first five minutes googling stuff, asking content recommendations on Twitter, I just landed in this video called "7 Database Paradigms" that totally blew my mind. Like, there's more than Key-Value and Relational? WAT
Here's a list of Paradigms and the respective concrete implementations:
- Key Value: Redis
- Wide Column: Apache Cassandra, ScyllaDB and DynamoDB
- Document: MongoDB
- Graph: Neo4J
- Relational: MySQL, MariaDB, PostgreSQL
- Search Engine: ElasticSearch
- Multi-model: FaunaDB, MongoDB, Redis among others.
3. SQL vs NoSQL
Since we're trying get into a new challenge, my main focus was to detach from everything that I felt comfortable with and research things that I hadn't see before, and it includes this word that I always heard about mostly in the NodeJS world: NoSQL.
I know that SQL (Structured Query Language) is used by MySQL, OracleDB, SQLServer but I never tried to understand why there's such a "Reverse SQL" or "Anti SQL" so I digged down to understand the difference first and briefly:
// Structured
table: users
id: int
name: string
table: user_addresses
id: int
user_id: int references id in users
address: string
table: users
--------------------
| id | name |
| 1 | danielhe4rt |
--------------------
table: user_addresses
---------------------------------------------------------
| id | user_id | address |
| 1 | 1 | Flowers St. 123, São Paulo/SP - Brazil |
---------------------------------------------------------
SQL is driven by: tables, rows and columns
// database-prod.json
{
"users": [
"huid2d12bdh12b": {
"id": 1,
"name": "danielhe4rt",
"addresses": [
"jio32fsdyhis": {
"address": "Flowers St. 123, São Paulo/SP - Brazil"
}
]
}
]
}
NoSQL is driven by: documents, collections and fields.
Something that caught my attention was how NoSQL has tons of cool features to research, since we have Key-Value, Document, Wide Column as options to study.
I chose Wide Column Database to keep digging in my studies cause there's two cool subjects that I found which is Replication Factor and Consistency Level that I want to approach, but first we need to talk about CAP Theorem.
4. Choose wisely
CAP Theorem based on Databases
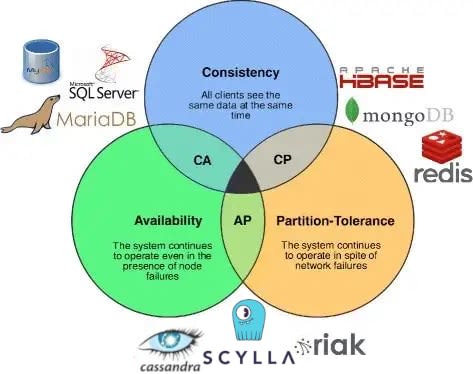
Some badass guy called Eric Brewer identified that distributed data store can provide only 2 of these 3 guarantees: Consistency, Availability and Partition Tolerance. Well, you can have all of them if you're reasonable enough, but that's a topic for another article.
Ok but what's these items meanings? Like, why should I care for this? Theorem is not some mathematical boring stuff? NO IT'S NOT so FOLLOW ME ON THAT PLZ!!! As I was saying, we need to comprehend these pillars:
- Availability: you have the data in different nodes and if a couple of them fails you should still have the data available.
- Consistency: you update some data, but there's no guarantee that is the recent write since the replication operation didn't finished in the other datacenters, but it can be configured using Consistency Level.
- Partition Tolerance: if there's any failure to communicate between the replicas/nodes, can I continue the operations?
At this point we already have a lot of concepts to understand and keep grinding on our journey, but now we gonna see one last step and the reason why I wanted to write this article: Wide Column Database Paradigm!
5. The Coolest Database Paradigm 😎
That's right, the coolest Database Paradigm in my opinion is Wide Column Database and I'm gonna explain why in four topics:
- Paradigm
- Databases Built on top of this paradigm;
- Replication Factor;
- Consistency Level.
5.1 Paradigm
Imagine that you're modeling thinking in columns and not rows as expected by SQL languages. These columns are flexible since it's based in collections, we can say that modeling is flexible and you need a schema to run queries on that.
Talking about Queries: this paradigm isn't supposed to be NoSQL? Well, not exactly. There's one of the databases called Apache Cassandra that introduced the CQL or Cassandra Query Language. So there's queries related huh?
In SQL Joins are supported and in CQL doesn't. How the queries is written looks similar in both Query Languages.
5.2 Cassandra and ScyllaDB
The most famous Database to use Wide Column is still Cassandra, besides still being chosen for a lot of developers that doesn't met the worthy Cassandra competitor yet: the ScyllaDB.
What is the difference? They're using the same paradigm, so they should be about the same... RIGHT???
Not at all. Apache Cassandra is an open source tool built using Java and ScyllaDB born of a necessity to improve the read/write operations on this database paradigm to a whole new level.
ScyllaDB is written in C++, which is close to low level and with that we got some improvement of 2x to 8x more performance. Following this path, it has to be more cheaper to maintain since it's more performant. Also, ScyllaDB use the SAME DRIVERS than Cassandra, so you can just switch from Cassandra to Scylla without many problems.
Now we can go to the coolest features :p
5.3 Replication Factor (RF)
One of the features that Cassandra and ScyllaDB support is the Replication Factor, a flag that allows you write in a row and replicate the given data to all next nodes available.
If you set the RF to 3, when you store any data it should be replicated to the three next nodes and it guarantee that you will have the data even if the main node lost the data. There's the SimpleStrategy flag that implies to replicate in the local cluster and the NetworkTopologyStrategy that implies to replicate in multiple datacenters.

5.4 Consistency Level
Now we can talk about truthiness on writing operations and for that we need to understand why Consistency Levels are so important.
Imagine that you're in a court house and after you tell your story about you're innocent about any random topic, the local and virtual jury should decide based on a rule that will can be one of these: ONE, QUORUIM, LOCAL_QUORUM and ALL.
- If the judge decides that the rule is ONE, then only one person from the jury have to vote for you and claim your innocence.
- If the judge decides that the rule is QUORUM, then 51% of the local and remote jury have to vote for you and claim your innocence.
- If the judge decides that the rule is LOCAL_QUORUM, then 51% of the local jury have to vote for you and claim your innocence.
- If the judge decides that the rule is ALL, then 100% of the local and remote jury have to vote for you and claim your innocence and you're probably fu**** LOL.
The same can be implied to the database ecosystem. If you write in the primary database and your CL is QUORUM, you have to write in the other disks until it's the majority to claim the data as written. Cool, isn't?

I write all of this just because I liked how these two items together can give you a good night of sleeping since you know that you're data has replicas everywhere and there's almost no chance of loosing it if you configure it well.
6. Final Considerations
Even after this study my feeling is that I don't know NOTHING about database paradigms but the idea here is to make a provocation about the subject and make you curious at the point of you research and make more content of this topic.
That's it, thanks for reading until here. Don't forget to fill your water bottle! xD





Oldest comments (42)
starting to read
very good article!
nice reading and a lot of useful content, thanks man!
Good content! I learned a lot!
Nice content, Daniel! Tks for sharing with us!
Very good.
Awesome post! Thank you.
you're awesome my brudda
You just made me understand something I was struggling a lot! Big thanks 👏👏
awesome content, thank you for sharing Daniel!
Great article, I use Elastic Search and didnt even know that was a paradigms
Pretty awesome!
Pretty good!
Pretty good!
Nice article. I think I will start learning more about ScyllaDB. Not only because I like Greek Mythology, but also because it sounds interesting!
Some comments may only be visible to logged-in visitors. Sign in to view all comments.