
What is the AWS Lambda Execution Context?
When your Lambda function gets called, Lambda will then invoke your function in an execution environment, which is an isolated runtime environment. The execution context is a temporary runtime environment that initializes any external dependencies of your lambda code. As your lambda function can be invoke numerous times and scale the execution context is maintained for some time in anticipation of another Lambda function invocation. When that happens it can "reuse" the context to execution time which will save time on your function. The execution context includes a /tmp directory, that provides 512mb of temporary storage for your functions.
What can it be used for?
There are a number of things the execution context can be used for but some great use cases for example is database connection, HTTP clients, SDK clients, etc...
Best practice to not put any connections for example inside your handler, because that will mean that every time your function gets invoked, it will create a new database connection, which will cause problems in the future. You want to be able to create that database connection outside of your handler and then just use that connection within the handler of your Lambda function.
Do not initialize your Database connections like this:
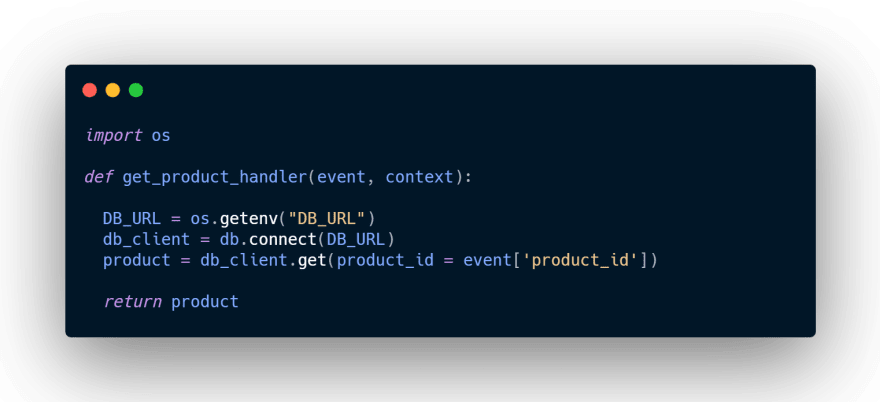
This will cause a new connection to your DB every time your function gets invoked.
Rather create your function as follows:

This is best practice and your Lambda function can now reuse the database connection in your handler, without the need to recreating the database connection if your function gets invoked multiple times in a short period.
/tmp space:
When you need to work with a big file inside of your Lambda function, you can use the /tmp space to temporarily save the file to use, if it's not bigger than 512MB. When the execution context is frozen, the directory content remains, which is helpful for multiple invocations. If you need more permanent objects that will not temporarily be used, then rather use something like AWS S3 for persistence of the object.





Top comments (1)
Hi Admin/Anybody,
Can you confirm whether or not this topic is out of date?
I may be wrong, but can you give me a source that proves your point, which is provided/discussed on this web site?
Every time I google on this topic, I get this URL docs.aws.amazon.com/lambda/latest/... (which has nothing to do with this topic)
For reference, see this document docs.aws.amazon.com/AmazonRDS/late...
From the above point in the RDS console itself, we can connect to Lambda.
Lambda side code: