
Written by Piero Borrelli✏️
A good start is half the battle, said someone wiser than me. And I can’t think of any quote that would better describe the situation every developer gets into whenever starting a new project. Laying out a project’s structure in a practical way is one of the hardest points of the development process and, indeed, a delicate one.
By looking at the previous articles I have written here on LogRocket, we can define a path about discussing Node.js technologies, how to choose what front-end framework to use, and now we can try to dig deeper on how to structure our web apps once we have decided on the tech stack to use.
The importance of good architecture
Having a good starting point when it comes to our project architecture is vital for the life of the project itself and how you will be able to tackle changing needs in the future. A bad, messy project architecture often leads to:
- Unreadable and messy code , making the development process longer and the product itself harder to test
- Useless repetition , making code harder to maintain and manage
- Difficulty implementing new features. Since the structure can become a total mess, adding a new feature without messing up existing code can become a real problem
With these points in mind, we can all agree that our project architecture is extremely important, and we can also declare a few points that can help us determine what this architecture must help us do:
- Achieve clean and readable code
- Achieve reusable pieces of code across our application
- Help us to avoid repetitions
- Make life easier when adding a new feature into our application

Establishing a flow
Now we can discuss what I usually refer to as the application structure flow. The application structure flow is a set of rules and common practices to adopt while developing our applications. These are the results of years of experience working with a technology and understanding what works properly and what doesn’t.
The goal of this article is to create a quick reference guide to establishing the perfect flow structure when developing Node.js applications. Let’s start to define our rules:
Rule #1: Correctly organize our files into folders
Everything has to have its place in our application, and a folder is the perfect place to group common elements. In particular, we want to define a very important separation, which brings us to rule number #2:
Rule #2: Keep a clear separation between the business logic and the API routes
See, frameworks like Express.js are amazing. They provide us with incredible features for managing requests, views, and routes. With such support, it might be tempting for us to put our business logic into our API routes. But this will quickly make them into giant, monolithic blocks that will reveal themselves to be unmanageable, hard to read, and prone to decomposition.
Please also don’t forget about how the testability of our application will decrease, with consequently longer development times. At this point, you might be wondering, “How do we solve this problem, then? Where can I put my business logic in a clear and intelligent way?” The answer is revealed in rule number #3.
Rule #3: Use a service layer
This is the place where all our business logic should live. It’s basically a collection of classes, each with its methods, that will be implementing our app’s core logic. The only part you should ignore in this layer is the one that accesses the database; that should be managed by the data access layer.
Now that we have defined these three initial rules, we can graphically represent the result like this:

And the subsequent folder structure sending us back to rule #1 can then become:

By looking at this last image, we can also establish two other rules when thinking about our structure.
Rule #4: Use a config folder for configuration files
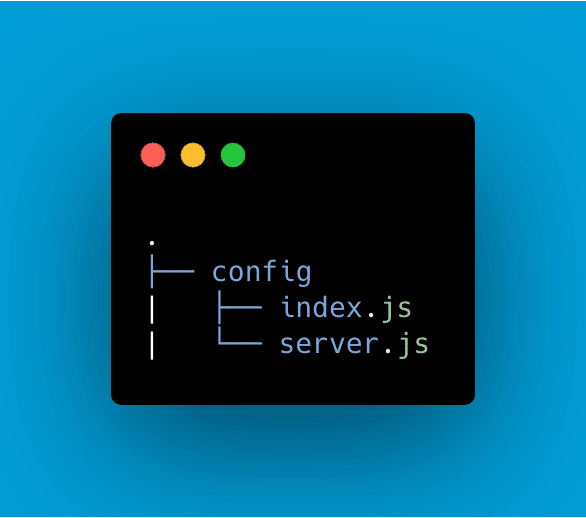
Rule #5: Have a scripts folder for long npm scripts

