November 25th, 2022 - Instalment #137
Welcome
Welcome to the AWS open source newsletter, edition #137. As it is re:Invent next week, I will be publishing the newsletter early as I am heading out on Monday. I will be in Las Vegas talking with open source Builders, hanging out on the Open Source Kiosk in the AWS Village, and doing some talks. If you are coming, I would love to meet some of you, so get in touch. I will also be taking a break for a week, so the next newsletter will be on December 12th.
As always, this week we have more new projects for you to practice your four freedoms on, including a couple of projects for those who are looking to perhaps stand up their own Mastadon instances. "aws-vpc-flowlogs-enricher" is a project to help you add additional data into your VPC Flow logs, "aws-security-assessment-solution" a solution that uses some open source security tools that you can use to assess your AWS accounts, "aws-backup-amplify-appsync" a tool for all AWS Amplify users need to know about, "message-bus-bridge" is a tool to help you copy messages between message bus', "monitor-serverless-datalake" keep on top of your data lakes with this solution, "ec2-image-builder-send-approval-notifications-before-sharing-ami" shows you how you can add a notification step in the AMI building workflow, "amazon-ecs-fargate-cdk-v2-cicd" is a nice demonstration on using AWS CDKv2 with Flask, "deploy-nth-to-eks" a tool for Kubernetes admins, and a few more projects too!
With the run up to re:Invent, the AWS Amplify team have been on fire, and we have lots of content for AWS Amplify users and fans. We also have content covering your favourite open source projects, including GraphQL, Grafana, Prometheus, MariaDB, PostgreSQL, Flutter, React, Apache Iceberg, Apache Airflow, Apache Flink, Apache ShardingSphere, AutoGluon, AWS ParallelCluster, Kubeflow, NGINX, Finch, Amazon EMR, Trino, Apache Hudi, O3DE, Apache Kafka, OpenSearch, MLFlow, and more.
Finally, with re:Invent upon us, make sure you check the events section for everything you need to know to make sure you do not miss the best open source sessions.
AWS Copilot - have your say
The AWS Copilot project has created a new design proposal for overriding Copilot abstracted resources using the AWS Cloud Development Kit (CDK). The goal is to provide a "break the glass" mechanism to access and configure functionality that is not surfaced by Copilot manifests by leveraging the expressive power of a programming language. Have your say by heading over to Extending Copilot with the CDK and joining the discussion.
Feedback
Please let me know how we can improve this newsletter as well as how AWS can better work with open source projects and technologies by completing this very short survey that will take you probably less than 30 seconds to complete. Thank you so much!
Celebrating open source contributors
The articles and projects shared in this newsletter are only possible thanks to the many contributors in open source. I would like to shout out and thank those folks who really do power open source and enable us all to learn and build on top of what they have created.
So thank you to the following open source heroes: John Preston, Andreas Wittig, Michael Wittig, Uma Ramadoss, Boni Bruno, Eric Henderson, Chelluru Vidyadhar, Vijay Karumajji, Justin Lim, Krishna Sarabu, Chirag Dave, and Mark Townsend
Latest open source projects
The great thing about open source projects is that you can review the source code. If you like the look of these projects, make sure you that take a look at the code, and if it is useful to you, get in touch with the maintainer to provide feedback, suggestions or even submit a contribution.
Tools
aws-sam-cli-pipeline-init-templates
aws-sam-cli-pipeline-init-templates This repository contains the pipeline init templates used in the AWS SAM CLI for sam pipeline commands. Customers can now incrementally add services to their repository and automate the creation and execution of pipelines for each new #serverless service. The template creates the necessary supporting infrastructure to keep track of commit history and changes that occur in your directories, so only the modified service pipeline is triggered. Get started by simply choosing option 2 when you initialise and bootstrap and new pipeline.
aws-security-assessment-solution
aws-security-assessment-solution Cybersecurity remains a very important topic and point of concern for many CIOs, CISOs, and their customers. To meet these important concerns, AWS has developed a primary set of services customers should use to aid in protecting their accounts. Amazon GuardDuty, AWS Security Hub, AWS Config, and AWS Well-Architected reviews help customers maintain a strong security posture over their AWS accounts. As more organizations deploy to the cloud, especially if they are doing so quickly, and they have not yet implemented the recommended AWS Services, there may be a need to conduct a rapid security assessment of the cloud environment. With that in mind, we have worked to develop an inexpensive, easy to deploy, secure, and fast solution to provide our customers two (2) security assessment reports. These security assessments are from the open source projects “Prowler” and “ScoutSuite.” Each of these projects conduct an assessment based on AWS best practices and can help quickly identify any potential risk areas in a customer’s deployed environment.
aws-backup-amplify-appsync
aws-backup-amplify-appsync AWS Amplify makes it easy to build full stack front end UI apps with backends and authentication. AWS AppSync adds serverless GraphQL and DynamoDB tables to your application with no code. This project guides you on how to include the infrastructure as code to add AWS Backup to an Amplify and AppSync application using to manage snapshots for your applications DynamoDB tables.

monitor-serverless-datalake
monitor-serverless-datalake This repository serves as a launch pad for monitoring serverless data lakes in AWS. The objective is to provide a plug and play mechanism for monitoring enterprise scale data lakes. Data lakes starts small and rapidly explodes with adoption. With growing adoption, the data pipelines also grows in number and complexity. It is pivotal to ensure that the data pipeline executes as per SLA and failures be mitigated. The solution provides mechanisms for the following, 1. Capture state changes across all tasks in the data lake 2. Quickly notify operations of failures as they happen 3. Measure service reliability across data lake – to identify opportunities for performance optimisation

message-bus-bridge
message-bus-bridge is a relatively simple service that transfers messages between two different message buses. It was built for the purpose of providing users of WebSocket API services to have a quick and easy way to provide connectivity to their existing MQ bus systems without having to re-code to a WebSocket API. Effectively, it will listen to any message coming from the MQ bus and send it over to the WebSocket API, and vice-versa. While the service in this incarnation implements MQ to WebSockets, the code is modular so that the respective bus handling code can be swapped out for another bus, such as JMS or Kafka.
aws-vpc-flowlogs-enricher
aws-vpc-flowlogs-enricher This repo contains a sample lambda function code that can be used in Kinesis Firehose stream to enrich VPC Flow Log record with additional metadata like resource tags for source and destination IP addresses and, VPC ID, Subnet ID, Interface ID, AZ for destination IP addresses. This data then can be used to identify flows for specific tags, or Source AZ to destination AZ traffic and many more scenarios.

