Domain Driven Design for Highly Scalable applications
Domain driven design (DDD), is the perfect tool to reduce complexity for software development. Other advantages include a ubiquitous language across business and technical people and a clear separation between business sub-domains.
DDD makes it easier for software to match the business needs and for developers to collaborate closely with domain experts.
As a result, the technical team will not feel like fighting against the features rejection and requirements changes from the stakeholders. Instead, speaking the same language, they will work together and make software a competitive advantage for the business.
In this article, I am going to discuss DDD, focussing on the aspects that can be leveraged to achieve high scalability.
Example domain
Let's use an auction sales application as an example for our business domain.
In our domain, a user can, raise auctions for an item she wants to sell and define a deadline. She might also set a direct buy price. The other users will then make their offers by increasing the auction until the countdown reaches zero, or someone makes the direct purchase. In order to be able to make an offer, the user must first fund his account with the required amount.
To apply DDD we will do the following steps:
- We will start by separating the example domain in bounded contexts.
- We will then focus on one of the contexts to design its aggregates, focussing on scalability without sacrificing business constraints and scalability.
- Finally, we will discuss domain events, as a way to keep everything that happens to our domain.
Bounded contexts
The first step to an effective domain design is strategic design. It consists of simplifying the business model complexity by decomposing it into bounded contexts that can be handled separately.
Bounded contexts are sets of highly related business activities, along with the concepts that they manipulate.
One way to separate bounded contexts is to put unrelated activities in separate contexts. Our bounded contexts must be decoupled, as tightly coupled contexts will limit the ability of the team to build, deploy and scale the related software components separately.
For example, the payment service focuses on user account funding and withdrawal, and doesn't care about how auctions are raised.
The delivery service, on the other hand, only tracks the item delivery from the seller to the buyer, without knowledge of the selling process.
Our core domain is the auctions, and we will focus on it in the rest of this paper, but also discuss the integration with the other contexts as necessary.
So we can define three bounded contexts as follows:
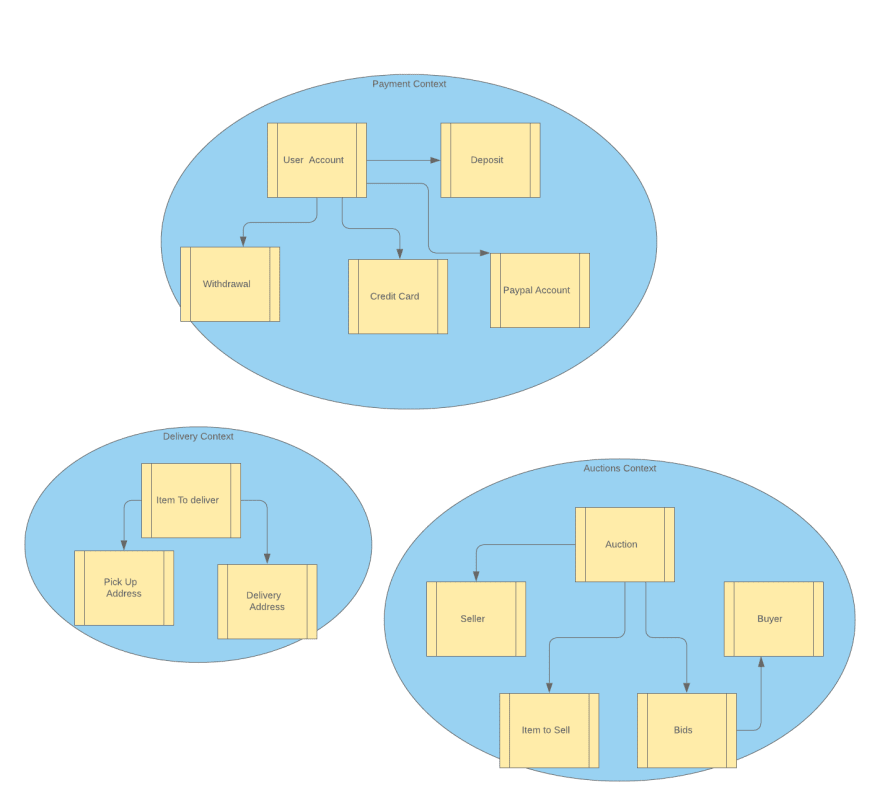
The most important thing to understand here is the separation of bounded contexts.
Aggregates
Good aggregates design is the key for a highly scalable domain model. We can think of aggregates as individual actors in the system, handling atomic operations. By atomic I mean operations that either complete successfully with all induced state changes saved durably, or fails with no change applied to state.
Aggregates should be addressed by their identifiers, that way they can be easily shared across many instances of the underlying database to achieve linear scalability.
But how do we make sure the state of an aggregate is consistent with the rest of the system? For example, how do we make sure that the offer of a user matches his available balance? The answer to this questions is eventual consistency. That is, we will design our operations in such a way that they can be reverted if consequent transactions on other aggregates fail. This way, the system will not be consistent at the time an operation is applied to a given aggregate, but subsequent operations will move it, eventually, to a consistent state.
