
Intro
We currently don't have an API for Google Arts & Culture Artists page.
This blog post is written to show the DIY solution to extract data from "All, A-Z, Time" tabs that can be used for personal use while waiting for our proper solution.
The reason DIY solution can be used for personal use only is that it doesn't include the Legal US Shield that we offer for our paid production and above plans and has its limitations such as the need to bypass blocks, for example, CAPTCHA.
You can check our public roadmap to track the process for this API:
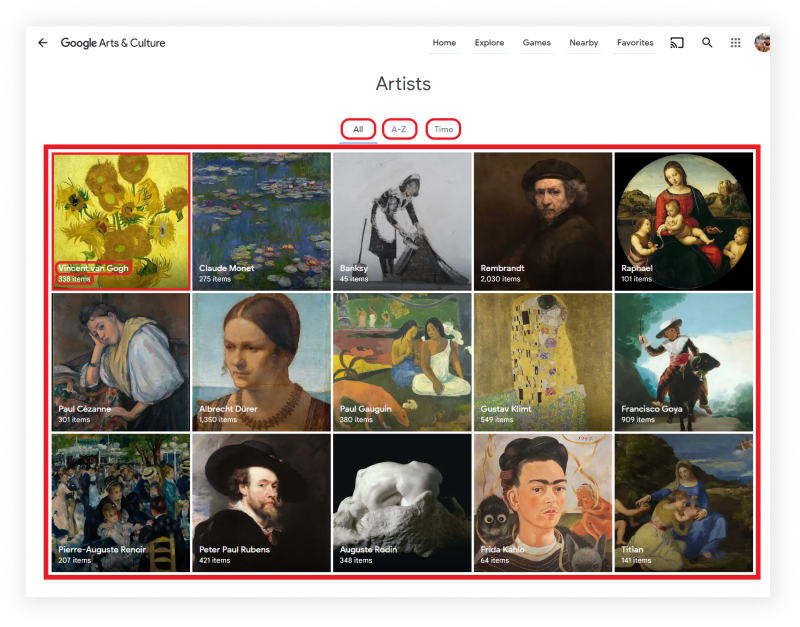
What will be scraped
Full Code
If you don't need explanation, have a look at full code example in the online IDE.
from bs4 import BeautifulSoup
import requests, json, re, lxml
# https://requests.readthedocs.io/en/latest/user/quickstart/#custom-headers
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/100.0.4896.60 Safari/537.36',
}
def get_pop_tab():
# https://requests.readthedocs.io/en/latest/user/quickstart/#passing-parameters-in-urls
params = {
'tab': 'pop'
}
html = requests.get(f'https://artsandculture.google.com/category/artist', params=params, headers=headers, timeout=30)
soup = BeautifulSoup(html.text, 'lxml')
all_script_tags = soup.select('script')
# https://regex101.com/r/JQXUBm/1
portion_of_script_tags = re.search('("stella\.common\.cobject",".*)\[\[\"A",\["stella\.pr","PrefixedAssets', str(all_script_tags)).group(1)
# https://regex101.com/r/c9m9B0/1
authors = re.findall(r'"stella\.common\.cobject","(.*?)","\d+', str(portion_of_script_tags))
# https://regex101.com/r/5YT5Yi/1
author_links = [f'https://artsandculture.google.com{link}' for link in re.findall('"(/entity.*?)"', str(portion_of_script_tags))]
# https://regex101.com/r/gQjInC/1
number_of_artworks = re.findall('"(\d+).*?items"', str(portion_of_script_tags))
# https://regex101.com/r/RHdj3K/1
thumbnails = [f'https:{image_link}' for image_link in re.findall('"(//.*?)"', str(portion_of_script_tags))]
tab_results = []
for author, author_link, num_artworks, thumbnail in zip(authors, author_links, number_of_artworks, thumbnails):
tab_results.append({
'author': author,
'author_link': author_link,
'number_of_artworks': int(num_artworks),
'thumbnail': thumbnail,
})
print(json.dumps(tab_results, indent=2, ensure_ascii=False))
def check_special_letter(first_letter, second_letter=None):
pattern = ''
if second_letter is None:
if first_letter == '-':
pattern = f'\["{first_letter}",\["stella\.pr","PrefixedAssets:[\w|-]*",\[\[("stella\.common\.cobject",".*)\[\["Far Past"'
elif first_letter == 'Z':
pattern = f'\["{first_letter}",\["stella\.pr","PrefixedAssets:[\w|-]*",\[\[("stella\.common\.cobject",".*)\["-"'
else:
pattern = f'\["{first_letter}",\["stella\.pr","PrefixedAssets:[\w|-]*",\[\[("stella\.common\.cobject",".*)\["{chr(ord(first_letter)+1)}"'
else:
if first_letter == '-':
pattern = f'\["{second_letter}",\["stella\.pr","PrefixedAssets:[\w|-]*",\[\[("stella\.common\.cobject",".*)\[\["Far Past"'
elif second_letter == 'Z':
pattern = f'\["{first_letter}",\["stella\.pr","PrefixedAssets:[\w|-]*",\[\[("stella\.common\.cobject",".*)\["-"'
else:
pattern = f'\["{first_letter}",\["stella\.pr","PrefixedAssets:[\w|-]*",\[\[("stella\.common\.cobject",".*)\["{chr(ord(second_letter)+1)}"'
return pattern
def get_az_tab(first_letter, second_letter=None):
first_letter = first_letter.upper()