Rule #6: Use dependency injection
Node.js is literally packed with amazing features and tools to make our lives easier. However, as we know, working with dependencies can be quite troublesome most of the time due to problems that can arise with testability and code manageability.
There is a solution for that, and it’s called dependency injection.
Dependency injection is a software design pattern in which one or more dependencies (or services) are injected, or passed by reference, into a dependent object.
By using this inside our Node applications, we:
- Have an easier unit testing process , passing dependencies directly to the modules we would like to use instead of hardcoding them
- Avoid useless modules coupling , making maintenance much easier
- Provide a faster git flow. After we defined our interfaces, they will stay like that, so we can avoid any merge conflicts.
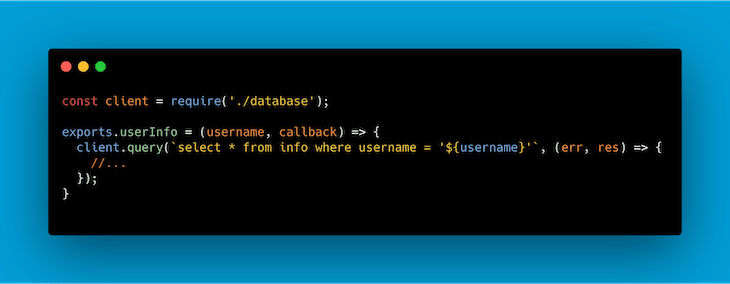
Simple but still not very flexible as an approach to our code. What happens if we want to alter this test to use an example database? We should alter our code to adapt it to this new need. Why not pass the database directly as a dependency instead?
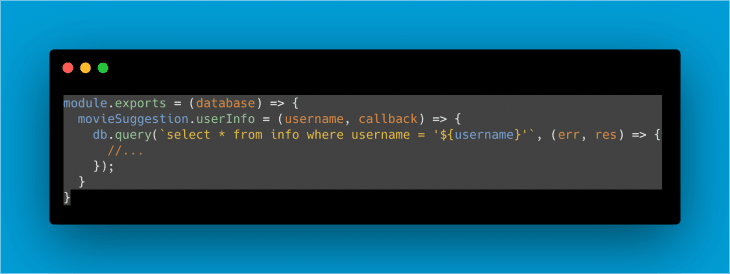
Rule #7: Use unit testing
Now that we know we have got dependency injection under our belt, we can also implement unit testing for our project. Testing is an incredibly important stage in developing our applications. The whole flow of the project — not just the final result — depends on it since buggy code would slow down the development process and cause other problems.
A common way to test our applications is to test them by units, the goal of which is to isolate a section of code and verify its correctness. When it comes to procedural programming, a unit may be an individual function or procedure. This process is usually performed by the developers who write the code.
Benefits of this approach include:
Improved code quality
Unit testing improves the quality of your code, helping you to identify problems you might have missed before the code goes on to other stages of development. It will expose the edge cases and makes you write better overall code
Bugs are found earlier
Issues here are found at a very early stage. Since the tests are going to be performed by the developer who wrote the code, bugs will be found earlier, and you will be able to avoid the extremely time-consuming process of debugging
Cost reduction
Fewer flaws in the application means less time spent debugging it, and less time spent debugging it means less money spent on the project. Time here is an especially critical factor since this precious unit can now be allocated to develop new features for our product
Rule #8: Use another layer for third-party services calls
Often, in our application, we may want to call a third-party service to retrieve certain data or perform some operations. And still, very often, if we don’t separate this call into another specific layer, we might run into an out-of-control piece of code that has become too big to manage.
A common way to solve this problem is to use the pub/sub pattern. This mechanism is a messaging pattern where we have entities sending messages called publishers, and entities receiving them called subscribers.
Publishers won’t program the messages to be sent directly to specific receivers. Instead, they will categorize published messages into specific classes without knowledge of which subscribers, if any, may be dealing with them.
In a similar way, the subscribers will express interest in dealing with one or more classes and only receive messages that are of interest to them — all without knowledge of which publishers are out there.
The publish-subscribe model enables event-driven architectures and asynchronous parallel processing while improving performance, reliability, and scalability.
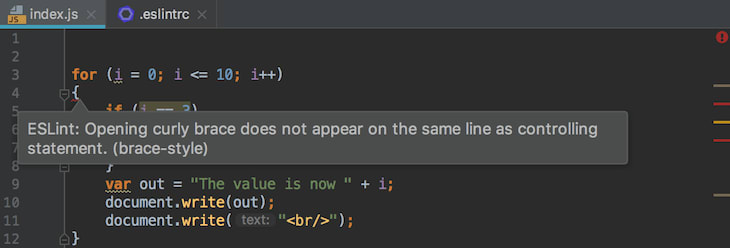
Rule #9: Use a linter
This simple tool will help you to perform a faster and overall better development process, helping you to keep an eye on small errors while keeping the entire application code uniform.
Rule #10: Use a style guide
Still thinking about how to properly format your code in a consistent way? Why not adapt one of the amazing style guides that Google or Airbnb have provided to us? Reading code will become incredibly easier, and you won’t get frustrated trying to understand how to correctly position that curly brace.

