
The Heart Of A DB And The Soul Of A DLT…
A Brief Overview of Quantum Ledger Database.
And So Begins The Quest…
At the heart of every great innovation, there is a need. The same holds for ledger technologies. Take, for example, our first attempt at this technology. No, I am not talking about satoshi and bitcoins. My story is way older, like 5000–6000 years old. In a much simpler time, some random Mesopotamian citizens, presumably farmers, were looking for ways to keep track of their produce. They did so by inscribing the images representing their products, along with its quantity, onto clay tablets. The incident marked our very first attempt at creating a ledger technology.

There was a need, and thus a solution was born. The clay tablets marked the beginning of a quest, A quest to find the perfect ledger technology. Everything from the double-entry system to Distributed Ledger Technologies(DLT) stemmed from this Quest.
With DLTs, things got very interesting. Remember a couple of years ago when people started building DLTs just for the sake of it, you know, one for every occasion. It was the hot new pie, and everybody wanted a piece of it.

Recent trends, however, show a decline in this erratic behavior. As per the Gartner Graph, People are moving out of the ‘DLT can cure cancer’ phase to a more practical outlook. We are starting to look at use-cases where the technology serves an actual need (You got to have the need !).
Speaking of Quests and needs, In September 2019, Amazon introduced their latest contender for the Quest.

A tried and tested contender if I might add.
So, the purpose of this blog is to explore the story and the reason behind this new contender.
The Story
We are well aware of the vastness of AWS(Amazon Web Services). They are one of the leading cloud service providers out there. From storage to computation, they provide enough products to fill up a store.

Now, With great many services, comes greater responsibilities. I mean, think about it, there are more than a million customers, big and small, that rely on these services. Imagine the kind of data that these guys deal with daily. Apart from the user data, AWS also has to keep track of the data regarding various internal operations and systems that are responsible for running these services. Now, This kind of data can be quite tricky. Merely storing these data won’t do you much good. You also have to find ways to keep track of all the changes that the data goes through. That way, you can use these “logs” when you need to conduct an audit or if you want to track an error or if things go haywire in general. Another challenge that comes with this kind of data is maintaining its integrity.
Oh, you might also want to keep it immutable, I mean, you wouldn’t want people to tamper with this kind of critical logs, now would you?

At this point, many of you might say things like, “Well, They must have an awesome database that takes care of all this.” Well, They sure did. But, While using traditional databases for this purpose, They found out that it could not scale or deliver the performance required to support their most widely-used services.
That’s when the people at AWS decided to build a new technology to address these issues. They developed a new kind of database to store and track data. The database helped maintain a complete, immutable, and append-only record of data changes. There was a need, and thus a solution was born. For years, they used this technology to track the changes in their data (Especially Configuration details and things like that). The technology helped resolve the scalability and performance issues that they faced with the traditional databases. Everything was at peace, and AWS continued to prosper. The End.

Just kidding.
Serving The Need!
According to the wise words of Mark Manson, “If you’ve got a problem, chances are millions of other people have had it in the past, have it now, and are going to have it in the future.” It implies that a viable solution to the problem might help all these people. So, like any brilliant company, Amazon Interacted with its customers and found out that many of the customers faced the same kind of issues that they faced.
You see, Tracking data changes is critical to many businesses, But creating audit functionalities using a traditional database involves creating audit tables and stuff like that. These things tend to get complicated. As the complexity increases, so does the chance of error. The entangled set of tables also affects scalability. Did I mention the fact that databases, in general, are not immutable or that it takes time to incorporate such functionalities using traditional databases?
So, after considering all this, In September of 2019, Amazon introduced their new contender, labeled Quantum Ledger Database(QLDB), to the general public.

