Introduction to DataOps

What is DataOps?
DataOps is the orchestration of people, processes, and technology to deliver trusted, business-ready data to data citizens, operations, and applications throughout the data lifecycle. With properly governed data, businesses can comply with complex regulations, data privacy and ensure artificial intelligence (AI) model accuracy by monitoring data quality.
This is the definition available on the web. It’s very complex for beginners, isn't it? So to put it in a brief:
- DataOps brings together data scientists, analysts, developers, and operations to work on the entire product/service lifecycle, from the design stage to production support.
- Sounds like the DevOps definition...But! the goal of DataOps is to make data analytics more efficient. To do so, DataOps adopts Agile Development principles, thereby improving the efficiency and effectiveness of the data teams and users.
- DataOps combines principles from DevOps, Agile Development, and Lean manufacturing. Think of it as a water pipeline; your goal is to keep the water flowing in spite of all the plumbing work you carry out.
And here comes two new concepts/topics Lean Manufacturing and Agile Development. Let's see one by one:
What is Lean Manufacturing?
- Lean manufacturing is a production process based on an ideology of maximising productivity while simultaneously minimising waste within a manufacturing operation. The lean principle sees waste is anything that doesn’t add value that the customers are willing to pay for.
- Manufacturing happens in pipelines—raw materials flow through various manufacturing workstations to be transformed into finished goods.
What is Agile?
Let us say Mr. X is a developer. So, one day Bart(Client) comes to Mr. X and said:
Bart: Hi Mr. X! I want an application for the DOK community.
Mr. X: Definitely Bart! What are the features that you would like to see in the application?
Bart: Yeah! The primary feature is it has to collect all the comments from all socials of dok community.
Mr.X: Fine! I will start working on your application.
After a year… He delivers the project in one go.
Mr.X: Hi Bart! Your application is ready.
Bart: Yeah well, Why don’t you add another feature like collect all comments and filter the most common comments.
This would be frustrating. Because developing software may take months or years.
But what if happened like this. While Mr.X is doing his application Bart may call or email him that I want this so and so feature.
So this is where agile comes into play:

- Agile is a time-boxed, iterative approach to software delivery that builds software incrementally from the start of the project, instead of trying to deliver it all at once near the end.
- Scrum is a framework of rules, roles, events, and artifacts used to implement Agile projects. It is an iterative approach, consisting of sprints that typically only last one to four weeks. This approach ensures that your team delivers a version of the product regularly.
- A sprint in Scrum is a short period of time wherein a development team works to complete specific tasks, milestones, or deliverables. Sprints, also referred to as “iterations,” essentially break the project schedule into digestible blocks of time in which smaller goals can be accomplished.