second_letter = second_letter.upper() if second_letter is not None else None
# https://requests.readthedocs.io/en/latest/user/quickstart/#passing-parameters-in-urls
params = {
'tab': 'az',
'pr': first_letter
}
html = requests.get(f'https://artsandculture.google.com/category/artist', params=params, headers=headers, timeout=30)
soup = BeautifulSoup(html.text, 'lxml')
all_script_tags = soup.select('script')
pattern = ''
if second_letter:
if ord(first_letter) < ord(second_letter):
pattern = check_special_letter(first_letter, second_letter)
elif ord(first_letter) > ord(second_letter):
pattern = check_special_letter(second_letter, first_letter)
else:
pattern = check_special_letter(first_letter)
else:
pattern = check_special_letter(first_letter)
# https://regex101.com/r/SpK4ye/1
portion_of_script_tags = re.search(pattern, str(all_script_tags)).group(1)
# https://regex101.com/r/c9m9B0/1
authors = re.findall(r'"stella\.common\.cobject","(.*?)","\d+', str(portion_of_script_tags))
# https://regex101.com/r/5YT5Yi/1
author_links = [f'https://artsandculture.google.com{link}' for link in re.findall('"(/entity.*?)"', str(portion_of_script_tags))]
# https://regex101.com/r/gQjInC/1
number_of_artworks = re.findall('"(\d+).*?items"', str(portion_of_script_tags))
# https://regex101.com/r/RHdj3K/1
thumbnails = [f'https:{image_link}' for image_link in re.findall('"(//.*?)"', str(portion_of_script_tags))]
tab_results = []
for author, author_link, num_artworks, thumbnail in zip(authors, author_links, number_of_artworks, thumbnails):
tab_results.append({
'author': author,
'author_link': author_link,
'number_of_artworks': int(num_artworks),
'thumbnail': thumbnail,
})
print(json.dumps(tab_results, indent=2, ensure_ascii=False))
def get_time_tab(date=-25000):
# https://requests.readthedocs.io/en/latest/user/quickstart/#passing-parameters-in-urls
params = {
'tab': 'time',
'date': date
}
html = requests.get(f'https://artsandculture.google.com/category/artist', params=params, headers=headers, timeout=30)
soup = BeautifulSoup(html.text, 'lxml')
all_script_tags = soup.select('script')
# https://regex101.com/r/oOLk7X/1
portion_of_script_tags = re.search('\["stella\.pr","DatedAssets:.*",\[\["stella\.common\.cobject",(.*?)\[\]\]\]\;<\/script>', str(all_script_tags)).group(1)
# https://regex101.com/r/c9m9B0/1
authors = re.findall(r'"stella\.common\.cobject","(.*?)","\d+', str(portion_of_script_tags))
# https://regex101.com/r/5YT5Yi/1
author_links = [f'https://artsandculture.google.com{link}' for link in re.findall('"(/entity.*?)"', str(portion_of_script_tags))]
# https://regex101.com/r/gQjInC/1
number_of_artworks = re.findall('"(\d+).*?items"', str(portion_of_script_tags))
# https://regex101.com/r/RHdj3K/1
thumbnails = [f'https:{image_link}' for image_link in re.findall('"(//.*?)"', str(portion_of_script_tags))]
tab_results = []
for author, author_link, num_artworks, thumbnail in zip(authors, author_links, number_of_artworks, thumbnails):
tab_results.append({
'author': author,
'author_link': author_link,
'number_of_artworks': int(num_artworks),
'thumbnail': thumbnail,
})
print(json.dumps(tab_results, indent=2, ensure_ascii=False))
Preparation
Install libraries:
pip install requests bs4 lxml
Basic knowledge scraping with CSS selectors
CSS selectors declare which part of the markup a style applies to thus allowing to extract data from matching tags and attributes.