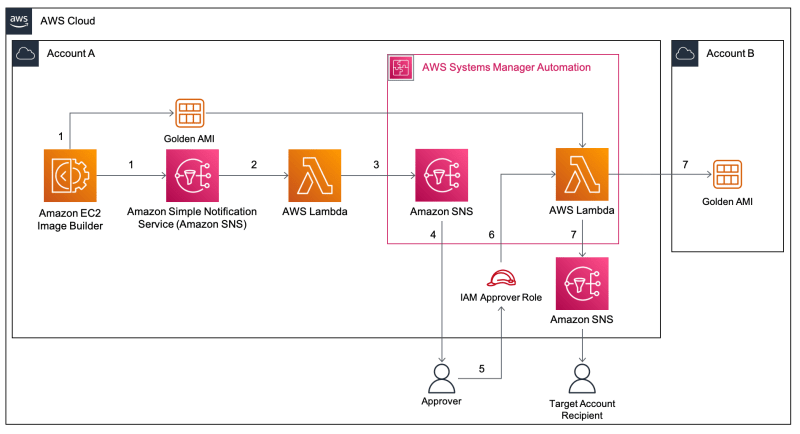
ec2-image-builder-send-approval-notifications-before-sharing-ami
ec2-image-builder-send-approval-notifications-before-sharing-ami You may be required to manually validate the Amazon Machine Image (AMI) built from an Amazon Elastic Compute Cloud (Amazon EC2) Image Builder pipeline before sharing this AMI to other AWS accounts or to an AWS organization. Currently, Image Builder provides an end-to-end pipeline that automatically shares AMIs after they’ve been built. This repo provides code and documentation to help you build a solution to enable approval notifications before AMIs are shared with other AWS accounts.
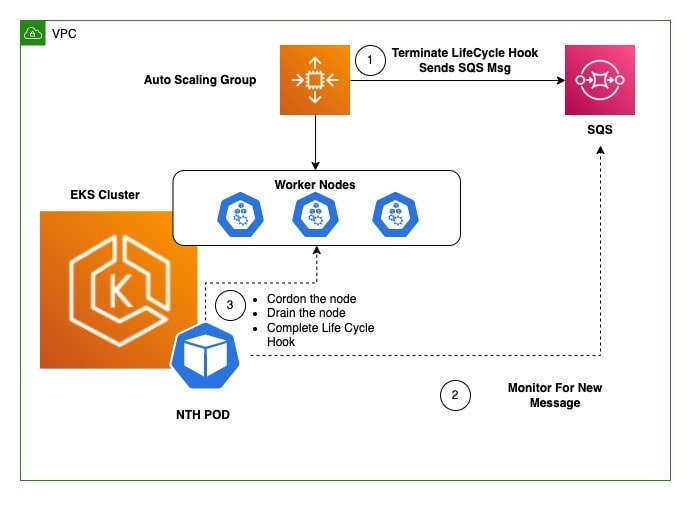
deploy-nth-to-eks
deploy-nth-to-eks AWS Node Termination Handler (nth) ensures that the Kubernetes control plane responds appropriately to events that can cause your EC2 instance to become unavailable, such as EC2 maintenance events, EC2 Spot interruptions, ASG Scale-In, ASG AZ Rebalance, and EC2 Instance Termination via the API or Console. If not handled, your application code may not stop gracefully, take longer to recover full availability, or accidentally schedule work to nodes that are going down.The aws-node-termination-handler (NTH) can operate in two different modes: Instance Metadata Service (IMDS) or the Queue Processor. The aws-node-termination-handler Instance Metadata Service Monitor will run a small pod on each host to perform monitoring of IMDS paths like /spot or /events and react accordingly to drain and/or cordon the corresponding node. The aws-node-termination-handler Queue Processor will monitor an SQS queue of events from Amazon EventBridge for ASG lifecycle events, EC2 status change events, Spot Interruption Termination Notice events, and Spot Rebalance Recommendation events. When NTH detects an instance is going down, we use the Kubernetes API to cordon the node to ensure no new work is scheduled there, then drain it, removing any existing work. The termination handler Queue Processor requires AWS IAM permissions to monitor and manage the SQS queue and to query the EC2 API. This pattern will automate the deployment of Node Termination Handler using Queue Processor through CICD Pipeline.
Demos, Samples, Solutions and Workshops
custom-provider-with-terraform-plugin-framework
custom-provider-with-terraform-plugin-framework This repository contains a complete implementation of a custom provider built using HashiCorp's latest SDK called Terraform plugin framework. It is used to teach, educate, and show the internals of a provider built with the latest SDK from HashiCorp. Even if you are not looking to learn how to build custom providers, you may dial your troubleshooting skills to an expert level if you learn how one works behind the scenes. Plus, this provider is lots of fun to play with. The provider is called buildonaws and it allows you to maintain characters from comic books such as heros, super-heros, and villains.
mastodon-on-aws
mastodon-on-aws Andreas Wittig and Michael Wittig share details of how you can host your own Mastodon instance on AWS. They have also put together this blog post, Mastodon on AWS: Host your own instance which you can read for more info.