Rule #11: Always comment your code
Writing a difficult piece of code where it’s difficult to understand what you are doing and, most of all, why? Never forget to comment it. This will become extremely useful for your fellow developers and to your future self, all of whom will be wondering why exactly you did something six months after you first wrote it.
Rule #12: Keep an eye on your file sizes
Files that are too long are extremely hard to manage and maintain. Always keep an eye on your file length, and if they become too long, try to split them into modules packed in a folder as files that are related together.
Rule #13: Always use gzip compression
The server can use gzip compression to reduce file sizes before sending them to a web browser. This will reduce latency and lag.

Rule #14: Use promises
Using callbacks is the simplest possible mechanism for handling your asynchronous code in JavaScript. However, raw callbacks often sacrifice the application control flow, error handling, and semantics that were so familiar to us when using synchronous code. A solution for that is using promises in Node.js.
Promises bring in more pros than cons by making our code easier to read and test while still providing functional programming semantics together with a better error-handling platform.

Rule #15: Use promises’ error handling support
Finding yourself in a situation where you have an unexpected error or behavior in your app is not at all pleasant, I can guarantee. Errors are impossible to avoid when writing our code. That’s simply part of being human.
Dealing with them is our responsibility, and we should always not only use promises in our applications, but also make use of their error handling support provided by the catch keyword.

Conclusion
Creating a Node.js application can be challenging, I hope this set of rules helped you to put yourself in the right direction when establishing what type of architecture you are going to use, and what practices are going to support that architecture.
For more content like this, follow my Twitter and my blog.
Editor's note: Seeing something wrong with this post? You can find the correct version here.
Plug: LogRocket, a DVR for web apps

LogRocket is a frontend logging tool that lets you replay problems as if they happened in your own browser. Instead of guessing why errors happen, or asking users for screenshots and log dumps, LogRocket lets you replay the session to quickly understand what went wrong. It works perfectly with any app, regardless of framework, and has plugins to log additional context from Redux, Vuex, and @ngrx/store.
In addition to logging Redux actions and state, LogRocket records console logs, JavaScript errors, stacktraces, network requests/responses with headers + bodies, browser metadata, and custom logs. It also instruments the DOM to record the HTML and CSS on the page, recreating pixel-perfect videos of even the most complex single-page apps.
Try it for free.
The post The perfect architecture flow for your next Node.js project appeared first on LogRocket Blog.





Top comments (21)
"Use promises" is a bit 2015 kind of advice. Async / await is widely adopted and it is a step ahead of Promises.
That's like saying you won't be using promises with async/await.
It's just a different way of consuming them.
Exactly, I use promises exactly to get my async function to await for a second function to finish. They are different things
+1 for Rule #8: Use another layer for third-party services calls
I worked at 3 startups all involved with online payment, all switched from one payment processor (Stripe, Adyen, and whatnot) to another for a better rate or more features, mostly for a better rate. After going through the painful refactoring for the first 2, I realised I should've written a wrapper around whatever payment processor npm/API I would use
Yes but you have to create a unified API. Thankfully this should be easier for payment processors than for writing a unified DB access layer that would allow switching from MySQL to MongoDB.
Hey Brian,
Thanks for the great article. Any sample repo's to checkout?
Thanks,
Lionel
dev.to/faustrata1/nodejs-boilerpla...
i'm interesting for this deal.
What do you mean?
Good writing, but I'd not use
expressfor any kind of project.If you want a real stack use something like Adonis or Nest which have been built to create application/api at scale.
By default, NestJs uses Express under the hood, so at least having good knowledge in Express, for me, may help in understanding and using NestJs for large scale apps.
As for AdonisJs, it looks very promising, since it is similar to Laravel for PHP. Having used Laravel in my last project, I think I can get started relatively quickly with AdonisJs. I just want to be convinced that this framework is really reliable, because I don't know, I always feel hesitant about it.
Rule #6 has some buggy code. database is specified for the arrow function param but db is being called
You noticed too? Well, we all get the gist tho 😉
Do you have some project as boilerplate where I can follow these valuable rules?
If yes,do you mind to share it?
Thanks for your post!
Congrats.
I'd like to point of Rule #13.
The problem when use compression library you may have lot of CPU usage. The good approach for this use case is using a reverse proxy, like ngnix.
Your article is interesting for beginners. CLI provided by frameworks (Vuejs, Angular, express) are generating scaffolds to learn from! It's a good starting point to follow.
Thanks!
Wonder if you have more examples on how to execute the piece of code about DI from a caller perspective. Thanks, great post.
Thank you for this post! this was very helpful 🌻
I'm always amazed at how under-architected most node code is.
I really liked the functional approach of the dependency injection