- It works by breaking projects down into little bits of user functionality called user stories, prioritizing them, and then continuously delivering them in short two-week cycles called iterations.
- This means that data teams can publish new analytics in shorter increments, referred to as sprints, which significantly reduces wait times. Hence DataOps adopt an agile environment.
What are the challenges dataops trying to resolve?
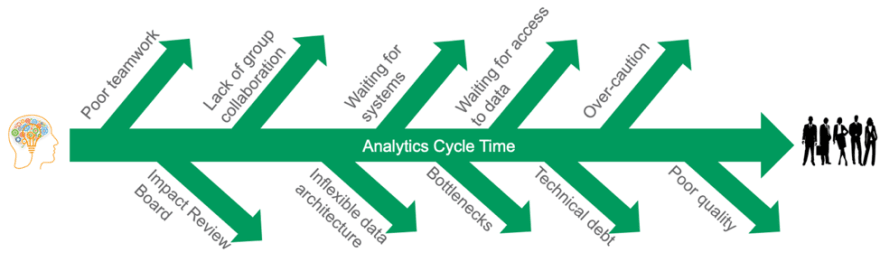
- The problem is that many organizations aren’t exactly clear on the most efficient approach to data collection and analytics. They often take a seemingly all-encompassing approach based on the principle of “we’ll collect the data and then figure out what to do with it,” that can do more harm than good.
- They then have a data team who is supposed to miraculously turn garbage into gold, which generally requires far more effort than necessary and rarely leads to the desired results. Of course, this makes it virtually impossible to deliver actionable insights on a schedule that can keep up with the demands of a DevOps team that’s pushing to get their code to market.
- DataOps takes this jumbled mess and turns it into a smooth process where data teams aren’t spending their time trying to fix problems. They aren’t wasting their time trying to turn poor raw data into something usable. Instead, they can focus on what matters, namely providing actionable insights.
- DataOps ensures that the raw data coming in is useable, it ensures that the results are accurate, it focuses on the value of people and working together, and it keeps the data team at the center of the company’s strategic objectives. After all, they no longer take months to come up with the required insights.
Now here comes the big question of how Kubernetes help DataOps. Before that let us know what is kubernetes in a nutshell.
Let’s say you created an application(e.g Pokemon go) and decided to share it with the world. How can you do that? by deploying it to the internet. So you deployed this application into 5 different servers using docker. And your application starts getting massive traffic even you are not imagined. Millions of users started using. You are happy on one side simultaneously you are sad because you have to scale up the servers because 5 are not enough for such massive traffic. Now you need to scale up fast and make sure all containers restart if they die. And you will be gone out of control.
This is where Kubernetes comes into play.
Kubernetes is an open-source container orchestration system for automating software deployment, scaling, and management.
- A Kubernetes cluster consists of a set of worker machines, called nodes, that run containerized applications.
- Development teams and data science teams are increasingly interested in moving their build-test and model training environments to Kubernetes in order to drive efficiency and avoid vendor lock-in. When they make this migration, it is absolutely necessary for them to be able to take their clone-based processes with them so that they don’t lose all of the lifecycle efficiencies that they have achieved over the years. In fact, the lack of ability to clone a volume to a different namespace is often a showstopper. It is considered a best practice for different developers to work in different namespaces. This is done for security reasons, and there is typically no compromising when it comes to security. If clones are going to be included in the development lifecycle, the ability to clone workspaces to different namespaces is vital.
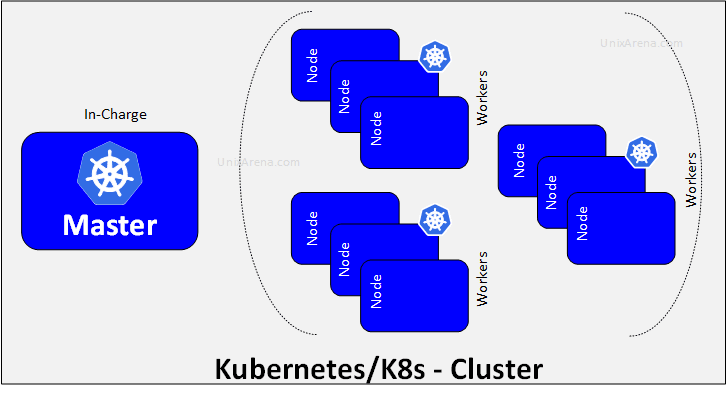
- Every cluster has at least one worker node. Hence if a node fails, your application will still be accessible from the other nodes as in a cluster, multiple nodes are grouped.
Why should you use Kubernetes for DataOps?
DataOps has many things in common that relate them to Kubernetes. It serve the same business goals as devops when it comes to speeding up application software development, deployment, and delivery. In a nutshell, the DataOps practices focus on improving application production through software development workflow optimization powered by data-driven insights.
Kubernetes follows the same principles being a powerful tool that provides a rock-solid technological ground for enhancements on both software and human levels. DataOps engineers can leverage the accuracy of massive data assets for their BigData analytics through robust data orchestration, timely updates, persistent data storage, and streamlined data pipelines across platforms and departments.
K8s is a portable, extensible, open-source platform for managing containerized workloads and services, that facilitates both declarative configuration and automation. It has a large, rapidly growing ecosystem. Kubernetes services, support, and tools are widely available.
The benefits Kubernetes brings to organizations in slightly more generic concepts. This is due to the fact that K8s can positively affect the workflows of various teams and departments at a time. What’s more, the benefits have an accumulative effect as you can capitalize on utilizing Kubernetes in the long run. Because of K8s open-source ecosystem.
> Service deployment and adjustment.
> Storage Alternatives.
> Self-healing.
> Automatic Selection.
> Recovery Mechanisms.
> Constant Monitoring. and many more...
Kubernetes environment is persistently becoming the leading platform for cloud computing. Consumers looking for dynamically-scheduled container-oriented DataOps solutions should consider Kubernetes-as-a-Service.
Just like Devops, DataOps is also a methdology it's not a tool.
Top DataOps Projects
- Genie
- Piper
- Airflow
- Naveego
- Delphix Delphix is the industry leader in Data Ops and provides an intelligent data platform that accelerates digital transformation for leading companies around the world. Uses kubernetes.
Finally...
There is no doubt that Kubernetes is a true game-changer in today's software development. The platform helps you boost the overall performance and productivity when it comes to efficiently managing containerized services and workloads. Not to mention its huge time- and cost-saving potential. With Kubernetes at your fingertips, you can drastically enhance the efficacy of your DevOps, DataOps, and GitOps workflows while creating automated CI/CD pipelines





Top comments (0)