mastodon-aws-architecture
mastodon-aws-architecture this repo provides details on how snapp.social Mastadon instance is being run on AWS, and as more and more people explore whether this options is right for them, take a look and see how they have architected and deployed this on AWS.
amazon-ecs-fargate-cdk-v2-cicd
amazon-ecs-fargate-cdk-v2-cicd This project builds a complete sample containerised Flask application publicly available on AWS, using Fargate, ECS, CodeBuild, and CodePipline to produce a fully functional pipeline to continuously roll out changes to your new app.
ROSConDemo
ROSConDemo this repo contains code for a working robotic fruit picking demo project for O3DE with ROS 2 Gem.

o3de-demo-project


AWS and Community blog posts
Finch
Phil Estes and Chris Short put together this post, Introducing Finch: An Open Source Client for Container Development to announce a new open source project, Finch. Finch is a new command line client for building, running, and publishing Linux containers. It provides for simple installation of a native macOS client, along with a curated set of de facto standard open source components including Lima, nerdctl, containerd, and BuildKit. With Finch, you can create and run containers locally, and build and publish Open Container Initiative (OCI) container images. One thing that really stands out from this post is this quote:
Rather than iterating in private and releasing a finished project, we feel open source is most successful when diverse voices come to the party. We have plans for features and innovations, but opening the project this early will lead to a more robust and useful solution for all. We are happy to address issues, and are ready to accept pull requests.
So check out this post and get hands on with Finch.
Apache Hudi
Hot off the heels of featuring Apache Hudi in the last Build on Open Source show, we have Suthan Phillips and Dylan Qu who have put together Build your Apache Hudi data lake on AWS using Amazon EMR – Part 1, where they cover best practices when building Hudi data lakes on AWS using Amazon EMR
Apache Kafka
With so many choices for Builders on how they deploy Apache Kafka, how do you decide which is the right option for you? Well, AWS Community Builder John Preston is here to provide his thoughts on this in his blog post, AWS MSK, Confluent Cloud, Aiven. How to chose your managed Kafka service provider? After you have read the post, share your thoughts with John in the comments.
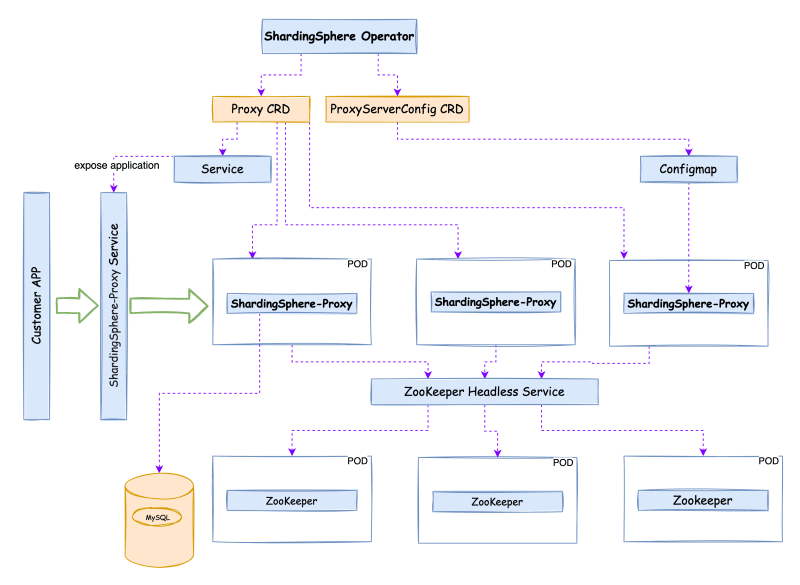
Apache ShardingSphere
Apache ShardingSphere follows Database Plus - our community's guiding development concept for creating a complete ecosystem that allows you to transform any database into a distributed database system, and easily enhance it with sharding, elastic scaling, data encryption features & more. It focuses on repurposing existing databases, by placing a standardized upper layer above existing and fragmented databases, rather than creating a new database. You can read more about this project in the post, ShardingSphere-on-Cloud & Pisanix replace Sidecar for a true cloud-native experience and find out more about ShardingSphere-on-Cloud that shows you how you can deploy ShardingSphere in a Kubernetes environment on AWS.
MySQL and MariaDB
In the post Security best practices for Amazon RDS for MySQL and MariaDB instances, Chelluru Vidyadhar discuss the different best practices you can follow in order to run Amazon RDS for MySQL and Amazon RDS for MariaDB databases securely. Chelluru look at the current good practices at network, database instance, and DB engine (MySQL and MariaDB) levels.
Sticking with MariaDB, Vijay Karumajji and Justin Lim have put together Increase write throughput on Amazon RDS for MariaDB using the MyRocks storage engine, where they explore the newly launched MyRocks storage engine architecture in Amazon RDS for MariaDB 10.6. They start by covering MyRocks and its architecture, use cases of MyRocks, and demonstrate our benchmarking results, so you can determine if the MyRocks storage engine can help you get increased performance for your workload.