If you haven't scraped with CSS selectors, there's a dedicated blog post of mine
about how to use CSS selectors when web-scraping that covers what it is, pros and cons, and why they matter from a web-scraping perspective.
Reduce the chance of being blocked
Make sure you're using request headers user-agent to act as a "real" user visit. Because default requests user-agent is python-requests and websites understand that it's most likely a script that sends a request. Check what's your user-agent.
There's a how to reduce the chance of being blocked while web scraping blog post that can get you familiar with basic and more advanced approaches.
Code Explanation
Import libraries:
from bs4 import BeautifulSoup
import requests, json, re, lxml
| Library | Purpose |
|---|---|
BeautifulSoup |
is a Python library for pulling data out of HTML and XML files. It works with your favorite parser to provide idiomatic ways of navigating, searching, and modifying the parse tree. |
requests |
to make a request to the website. |
json |
to convert extracted data to a JSON object. |
re |
to extract parts of the data via regular expression. |
lxml |
to process XML/HTML documents fast. |
You need to define the parameters. Functions have their own parameters, but each function has a tab parameter which is responsible for the tab to display:
| Tab | Explanation |
|---|---|
pop |
to show all arts. |
az |
to show arts by letter. |
time |
to show arts by time. |
"All" tab

First, you need to access the page by URL. To do this, we will use the get function from the requests library. The Beautiful Soup library is one of the best-suited tools for extracting data. Usage example is given below:
html = requests.get(f'https://artsandculture.google.com/category/artist', params=params, headers=headers, timeout=30)
soup = BeautifulSoup(html.text, 'lxml')
The data on this site is retrieved in a non-standard way. To access this data, you need to view the page code (Ctrl+U) and find (Ctrl+F) the script tag that contains the necessary data.
In this case, I was trying to find Vincent van Gogh's occurrences in the script tags, which will indicate that we can extract data from there:
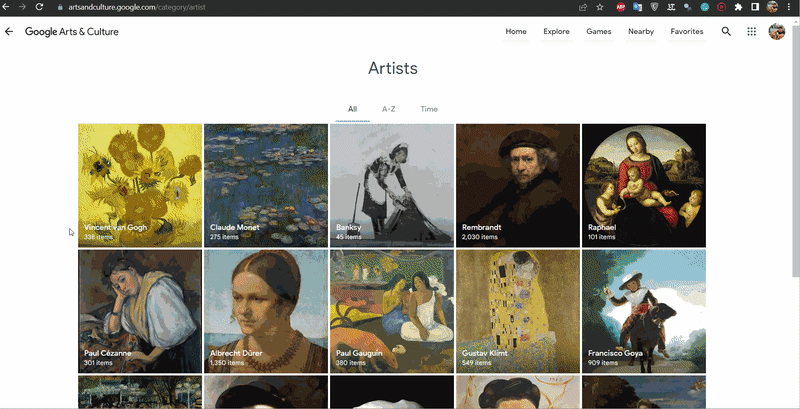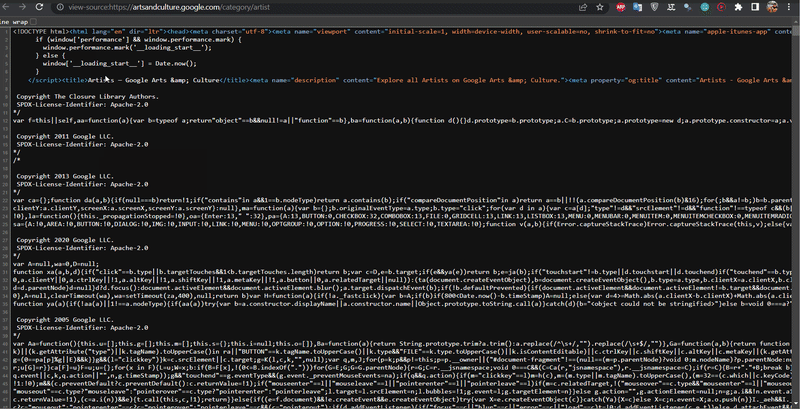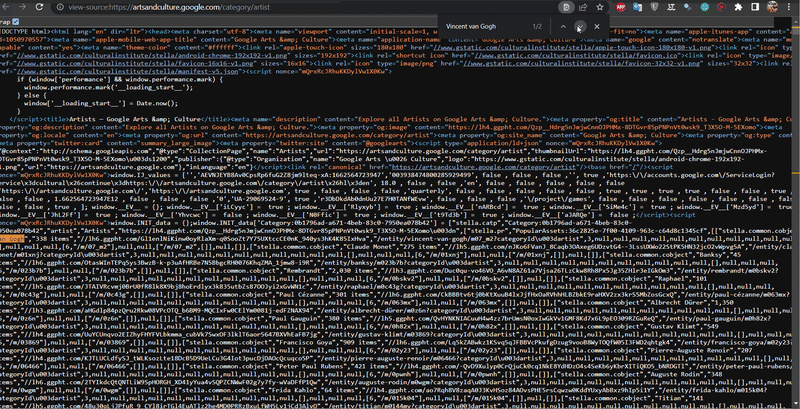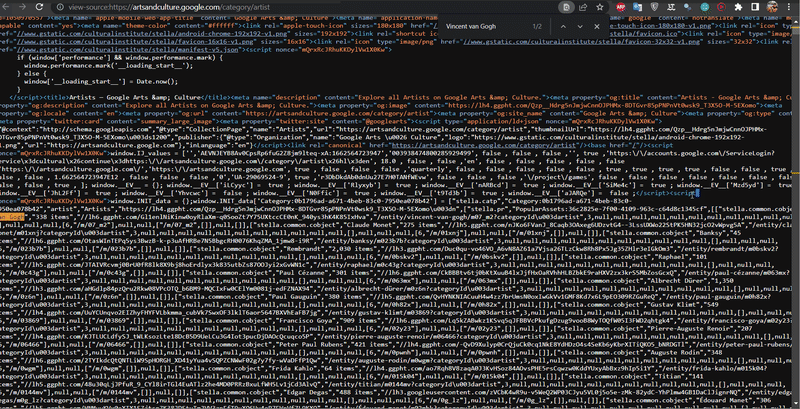
The necessary data is in the script tags, so you need to find all script tags:
all_script_tags = soup.select('script')
I want to draw your attention to the fact that all_script_tags contain data from all tabs. Therefore, to work correctly, each function will use the portion_of_script_tags piece of the all_script_tags, which is responsible for a specific tab.
Using regular expressions you can extract the portion_of_script_tags:
# https://regex101.com/r/JQXUBm/1
portion_of_script_tags = re.search('("stella\.common\.cobject",".*)\[\[\"A",\["stella\.pr","PrefixedAssets', str(all_script_tags)).group(1)
Data such as authors, authors links, number of arts and thumbnails are also extracted using regular expressions and written to the appropriate lists as follows:
# https://regex101.com/r/c9m9B0/1
authors = re.findall(r'"stella\.common\.cobject","(.*?)","\d+', str(portion_of_script_tags))
# https://regex101.com/r/5YT5Yi/1
author_links = [f'https://artsandculture.google.com{link}' for link in re.findall('"(/entity.*?)"', str(portion_of_script_tags))]
# https://regex101.com/r/gQjInC/1
number_of_artworks = re.findall('"(\d+).*?items"', str(portion_of_script_tags))
# https://regex101.com/r/RHdj3K/1
thumbnails = [f'https:{image_link}' for image_link in re.findall('"(//.*?)"', str(portion_of_script_tags))]
At the moment there are 4 lists and they need to be used simultaneously in one cycle. To do this, we use the zip built-in function. The tab_results list contains all information about the tab. At the end of the function, this data is printed in JSON format using the dumps function:
tab_results = []
for author, author_link, num_artworks, thumbnail in zip(authors, author_links, number_of_artworks, thumbnails):
tab_results.append({
'author': author,
'author_link': author_link,
'number_of_artworks': int(num_artworks),
'thumbnail': thumbnail,
})
print(json.dumps(tab_results, indent=2, ensure_ascii=False))
The function looks like this:
def get_pop_tab():
# https://requests.readthedocs.io/en/latest/user/quickstart/#passing-parameters-in-urls
params = {
'tab': 'pop'
}
html = requests.get(f'https://artsandculture.google.com/category/artist', params=params, headers=headers, timeout=30)
soup = BeautifulSoup(html.text, 'lxml')
all_script_tags = soup.select('script')
# https://regex101.com/r/JQXUBm/1
portion_of_script_tags = re.search('("stella\.common\.cobject",".*)\[\[\"A",\["stella\.pr","PrefixedAssets', str(all_script_tags)).group(1)
# https://regex101.com/r/c9m9B0/1
authors = re.findall(r'"stella\.common\.cobject","(.*?)","\d+', str(portion_of_script_tags))
# https://regex101.com/r/5YT5Yi/1
author_links = [f'https://artsandculture.google.com{link}' for link in re.findall('"(/entity.*?)"', str(portion_of_script_tags))]
# https://regex101.com/r/gQjInC/1
number_of_artworks = re.findall('"(\d+).*?items"', str(portion_of_script_tags))
# https://regex101.com/r/RHdj3K/1
thumbnails = [f'https:{image_link}' for image_link in re.findall('"(//.*?)"', str(portion_of_script_tags))]
tab_results = []
for author, author_link, num_artworks, thumbnail in zip(authors, author_links, number_of_artworks, thumbnails):
tab_results.append({
'author': author,
'author_link': author_link,
'number_of_artworks': int(num_artworks),
'thumbnail': thumbnail,
})
print(json.dumps(tab_results, indent=2, ensure_ascii=False))
| Code | Explanation |
|---|---|
text |
to get only text information inside selected selector. |
select() |
to run a CSS selector against a parsed document and return all the matching elements. |
search() |
to search for a pattern in a string and return the corresponding match object. |
group() |
to extract the found element from the match object. |
findall() |
to return all non-overlapping matches of pattern in string, as a list of strings. |
tab_results.append({}) |
to append extracted data to a list as a dictionary. |
Output for get_pop_tab():
[
{
"author": "Vincent van Gogh",
