
Find pyinfer on Github : https://github.com/cdpierse/pyinfer
Docs for the package can be found here: https://pyinfer.readthedocs.io/en/latest/
Introduction
When developing machine learning models initial efforts are often put on measuring metrics that reflect how well a model performs for a given task.
This step is of course crucially important but when moving a model to production other factors come into play that are equally important and can make or break a model’s success in the wild. One of these additional factors is how many inferences (or calls) per second a single model is capable of performing.
For example, let’s say we are building a computer vision model for collision detection; this model is intended to integrate into an autonomous driving system and we have 3 candidate models. While it is of course important that all of these models perform well at the task of detecting collisions it is also very important that they detect those collisions in a very specific and tight time frame. The choice of model in this situation cannot be made solely on its ability to predict a collision correctly. In fact, the model that ends up getting chosen in this situation might well under perform the other candidates in accuracy but outshine them when it comes to the number of inferences per second it can perform.
The above example is an extreme one but the idea is applicable across many problems. Retail store searches, text autocomplete, Netlfix film recommendations etc. All of these situations likely have a minimum requirement when it comes to model inferences.
That is why I have developed pyinfer a very lightweight but hopefully useful tool for ML developers and researchers.
Example: Choosing A Transformer Model
The example below shows the MultiInferenceReport class from pyinfer being used to benchmark and compare three models from the popular Huggingface library. Each of these models uses variations of the Transformer architecture and achieve different scores on accuracy based benchmarks. They also have differing numbers of parameters which is huge indicator for how long each model is going to take run a single inference.
We are comparing three models' from the library:
- Bert
- Distilbert
- Electra
Each model is finetuned to perform sentiment analysis on a piece of text.
We instantiate each model and its associated tokenizer and create a text input for each model to be run on.
With the model and text input we are now ready to create and run the report, and see what is output.
Multi Inference Report Table Output

Multi Inference Report Run Times Plot
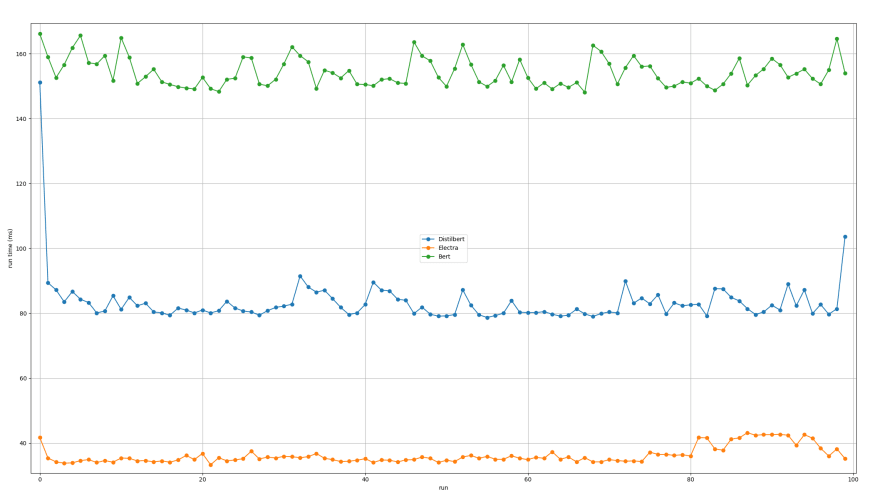
From the above results we can see that in terms of inferences per second the Electra model is the clear winner, followed by Distilbert, and finally good old Bert. This makes sense when we look at general parameterization of the three models. Using the information given by the report decisions can be made on choosing which model is suitable for production and which are not.
Pyinfer's Features
- Simple to use interface.
- Ability to compare any number of models against one another.
- Works with any callable model, method, or even a complex function.
- Option to run the report for n_iterations or n_seconds depending on what is more practical.
- Users can set a predefined inference failure point in seconds/ms which will mark any inference above that point as failure in the report.
- A visually appealing table that reports inference statistics is printed to console upon completion of the report. These stats are also returned as a list of dictionaries.
- Run times can be plotted against each other on a graph for quick visual comparison.
- The package is well tested
Installation
Pyinfer is on pypi you can install via:
pip install pyinfer
Summary
Pyinfer is a lightweight tool for ML developers and researchers to benchmark the inference statistics for a model or number of models they are testing out. It allows developers to make decisions about a model’s practical suitability for production with a simple to use interface.
You can find the project on github.
If anyone would like to make a contribution to the project or suggest a change/feature I’d love to hear about it.





Top comments (2)
Very nice article, Charles.
Well done!!!
Thanks Thiago!