PostgreSQL
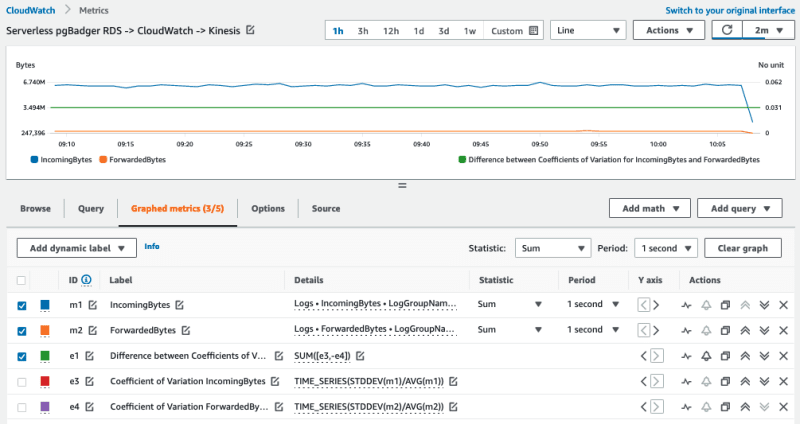
pgBadger is an open source tool for identifying both slow-running and frequently running queries in your PostgreSQL applications, and helping guide you on how to improve their performance. In the blog post, A serverless architecture for analyzing PostgreSQL logs with pgBadger Krishna Sarabu, Chirag Dave, and Mark Townsend walk you through a solution design that enables the analysis of PostgreSQL database logs using no persistent compute resources. This allows you to use pgBadger without having to worry about provisioning, securing, and maintaining additional compute and storage resources. [hands on]
Kubernetes
We had a plethora of Kubernetes content in the run up to re:Invent, so here is a round up of the ones I found most interesting.
- How to detect security issues in Amazon EKS clusters using Amazon GuardDuty – Part 1 walks through the events leading up to a real-world security issue that occurred due to EKS cluster misconfiguration, and then looks at how those misconfigurations could be used by a malicious actor, and how Amazon GuardDuty monitors and identifies suspicious activity throughout the EKS security event
- Persistent storage for Kubernetes the first of a two part post that covers the concepts of persistent storage for Kubernetes and how you can apply those concepts for a basic workload

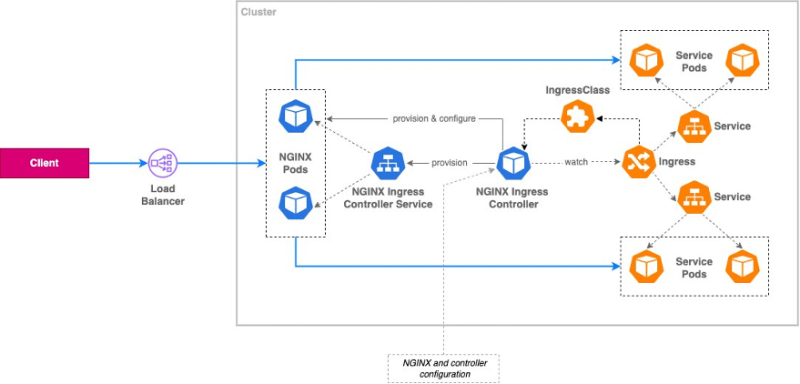
Exposing Kubernetes Applications, Part 3: NGINX Ingress Controller the third in a series looking at ways to expose applications running in a Kubernetes cluster for external access, this post covers using an open-source implementation of an Ingress controller: NGINX Ingress Controller, exploring some of its features and the ways it differs from its AWS Load Balancer Controller
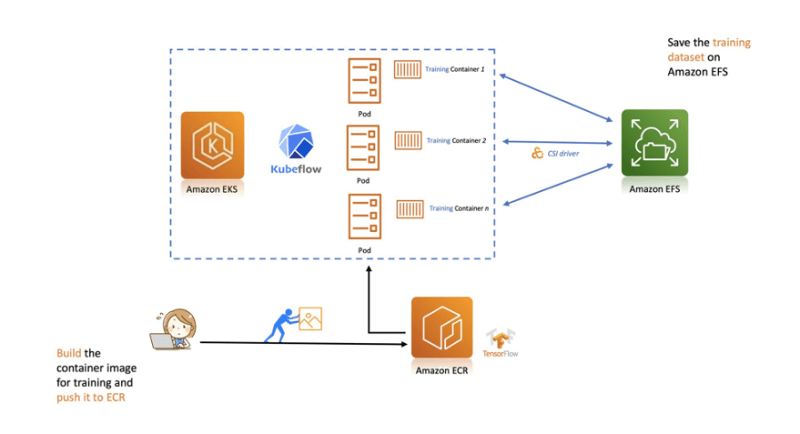
- Machine Learning with Kubeflow on Amazon EKS with Amazon EFS walks through how you can use Kubeflow on Amazon EKS to implement model parallelism and use Amazon EFS as persistent storage to share datasets [hands on]
Other posts and quick reads
- Using Authorizer with DynamoDB and EKS shows how to use the open source Authorizer project to provide an auth solution when working with Amazon DynamoDB

- Launch self-supervised training jobs in the cloud with AWS ParallelCluster describes the process for creating a High Performance Compute (HPC) cluster that will launch large, self-supervised training jobs, primarily leveraging two technologies: AWS ParallelCluster and the Vision Self-Supervised Learning (VISSL) library

- Getting started with JavaScript resolvers in AWS AppSync GraphQL APIs takes a look at how you can now use JavaScript to write your AppSync pipeline resolver code and AppSync function code, as well as the existing Velocity Template Language (VTL)

- Easy and accurate forecasting with AutoGluon-TimeSeries showcases AutoGluon-TimeSeries’s ease of use in quickly building a powerful forecaster [hands on]