"author_link": "https://artsandculture.google.com/entity/vincent-van-gogh/m07_m2?categoryId\\u003dartist",
"number_of_artworks": 338,
"thumbnail": "https://lh6.ggpht.com/Gl1enlNiKinw0oyRlaXm-q0SooZt7Y75UXtccCE0nK_940ys3hK4K85IxHva"
},
{
"author": "Claude Monet",
"author_link": "https://artsandculture.google.com/entity/claude-monet/m01xnj?categoryId\\u003dartist",
"number_of_artworks": 275,
"thumbnail": "https://lh5.ggpht.com/nJKo6FVanJ_8Caqb3OAxeg6UDzvtG4--3LssUXWo22StPK5HN32jcO2vWpvg5A"
},
{
"author": "Banksy",
"author_link": "https://artsandculture.google.com/entity/banksy/m023b7b?categoryId\\u003dartist",
"number_of_artworks": 45,
"thumbnail": "https://lh6.ggpht.com/OtasWInTEPq5ys3BwzB-k-p3uAfHRBe7N5BbgcRH0076KhqZMA_1jmw8-i9R"
},
... other results
]
"A-Z" tab
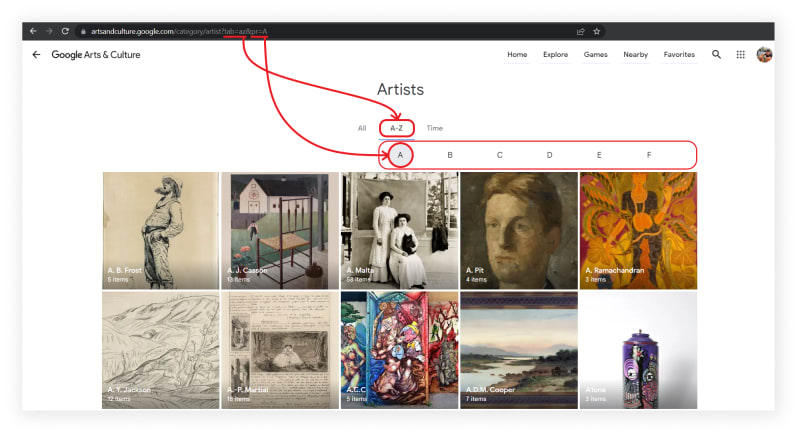
📌Note: This is where the pr parameter appears, which is unique to this function. The arts are displayed according to the letter that was passed to the pr parameter.
The function takes two parameters:
| Parameters | Explanation |
|---|---|
first_letter |
required parameter to search by passed letter. |
second_letter |
optional parameter, to search from the first_letter to the second_letter inclusive. |
From the non-obvious, it can be noted that the search can also be carried out using special characters (numbers, hieroglyphs, signs, etc.). For such issuance, it is necessary to pass - to the function.
At the beginning of the function, it is necessary to convert the given letters to upper case, if possible.
first_letter = first_letter.upper()
second_letter = second_letter.upper() if second_letter is not None else None
These 2 parameters are needed to create the correct pattern for extracting the portion_of_script_tags that contains the necessary data. Below is an algorithm for creating a pattern:
pattern = ''
if second_letter:
if ord(first_letter) < ord(second_letter):
pattern = check_special_letter(first_letter, second_letter)
elif ord(first_letter) > ord(second_letter):
pattern = check_special_letter(second_letter, first_letter)
else:
pattern = check_special_letter(first_letter)
else:
pattern = check_special_letter(first_letter)
# https://regex101.com/r/SpK4ye/1
portion_of_script_tags = re.search(pattern, str(all_script_tags)).group(1)
The check_special_letter function was created to avoid repeating the same piece of code multiple times (DRY).
def check_special_letter(first_letter, second_letter=None):
pattern = ''
if second_letter is None:
if first_letter == '-':
pattern = f'\["{first_letter}",\["stella\.pr","PrefixedAssets:[\w|-]*",\[\[("stella\.common\.cobject",".*)\[\["Far Past"'
elif first_letter == 'Z':
pattern = f'\["{first_letter}",\["stella\.pr","PrefixedAssets:[\w|-]*",\[\[("stella\.common\.cobject",".*)\["-"'
else:
pattern = f'\["{first_letter}",\["stella\.pr","PrefixedAssets:[\w|-]*",\[\[("stella\.common\.cobject",".*)\["{chr(ord(first_letter)+1)}"'
else:
if first_letter == '-':
pattern = f'\["{second_letter}",\["stella\.pr","PrefixedAssets:[\w|-]*",\[\[("stella\.common\.cobject",".*)\[\["Far Past"'
elif second_letter == 'Z':
pattern = f'\["{first_letter}",\["stella\.pr","PrefixedAssets:[\w|-]*",\[\[("stella\.common\.cobject",".*)\["-"'
else:
pattern = f'\["{first_letter}",\["stella\.pr","PrefixedAssets:[\w|-]*",\[\[("stella\.common\.cobject",".*)\["{chr(ord(second_letter)+1)}"'
return pattern
| Code | Explanation |
|---|---|
ord() |
to convert the character to its integer value. |
chr() |
to convert the integer value to the character. |
The rest of the get_az_tab function is similar to the get_pop_tab function described in the previous heading.