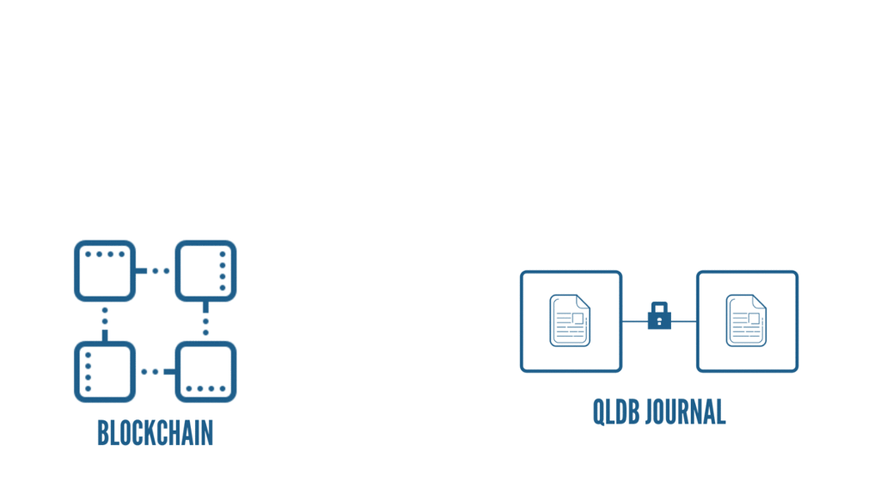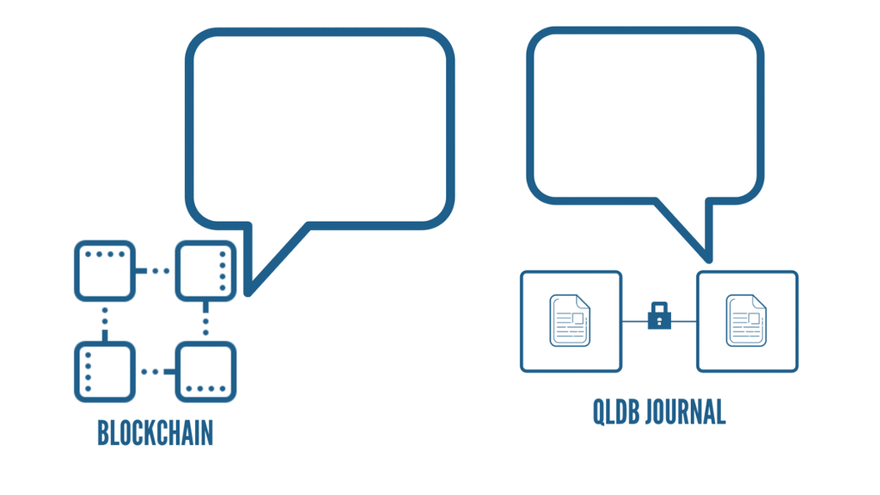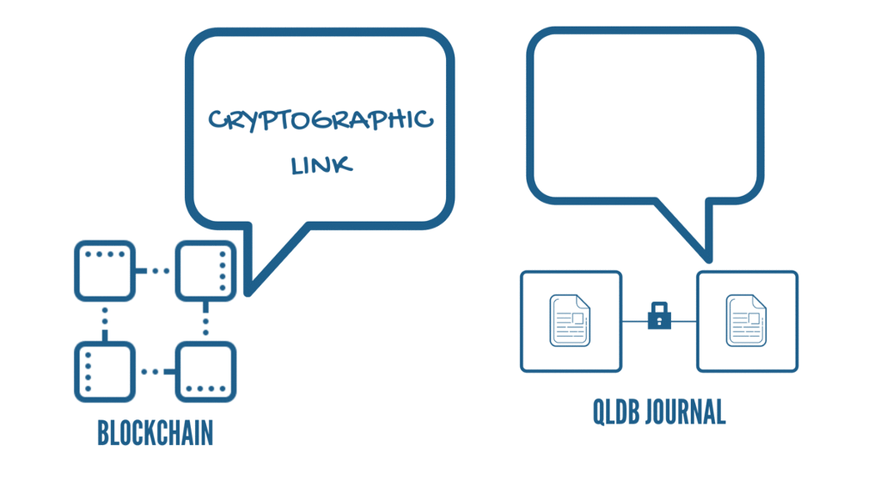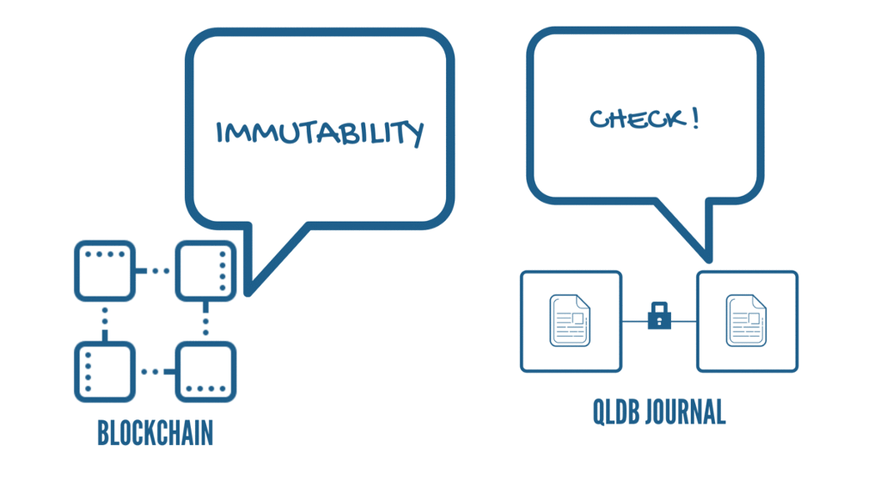
QLDB is a purpose-built database that provides a transparent, immutable, and cryptographically verifiable transaction log that helps you track all the changes that happen to the application data.
Wait a minute! What about blockchains? They pretty much do the exact same thing and ain’t nobody praising them, right? Well, the thing about blockchains is that it is decentralized and suits best when there are multiple parties involved in your use case. QLDB is for centralized applications. It is owned and operated by centralized authorities. It provides DLT-like functionalities, without the hassle of setting up a multi-node Network or The need for a consensus mechanism.
Ledger Database, The First.

If you were paying attention, you must have figured out by now that QLDB is, in fact, a database. Not just any ordinary database, it is a ledger database, The first of its kind. What is a ledger database you might ask, well, according to its creators, it is “ A NoSQL database that provides an immutable, transparent and cryptographically verifiable transaction log owned by a central authority.” Simply put, A Document-oriented database with blockchain-esque features owned by a single entity.
Let’s try to understand the inner workings of this blockchain-esque database!
How It All Unfolds!
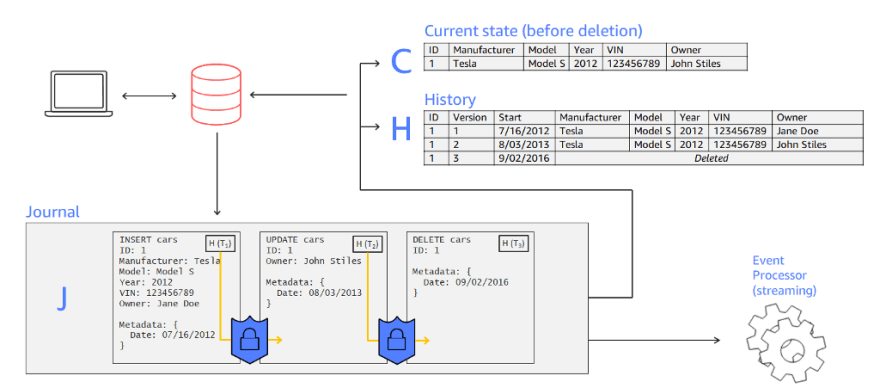
Suppose I use QLDB to track data. In QLDB, we use tables of documents to organize the data. No, it is not your typical “relational DB” tables. You see, In this document-oriented database, you don’t just store the latest revision (or version) of your document. Here, you get to keep the entire set of document revisions (A “revision” represents a single iteration of a document’s full dataset). That’s right, in QLDB, A Table is a collection of document revisions. Each of these iterations will have a unique ID and a version number.

Now, Before I start creating tables, I need to create an instance of the database. In QLDB lore, this is called a Ledger. Inside the ledger, I get to build my very own tables, and inside these tables, I can store the documents. Now, these are Amazon ION documents(sort of a buffed-up version of JSON)

So, to be clear, I have my data stored as an ION document and placed inside a table, and the table is part of a ledger.

Perfect. Now let’s change the data.
As with many traditional databases, We can change the application data using a database transaction. I can build an application that submits these transactions to the ledger. Most databases keep a log of such transactions. These logs can help recreate Transactions and retrieve data if and when something goes wrong.

Usually, these logs are not immutable, and the users have a hard time accessing these data. In QLDB, however, these logs take center stage. One of the core components of QLDB is a little something called a Journal. It is similar to a transaction log, and its purpose is to store a complete and provable history of all the data changes. It is sort of like a blockchain sitting inside the DB. I Mean, The similarities are staggering when you think about it. As with a blockchain, the journal is an append-only, immutable structure that records the transaction details. It stores the data in units called Blocks, and these blocks create a “cryptographic link” with the adjacent blocks by storing the hash value(SHA 256) of its previous block.
Each Ledger Will have a single journal. The blocks inside the journal include the statements that were used to commit a revision(CRUD statements), objects representing the committed document revisions, and other metadata. We use partiQL, a SQL compatible query language, to write the statements. For a single transaction, QLDB can write one or more chained blocks to the Journal.
So, every transaction that I make gets sequentially recorded in this tamper-proof Journal.
Now, the reason I called it a core component is because QLDB follows what is called a “ journal first” approach.
In this approach, every transaction is initially committed to the Journal. QLDB uses the data from the Journal to determine the state of the data by materializing the transactional data into the tables.

To put all this into perspective, consider a game of chess. You might have noticed how the players make a move by changing the position of the pieces on the board and how they record those moves in a notepad.

Well, in the “journal first” approach, the players would have to write the moves in the note first, verify it, and then, based on their writings, make the appropriate changes in the state of the board.
Now all this sounds fancy, but what if I want to access the current state of my data. Well, the obvious method would be to traverse through all the transactions in the Journal, applying each of them to my initial document and figuring out the whole thing on my own. Well, that’s no fun, especially if there are thousands of transactions involved.

That’s where the view comes in. A “view” makes life so much simpler. “ a view, in QLDB, is a projection of the data in a table. ” Think of it as a virtual table that contains tailored information from a table. You see, a view helps hide the complexities and intricacies of the data in the table by providing focused and simple subsets of it.

QLDB gives us inbuilt views of the Tables. QLDB uses transactional information to formulate the view, and they facilitate high-performance querying. Now, the following are the views that are generated by QLDB, these views help users query information using simple partiQL statements.
The user view , which essentially gives you the current state of your data, and
The committed view , which contains the latest revision of your data along with the system generated metadata( document ID, revision number, and things like that).
You can also get the complete history of a particular document by using the history function. The function returns the revision details from the committed view.
In Conclusion….
So QLDB is a ledger database that helps me track the changes to my application data. To make The changes to the data, I use transactions. QLDB initially stores the Transactions in a journal and uses the Journal to determine the state of the data. QLDB also gives me various views, which lets me quickly access the required information. Well, and Good.
The use cases of QLDB include finance data management, resource, and logistics management, insurance, etc. You see the pattern, don’t you? All these fields dearly value data lineage. So, if you have such a use case in mind, do consider QLDB.
So there you have it folks, a brief overview of Quantum Ledger Database.
For More Detailed Explanations, Do check out the following Links :
P.S. “Quantum” in QLDB is a nod to the atomic changes to the data and has no association with that super-fast computation thing.





Top comments (0)