The most common way of implementing the eventual consistency is by applying the Saga Pattern, that we will discuss in a subsequent article.
An aggregate is a set of business entities, and the entry point of each aggregate is called the aggregate root. For example, we can consider the following as an aggregate:
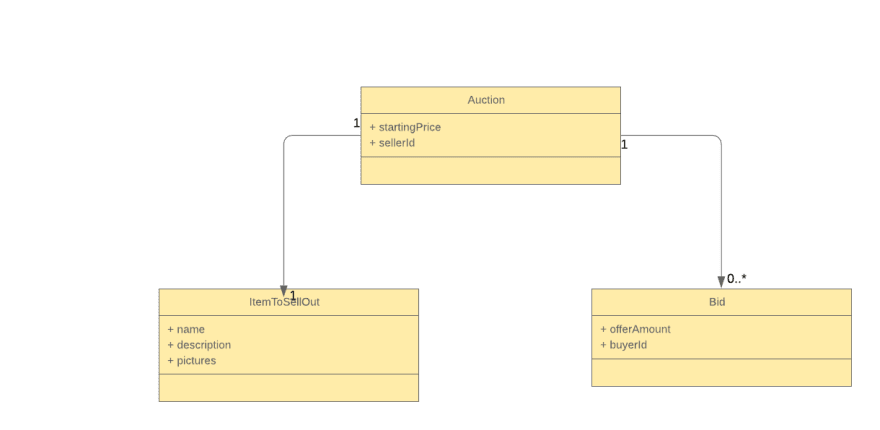
Aggregates should refer to other aggregates by their identifiers. In the above diagram, the seller is referenced using the “sellerId” attribute of the Auction while the buyer is referenced using the “buyerId”.
One consideration to take into account when designing your aggregates is their side. Aggregates should bet small, they should not be allowed to grow indefinitely. Otherwise they might be heavy to load in memory, and thus seriously harm the performance of the operations. \
Coming back to our above example, if an auction receives millions of offers, then it will have a huge memory footprint. No matter which persistent solution you use, the storage and retrieval of your aggregate will perform worse as most users make bids.
One way to fix this issue could be to limit the number of offers an auction can consider. But will the business accept this? I guess no. We should accept as many offers as possible.
The other solution is to make a separate aggregate for the Bid. But the bids are immutatbles. Once created, they are not modified. The user can just make another offer. So it doesn’t make sense to consider a bid as an aggregate by itself.
The third solution (and the best one for this case) is to keep only the best offer, as new bids are accepted only if they are better than the current best offer. So let us change the diagram (only the cardinality between Auction and Bid changes here)
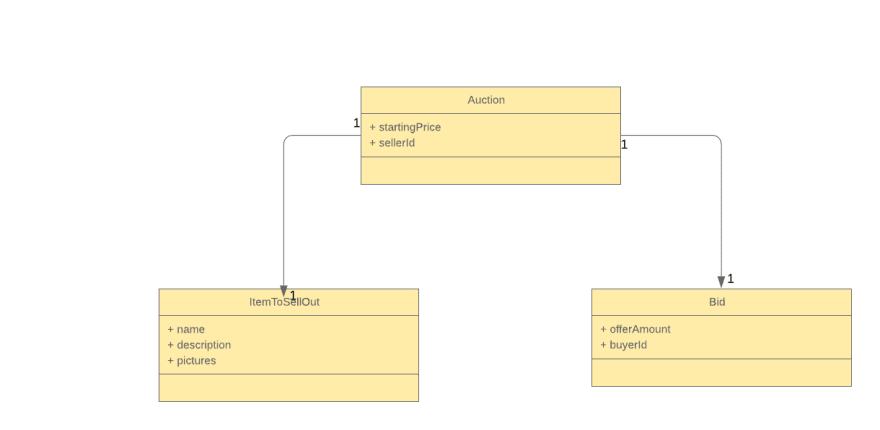
Domain Events
So you might be asking: Are we losing the older bids as we replace them with higher offers? What if we want to reason about all the offers to a given auction later? For example, we might want to report the total count of bids for a given auction.
This is where domain events enter into play. We need only the current aggregate state to make a decision (whether we accept a bid for example), but we will keep everything that happened to the aggregate as domain events. That way, we could introduce any kind of reports or views of the data later, just by replaying the events.
In our example domain model, we will store an “Auction Created” event every time a new auction is started, “Offer Placed” event for each bid and “Auction Closed” event at the end of the auction.

Storing domain events can be cumbersome if you use a relational database schema. Fortunately, we have tools and techniques that can make this more easier for us. In an upcoming article, I will discuss Event Sourcing and how to leverage it to achieve high scalability.
Domain events should also be used to create or update other aggregates. The other bounded contexts might be interested by the changes that happens to our aggregates, and we should notify them by publishing domain events.

For example, when an auction is closed, the Auctions Context should publish an “Auction Closed” event, that is consumed by the Delivery Context to initiate the item delivery process.
In an upcoming article discussing event sourcing and CQRS, we will also cover how domain events can be used to update the read side database.
Summary
In this article we discussed how to design an application targeting high scalability. We introduced important concepts of domain driven design, including Bounded Contexts, Aggregates and Domain Events, and explained how they should be applied to make our application scalable. We also introduced a practical example, an online auctions application.
In upcoming an article, I will introduce event sourcing and CQRS, and how we can use them to implement our domain model.




Top comments (0)