- Managing images in your NextJS app with AWS AppSync and the AWS CDK shows how combining the AWS CDK with the Amplify JavaScript library, they provide the flexibility needed for teams to scale independently and confidently, while still taking advantage of modern tooling [hands on]
Case Studies
Announcing the winners of the inaugural Future of Government Awards: Celebrating digital transformation initiatives around the world includes details of the winners of Open Source Creation of the Year Award and Open Source Adaptation of the Year Award.
DENT, the Open Source Network Operating System for Distributed Edge, Now Powers AWS Just Walk Out Technology a look at how this networking open source project is being used by AWS in it's Just Walk Out Technology
Quick updates
Apache Iceberg
Amazon Athena has added SQL commands and file formats that simplify the storage, transformation, and maintenance of data stored in Apache Iceberg tables. These new capabilities enable data engineers and analysts to combine more of the familiar conveniences of SQL with the transactional properties of Iceberg to enable efficient and robust analytics use cases.
Today's launch adds CREATE TABLE AS SELECT (CTAS), MERGE, and VACUUM commands that streamline the lifecycle management of your Iceberg data: CTAS makes it fast and efficient to create tables, MERGE synchronises tables in one step to simplify your data preparation and update tasks, and VACUUM helps you manage storage footprint and delete records to meet regulatory requirements such as GDPR. We've also added support for AVRO and ORC so you can create Iceberg tables with a broader set of file formats. Lastly, you can now simplify access to Iceberg-managed data by using Views to hide complex joins, aggregations, and data types.
Apache Airflow
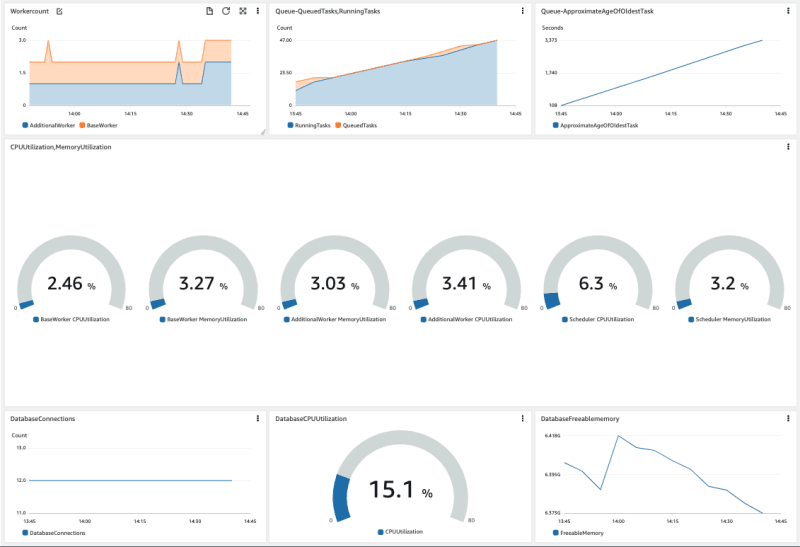
Amazon Managed Workflows for Apache Airflow (MWAA) now provides Amazon CloudWatch metrics for container, database, and queue utilisation. Amazon MWAA is a managed service for Apache Airflow that lets you use the same familiar Apache Airflow platform as you do today to orchestrate your workflows and enjoy improved scalability, availability, and security without the operational burden of having to manage the underlying infrastructure. With these additional metrics, customers have improved visibility into their Amazon MWAA performance to help them debug workloads and appropriately size their environments.
Check out the excellent post Introducing container, database, and queue utilization metrics for the Amazon MWAA environment, where Uma Ramadoss dives deep and shares details about the new metrics published for Amazon MWAA environment, build a sample application with a pre-built workflow, and explore the metrics using CloudWatch dashboard. [hands on]
Apache Flink
Apache Flink is a popular open source framework for stateful computations over data streams. It allows you to formulate queries that are continuously evaluated in near real time against an incoming stream of events. There were a couple of announcements this week featuring this open source project.
First up was news that Amazon Kinesis Data Analytics for Apache Flink now supports Apache Flink version 1.15. This new version includes improvements to Flink's exactly-once processing semantics, Kinesis Data Streams and Kinesis Data Firehose connectors, Python User Defined Functions, Flink SQL, and more. The release also includes an AWS-contributed capability, a new Async-Sink framework which simplifies the creation of custom sinks to deliver processed data. Read more about how we contributed to this release by checking out the post, Making it Easier to Build Connectors with Apache Flink: Introducing the Async Sink where Zichen Liu, Steffen Hausmann, and Ahmed Hamdy talk about a feature of Apache Flink, Async Sinks, and how the Async Sink works, how you can build a new sink based on the Async Sink, and discuss our plans to continue our contributions to Apache Flink.
Amazon EMR customers can now use AWS Glue Data Catalog from their streaming and batch SQL workflows on Flink. The AWS Glue Data Catalog is an Apache Hive metastore-compatible catalog. You can configure your Flink jobs on Amazon EMR to use the Data Catalog as an external Apache Hive metastore. With this release, You can then directly run Flink SQL queries against the tables stored in the Data Catalog.
Flink supports on-cluster Hive metastore as the out-of-box persistent catalog. This means that metadata had to be recreated when clusters were shutdown and it was hard for multiple clusters to share the same metadata information. Starting with Amazon EMR 6.9, your Flink jobs on Amazon EMR can manage Flink’s metadata in AWS Glue Data Catalog. You can use a persistent and fully managed Glue Data Catalog as a centralised repository. Each Data Catalog is a highly scalable collection of tables organised into databases.
The AWS Glue Data Catalog provides a uniform repository where disparate systems can store and find metadata to keep track of data in data silos. You can then query the metadata and transform that data in a consistent manner across a wide variety of applications. With support for AWS Glue Data Catalog, you can use Apache Flink on Amazon EMR for unified BATCH and STREAM processing of Apache Hive Tables or metadata of any Flink tablesource such as Iceberg, Kinesis or Kafka. You can specify the AWS Glue Data Catalog as the metastore for Flink using the AWS Management Console, AWS CLI, or Amazon EMR API.
Amazon EMR
A couple of Amazon EMR on Amazon EKS updates this week.
The ACK controller for Amazon EMR on Elastic Kubernetes Service (EKS) has graduated to generally available status. Using the ACK controller for EMR on EKS, you can declaratively define and manage EMR on EKS resources such as virtual clusters and job runs as Kubernetes custom resources. This lets you manage these resources directly using Kubernetes-native tools such as ‘kubectl’. EMR on EKS is a deployment option for EMR that allows you to run open-source big data frameworks on EKS clusters. You can consolidate analytical workloads with your Kubernetes-based applications on the same Amazon EKS cluster to improve resource utilisation and simplify infrastructure management and tooling. ACK is a collection of Kubernetes custom resource definitions (CRDs) and custom controllers working together to extend the Kubernetes API and manage AWS resources on your behalf.
Following that we had the announcement of support for configuring Spark properties within EMR Studio Jupyter Notebook sessions for interactive Spark workloads. Amazon EMR on EKS enables customers to efficiently run open-source big data frameworks such as Apache Spark on Amazon EKS. Amazon EMR on EKS customers setup and use a managed endpoint (available in preview) to run interactive workloads using integrated development environments (IDEs) such as EMR Studio. Data scientists and engineers use EMR Studio Jupyter notebooks with EMR on EKS to develop, visualise and debug applications written in Python, PySpark, or Scala. With this release, customers can now customise their Spark settings, such as driver and executor CPU/memory, number of executors, and package dependencies, within their notebook session to handle different computational workloads or different amounts of data, using a single managed endpoint.
Trino
Trino is an open source SQL query engine used to run interactive analytics on data stored in Amazon S3. Announced last week was news that Amazon S3 improves performance of queries running on Trino by up to 9x when using Amazon S3 Select. With S3 Select, you “push down” the computational work to filter your S3 data instead of returning the entire object. By using Trino with S3 Select, you retrieve only a subset of data from an object, reducing the amount of data returned and accelerating query performance.
AWS’s upstream contribution to open source Trino, you can use Trino with S3 Select to improve your query performance. S3 Select offloads the heavy lifting of filtering and accessing data inside objects to Amazon S3, which reduces the amount of data that has to be transferred and processed by Trino. For example, if you have a data lake built on Amazon S3 and use Trino today, you can use S3 Select’s filtering capability to quickly and easily run interactive ad-hoc queries.
You can explore this in more detail by checking out this blog post, Run queries up to 9x faster using Trino with Amazon S3 Select on Amazon EMR where Boni Bruno and Eric Henderson look at the performance benchmarks on Trino release 397 with S3 Select using TPC-DS-like benchmark queries at 3 TB scale.