This function looks like this:
def get_az_tab(first_letter, second_letter=None):
first_letter = first_letter.upper()
second_letter = second_letter.upper() if second_letter is not None else None
# https://requests.readthedocs.io/en/latest/user/quickstart/#passing-parameters-in-urls
params = {
'tab': 'az',
'pr': first_letter
}
html = requests.get(f'https://artsandculture.google.com/category/artist', params=params, headers=headers, timeout=30)
soup = BeautifulSoup(html.text, 'lxml')
all_script_tags = soup.select('script')
pattern = ''
if second_letter:
if ord(first_letter) < ord(second_letter):
pattern = check_special_letter(first_letter, second_letter)
elif ord(first_letter) > ord(second_letter):
pattern = check_special_letter(second_letter, first_letter)
else:
pattern = check_special_letter(first_letter)
else:
pattern = check_special_letter(first_letter)
# https://regex101.com/r/SpK4ye/1
portion_of_script_tags = re.search(pattern, str(all_script_tags)).group(1)
# https://regex101.com/r/c9m9B0/1
authors = re.findall(r'"stella\.common\.cobject","(.*?)","\d+', str(portion_of_script_tags))
# https://regex101.com/r/5YT5Yi/1
author_links = [f'https://artsandculture.google.com{link}' for link in re.findall('"(/entity.*?)"', str(portion_of_script_tags))]
# https://regex101.com/r/gQjInC/1
number_of_artworks = re.findall('"(\d+).*?items"', str(portion_of_script_tags))
# https://regex101.com/r/RHdj3K/1
thumbnails = [f'https:{image_link}' for image_link in re.findall('"(//.*?)"', str(portion_of_script_tags))]
tab_results = []
for author, author_link, num_artworks, thumbnail in zip(authors, author_links, number_of_artworks, thumbnails):
tab_results.append({
'author': author,
'author_link': author_link,
'number_of_artworks': int(num_artworks),
'thumbnail': thumbnail,
})
print(json.dumps(tab_results, indent=2, ensure_ascii=False))
Output for get_az_tab('A'):
[
{
"author": "A. B. Frost",
"author_link": "https://artsandculture.google.com/entity/a-b-frost/m06b7cg?categoryId\\u003dartist",
"number_of_artworks": 5,
"thumbnail": "https://lh3.ggpht.com/Lfwsu29qks8oAArsSnIrMYXCyAW1eJHSs_zRtV87_kuGOj31LZfabjT14QEg4g"
},
{
"author": "A. J. Casson",
"author_link": "https://artsandculture.google.com/entity/a-j-casson/m0695mj?categoryId\\u003dartist",
"number_of_artworks": 13,
"thumbnail": "https://lh3.googleusercontent.com/oPxgz35wxodv8998Nsarup0c78_gOey6FoR9BS2oHm303-g3F_I3yrjD9GooE8IQ5-k"
},
{
"author": "A. Malta",
"author_link": "https://artsandculture.google.com/entity/a-malta/g122w1grb?categoryId\\u003dartist",
"number_of_artworks": 58,
"thumbnail": "https://lh3.ggpht.com/a7jTpf9IBH7fjBD4h8cCLvJw-w44Q_kkzdTR2kWj6W5tb68qnth5_9BS"
},
... other results
]
"Time" tab
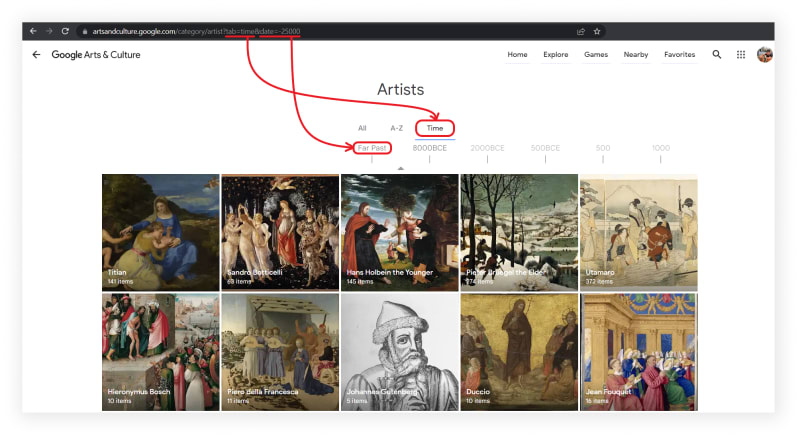
📌Note: The data parameter, unique to this function. The arts are displayed according to the time that was passed to the data parameter.