AWS Amplify
Amplify DataStore provides frontend app developers the ability to build real-time apps with offline capabilities by storing data on-device (web browser or mobile device) and automatically synchronizing data to the cloud and across devices on an internet connection. Launched this week was the release of custom primary keys, also known as custom identifiers, for Amplify DataStore to provide additional flexibility for your data models. You can dive deeper into this update by reading along in the post, New: Announcing custom primary key support for AWS Amplify DataStore
We had another Amplify DataStore post that looks at a number of other enhancements with Amplify DataStore that were released this week, that make working with relational data easier: lazy loading, nested query predicates, and type enhancements. To find out more about these new enhancements, check out NEW: Lazy loading & nested query predicates for AWS Amplify DataStore [hands on]
Also announced this week was the release of version 5.0.0 of the Amplify JavaScript library. This release is jam-packed with highly requested features, in addition to under the hood improvements to enhance stability and usability of the JavaScript library. Check out the post, Announcing AWS Amplify JavaScript library version 5 which contains links to the GitHub repo.
The Amplify team have been super busy, as they also announced a developer preview to expand Flutter support to Web and Desktop for the API, Analytics, and Storage use cases. Developers can now build cross-platform Flutter apps with Amplify that target iOS, Android, Web, and Desktop (macOS, Windows, Linux) using a single codebase. Combined with the Authentication preview that was previously released, developers can now build cross-platform Flutter applications that include REST API or GraphQL API to interact with backend data, analytics to understand user behaviour, and storage for saving and retrieving files and media. This developer preview version was written fully in Dart, allowing developers to deploy their apps to all target platforms currently supported by Flutter. Amplify Flutter is designed to provide developers with consistent behaviour, regardless of the target platform. With these feature sets now available on Web and Desktop, Flutter developers can build experiences that target the platforms that matter most to their customers. Check out the post, Announcing Flutter Web and Desktop support for AWS Amplify Storage, Analytics and API libraries, to find out more about this launch and how to use AWS Amplify GraphQL API and Storage libraries by creating a grocery list application with Flutter that targets iOS, Android, Web, and Desktop. [hands on]

Finally, we also announced that AWS Amplify is announcing support for GraphQL APIs without Conflict Resolution enabled! With this launch, it’s easier than ever to use custom mutations and queries, without needing to manage the underlying conflict resolution protocol. You can still model your data with the same easy-to-use graphical interface. And, we are also bringing improved GraphQL API testing to Studio through the open-source tool, GraphiQL.
Find out more by reading the post, Announcing new GraphQL API features in Amplify Studio
Bonus Content
There has been plenty of AWS Amplify content posted this week, so why not check out some of these posts:
- NEW: Build React forms for any API in minutes with AWS Amplify Studio (no AWS Account required) looks at Amplify Studio form builder, the new way to build React form components for any API [hands on]