In the image above, you may have noticed that the site has a carousel of proposed dates. The user can pass any date, even not included in the proposed ones. In this case, the closest date to the proposed date will be automatically selected. Also, if the user does not pass a date to the function, then the latest date from the proposed ones will be selected.
The only difference between this function and the previous ones is that this function will use its own portion_of_script_tags that is responsible for this tab:
# https://regex101.com/r/oOLk7X/1
portion_of_script_tags = re.search('\["stella\.pr","DatedAssets:.*",\[\["stella\.common\.cobject",(.*?)\[\]\]\]\;<\/script>', str(all_script_tags)).group(1)
The complete function looks like this:
def get_time_tab(date=-25000):
# https://requests.readthedocs.io/en/latest/user/quickstart/#passing-parameters-in-urls
params = {
'tab': 'time',
'date': date
}
html = requests.get(f'https://artsandculture.google.com/category/artist', params=params, headers=headers, timeout=30)
soup = BeautifulSoup(html.text, 'lxml')
all_script_tags = soup.select('script')
# https://regex101.com/r/oOLk7X/1
portion_of_script_tags = re.search('\["stella\.pr","DatedAssets:.*",\[\["stella\.common\.cobject",(.*?)\[\]\]\]\;<\/script>', str(all_script_tags)).group(1)
# https://regex101.com/r/c9m9B0/1
authors = re.findall(r'"stella\.common\.cobject","(.*?)","\d+', str(portion_of_script_tags))
# https://regex101.com/r/5YT5Yi/1
author_links = [f'https://artsandculture.google.com{link}' for link in re.findall('"(/entity.*?)"', str(portion_of_script_tags))]
# https://regex101.com/r/gQjInC/1
number_of_artworks = re.findall('"(\d+).*?items"', str(portion_of_script_tags))
# https://regex101.com/r/RHdj3K/1
thumbnails = [f'https:{image_link}' for image_link in re.findall('"(//.*?)"', str(portion_of_script_tags))]
tab_results = []
for author, author_link, num_artworks, thumbnail in zip(authors, author_links, number_of_artworks, thumbnails):
tab_results.append({
'author': author,
'author_link': author_link,
'number_of_artworks': int(num_artworks),
'thumbnail': thumbnail,
})
print(json.dumps(tab_results, indent=2, ensure_ascii=False))
Output for get_time_tab():
[
{
"author": "Titian",
"author_link": "https://artsandculture.google.com/entity/titian/m0144mv?categoryId\\u003dartist",
"number_of_artworks": 141,
"thumbnail": "https://lh5.ggpht.com/48u30qLjJPfuR_9_CYl8irTGl4EuATlz2he4MD0PRRzBxuLfWH5Lv1jCd3AlvQ"
},
{
"author": "Sandro Botticelli",
"author_link": "https://artsandculture.google.com/entity/sandro-botticelli/m0jr3g?categoryId\\u003dartist",
"number_of_artworks": 63,
"thumbnail": "https://lh6.ggpht.com/Wj-a9mBHNGEXLBrCiquE2MLOBi3pmaPOODrV975f_06CMtha2pM0t3iE5aA"
},
{
"author": "Hans Holbein the Younger",
"author_link": "https://artsandculture.google.com/entity/hans-holbein-the-younger/m0cy9m?categoryId\\u003dartist",
"number_of_artworks": 145,
"thumbnail": "https://lh3.ggpht.com/s47W743jWHKcUvTDwmrqy2eq2dNOqRa4gZ_wSpkIoIjfx5OqwTDNP-hw6rH2"
},
... other results
]
Add a Feature Request💫 or a Bug🐞





Top comments (0)