- Text to Speech on Android Using AWS Amplify provides a nice example on how to use the Predictions category to implement text to speech in an Android app [hands on]
AWS Toolkits
AWS Toolkits for JetBrains and VS Code released a faster code iteration experience for developing AWS SAM applications. The AWS Toolkits are open source plugins for JetBrains and VS Code IDEs that provide an integrated experience for developing Serverless applications, including assistance for getting started and local step-through debugging capabilities for Serverless applications. With today’s release, the Toolkits adds SAM CLI’s Lambda “sync” capabilities shipped as SAM Accelerate (check out the announcement). These new features in the Toolkits for JetBrains and VS Code provide customers with increased flexibility. Customers can either sync their entire Serverless application (i.e., infrastructure and the code), or sync just the code changes and skip Cloudformation deployments.
Read more in the full blog post, Faster iteration experience for AWS SAM applications in the AWS Toolkits for JetBrains and VS Code
Grafana
Launched this week was Amazon Managed Grafana’s new alerting feature that allows customers to gain visibility into their Prometheus Alertmanager alerts from their Grafana workspace. Customers can continue to use classic Grafana Alerting in their Amazon Managed Grafana workspaces if that experience better fits their needs. Customers using the Amazon Managed Service for Prometheus workspaces to collect Prometheus metrics utilise the fully managed Alert Manager and Ruler features in the service to configure alerting and recording rules. With this feature, they can visualise all their alert and recording rules configured in their Amazon Managed Service for Prometheus workspace.
Read more in the hands on guide, Announcing Prometheus Alertmanager rules in Amazon Managed Grafana
Also announced was Amazon Managed Grafana support for connecting to data sources inside an Amazon Virtual Private Cloud (Amazon VPC). Customers using Amazon Managed Grafana have been asking for support to connect to data sources that reside in an Amazon VPC and are not publicly accessible. Data in Amazon OpenSearch Service clusters, Amazon RDS instances, self-hosted data sources, and other data sensitive workloads often are only privately accessible. Customers have expressed the need to connect Amazon Managed Grafana to these data sources securely while maintaining a strong security posture.
Read more about this in the post, Announcing Private VPC data source support for Amazon Managed Grafana
NodeJS
You can now develop AWS Lambda functions using the Node.js 18 runtime. This version is in active LTS status and considered ready for general use. When creating or updating functions, specify a runtime parameter value of nodejs18.x or use the appropriate container base image to use this new runtime. This runtime version is supported by functions running on either Arm-based AWS Graviton2 processors or x86-based processors. Using the Graviton2 processor architecture option allows you to get up to 34% better price performance.
Read the post Node.js 18.x runtime now available in AWS Lambda, to find out more about the major changes available with the Node.js 18 runtime in Lambda. You should also check out Why and how you should use AWS SDK for JavaScript (v3) on Node.js 18 as the AWS SDK for JavaScript (v3) is included by default in AWS Lambda Node.js 18 runtime.
MariaDB
Amazon Relational Database Service (Amazon RDS) for MariaDB now supports MariaDB minor versions 10.6.11, 10.5.18, 10.4.27 and 10.3.37. We recommend that you upgrade to the latest minor versions to fix known security vulnerabilities in prior versions of MariaDB, and to benefit from the numerous bug fixes, performance improvements, and new functionality added by the MariaDB community.
PostgreSQL
Amazon Relational Database Service (Amazon RDS) for PostgreSQL now supports PostgreSQL minor versions 14.5, 13.8, 12.12, 11.17, and 10.22. We recommend you upgrade to the latest minor version to fix known security vulnerabilities in prior versions of PostgreSQL, and to benefit from the bug fixes, performance improvements, and new functionality added by the PostgreSQL community. Please refer to the PostgreSQL community announcement for more details about the release. This release also includes support for Amazon RDS Multi-AZ with two readable standbys and updates for existing supported PostgreSQL extensions: PostGIS extension is updated to 3.1.7, pg_partman extension is updated to 4.6.2, and pgRouting extension is updated to 3.2.2. Please see the list of supported extensions in the Amazon RDS User Guide for specific versions.
Videos of the week
Kubernetes and AWS
If you missed this, then it is well worth checking out the awesome Jay Pipes discuss AWS' use of Kubernetes, as well as AWS' contributions to the Kubernetes code base. The interview was recorded at KubeCon North America last month.
OpenSearch
The videos from OpenSearchCon that took place earlier this year are now available. You can see the entire list here, and there are a number of great sessions covering a very broad range of topics. The one I spent time watching was this session from OpenSearch Core Codebase Nicholas Knize, OpenSearch Maintainer, Lucene Committer and PMC Member. If you are interested in contributing to OpenSearch and curious in how to get started, then this session will answer some of these questions and more by raising the hood and exploring the code base.
Kubeflow and MLFlow
Join your hosts Antje Barth and Chris Fregley as they are joined by a number of guests to talk about some great open source projects such as Kubeflow, MLflow, datamesh.utils, and data.all
Build on Open Source
For those unfamiliar with this show, Build on Open Source is where we go over this newsletter and then invite special guests to dive deep into their open source project. Expect plenty of code, demos and hopefully laughs. We have put together a playlist so that you can easily access all (seven) of the other episodes of the Build on Open Source show. Build on Open Source playlist
Events for your diary
Apache Hudi Meetup - re:Invent
November 28th - December 3rd, Las Vegas
Apache Hudi is a data platform technology that helps build reliable and scalable data lakes. Hudi brings stream processing to big data, supercharging your data lakes, making them orders of magnitude more efficient.
Hudi is widely used by many companies like Uber, Walmart, Amazon.com, Robinhood, GE, Disney Hotstar, Alibaba, ByteDance that build transactional or streaming data lakes. Hudi also comes pre-built with Amazon EMR and is integrated with Amazon Athena, AWS Glue as well as Amazon Redshift. It is also integrated in many other cloud providers such as Google cloud and Alibaba cloud.
Please join the Apache Hudi community for a Meetup hosted by Onehouse and the Apache Hudi community at the re:Invent site. Here are the different times and locations (local Vegas time):
- Nov 28th [7:00 pm - 7:20 pm] Networking
- Nov 28th [7:20 pm - 7:50 pm] Hudi 101 (Speaker TBA)
- Nov 28th [7:50 pm - 8:20 pm] How Hudi supercharges your lake house architecture with streaming and historical data by Vinoth Chandar
- Nov 28th [8:20 pm - 8:40 pm] Roadmap (Speaker TBA)
- Nov 28th [8:40 pm - 9:00 pm] Open floor for Q&A
It will be hosted in Conference room “Chopin 2” at the Encore Hotel
re:Invent
November 28th - December 3rd, Las Vegas
re:Invent is happening all this week, and there is plenty of great open source content for you, whether it is breakout sessions, chalk talks, open source vendors in the expo, and more.
We will be featuring open source projects in the Developer Lounge again, in the AWS Modern Applications and Open Source Zone. We have published a schedule of the open source projects you can check out, so why not take a peek at The AWS Modern Applications and Open Source Zone: Learn, Play, and Relax at AWS re:Invent 2022 and come along. I will be there for a big chunk of time on Tuesday, Wednesday, and Thursday. If you have a good open source story to tell, or some SWAG to trade, I will be bringing our Build On Open Source challenge coins, so be sure to hunt me down!
Check out this handy way to look at all the amazing open source sessions, then check out this dashboard [sign up required]. I would love to hear which ones you are excited about so please let me know in the comments or via Twitter. If you want to hear what my top three, must watch sessions, then this is what I would attend (sadly, as an AWS employee I am not allowed to attend sessions)
- OPN306 AWS Lambda Powertools: Lessons from the road to 10 million downloads - Heitor Lessa is going to deliver an amazing session on the journey from idea to one of the most loved and used open source tools for AWS Lambda users
- BOA204 When security, safety, and urgency all matter: Handling Log4Shell - Cannot wait for this session from Abbey Fuller who will walk us through how we managed this incident
- OPN202 Maintaining the AWS Amplify Framework in the open - Matt Auerbach and Ashish Nanda are going to share details on how Amplify engineering managers work with the OSS community to build open-source software
OpenSearch
Every other Tuesday, 3pm GMT
This regular meet-up is for anyone interested in OpenSearch & Open Distro. All skill levels are welcome and they cover and welcome talks on topics including: search, logging, log analytics, and data visualisation.
Sign up to the next session, OpenSearch Community Meeting
Stay in touch with open source at AWS
I hope this summary has been useful. Remember to check out the Open Source homepage to keep up to date with all our activity in open source by following us on @AWSOpen





Latest comments (5)
Hi guys, I would be highly interested in being aware of OpenSearch rodmap/lifecycle and EOLs : where should I get these please ?
I will see if I can find out
For now we have this :
endoflife.date/opensearch
Let me know if it looks good
Hello @adriens - I recommend checking out our Releases page for official, up-to-date information on this topic: opensearch.org/releases.html
"The duration of the maintenance window will vary from product to product and release to release. By default, versions will remain under maintenance until the next major version enters maintenance, or 1 year passes, whichever is longer. Therefore, at any given time, the current major version and previous major version will both be supported, as well as older major versions that have been in maintenance for less than 12 months. Please note that, maintenance windows are influenced by the support schedules for dependencies the software includes, community input, the scope of the changes introduced by the new version, and estimates for the effort required to continue maintenance of the previous version."
Hope this helps.
Hi Kris, sure ! It helps a lot, it should help improve
endoflife.dateinitiative :OpenSearch is a very living and fast growing product. Still it seems we could improve some of its eols datas :
By adding some resources helping get more data about :
OpenSearch | endoflife.date
Check End of Life, Support Schedule, and release timelines for AlmaLinux, Alpine Linux, Amazon Linux, Android OS, Angular, Ansible-core, Ansible, antiX, Apache Airflow, Apache Cassandra, Apache Groovy, Apache HTTP Server, API Platform, Azure DevOps, Blender, Bootstrap, CakePHP, CentOS, CFEngine, Citrix Virtual Apps and Desktops, Adobe ColdFusion, Composer, Consul, Google Container-Optimized OS (COS), Couchbase Server, Debian, Devuan, Django, Docker Engine, .NET, .NET Framework, Drupal, Drush, Amazon EKS, Elasticsearch, Electron, Elixir, Ember, EuroLinux, Fedora Linux, FFmpeg, Filebeat, FileMaker, Firefox, FortiOS, FreeBSD, GitLab, Google Kubernetes Engine, Go, Godot, Gradle, Grafana, HAProxy, Vault, Apache HBase, Intel Processors, Internet Explorer, Apple iOS, Apple iPadOS, iPhone, Java/OpenJDK, Jenkins, jQuery, KDE Plasma, Amazon Kindle, Kotlin, Kubernetes, Laravel, LibreOffice, LineageOS, Linux Kernel, Linux Mint, Apache Log4j, Looker, macOS, Magento, MariaDB, Mattermost, MediaWiki, MongoDB Server, Moodle, Microsoft Exchange, Microsoft SharePoint, Microsoft SQL Server, Mule Runtime, MX Linux, MySQL, NetBSD, Nextcloud, nginx, nix, NixOS, Node.js, Nokia Mobile, Nomad, NumPy, Nutanix AOS, Nutanix Files, Nutanix Prism Central, NVIDIA Driver, NVIDIA GPUs, Microsoft Office, OpenBSD, OpenSearch, OpenSSL, openSUSE, OpenZFS, Oracle Linux, Palo Alto Networks GlobalProtect App, Palo Alto Networks PAN-OS, Palo Alto Networks Cortex XDR agent, PCI-DSS, Perl, PHP, Google Pixel, Postfix, PostgreSQL, PowerShell, Python, Qt, Quarkus, RabbitMQ, React, Netgear ReadyNAS, Red Hat Enterprise Linux, Redis, Redmine, Rocky Linux, ROS, Roundcube Webmail, Ruby on Rails, Ruby, Samsung Mobile, Slackware Linux, SUSE Linux Enterprise Server, Apache Solr, Splunk, Spring Boot, Spring Framework, Microsoft Surface, Symfony, Tarantool, Telegraf, Terraform, Apache Tomcat, Twig, TYPO3, Ubuntu, Unity, UnrealIRCd, Varnish, Visual Studio, VMware ESXi, VMware Horizon, VMware Site Recovery Manager, VMware vCenter Server, Vue, Wagtail, Apple watchOS, Windows, Windows Embedded, Windows Server, WordPress, Yocto Project, Zabbix, Apache ZooKeeper, etc at one place.