November 21st, 2022 - Instalment #136
Estoy haciendo un pequeño experimento para ver si a la gente le gustaría ver una versión en español de mi boletín. Por favor déjame saber lo que piensa.
Bienvenido
Bienvenido al boletín informativo de código abierto de AWS, edición n.° 136, tal como aparece en el último episodio de Build on Open Source. Esta semana presentamos nuevos proyectos que incluyen "dynamoit" una interfaz gráfica de usuario de JavaFX para Amazon DynamoDB, "construcción-apache-kafka-conectores", "msk-config-providers" y proyectos "msk-serverless-data-pipeline" para ayudar a que su vida más fácil cuando se trabaja con Apache Kafka, "stowrs-to-s3" una herramienta para trabajar con datos STOWRS en AWS, "aws-device-lobby" una herramienta para facilitar la incorporación de dispositivos en AWS IoT Core, "aws-graviton-run -confidential-ml-workloads-using-nitro-enclaves" un buen ejemplo de cómo puede hacer Confidential Computing para casos de uso de aprendizaje automático, "aws-hpc-builder" una herramienta para ayudarlo a administrar sus herramientas HPC de código abierto y muchas más.
También tenemos AWS y contenido de la comunidad que cubre algunos de sus proyectos de código abierto favoritos, incluidos Apache Kafka, Amazon Linux, Amazon EMR, Kubernetes, PostgreSQL, MySQL, Apache Airflow, GraphQL, Karpenter, Terraform, RabbitMQ, Prometheus, Redis, OpenSearch, AWS Amplify, Next.js, SpringBoot, Kubeflow, Krakatoa, XMesh, ffmpeg y más.
Retroalimentación
Hágame saber cómo podemos mejorar este boletín y cómo AWS puede trabajar mejor con proyectos y tecnologías de código abierto completando esta breve encuesta que probablemente lo llevará menos de 30 segundos para completar. ¡Muchas gracias!
Celebrando a los contribuyentes de código abierto
Los artículos y proyectos compartidos en este boletín solo son posibles gracias a los muchos colaboradores en código abierto. Me gustaría gritar y agradecer a aquellas personas que realmente impulsan el código abierto y nos permiten a todos aprender y construir sobre lo que han creado.
Así que gracias a los siguientes héroes de código abierto: Jonathan Swinney, Bharathi (Batty) Muthukrishnan, Conrad Wiebe, Evan Spearman, Subbusainath Rengasamy, Kartik Kalamadi, Rahul Kharse, Changbin Gong, Sandeep Palavalasa, Dan Mangum, Manabu McCloskey, Nima Kaviani, Kanwaljit Khurmi, James Eastham, Mike Jerome, Abhi Khanna, Ricardo Ferreira, Pavlo Iatsiuk, Jayaprakash Alawala, Paavan Mistry, Anton Babenko, Suresh Poopandi, Seb Kasprzak, Sheetal Joshi and Vipin Mohan.
Últimos proyectos de código abierto
Lo mejor de los proyectos de código abierto es que puede revisar el código fuente. Si le gusta el aspecto de estos proyectos, asegúrese de echar un vistazo al código y, si le resulta útil, póngase en contacto con el mantenedor para proporcionar comentarios, sugerencias o incluso enviar una contribución.
Herramientas
dynamoit
dynamoit este proyecto (¡me encanta el nombre!) de Pavlo Iatsiuk es un cliente gráfico simple de DynamoDB escrito en JavaFX. Este cliente permite una fácil visualización, edición, creación y eliminación de datos.

building-apache-kafka-connectors
building-apache-kafka-connectors este repositorio de mi colega Ricardo Ferreira proporciona un código de muestra que muestra los aspectos importantes del desarrollo de conectores personalizados para Kafka Connect. Proporciona los recursos para compilar, implementar y ejecutar el código en las instalaciones mediante Docker, además de ejecutar el código en la nube. Construir conectores para Apache Kafka es difícil. Lo más probable es que acabas de leer la oración anterior y asentiste inconscientemente con la cabeza. La razón por la que esto sucede es que Kafka Connect, que es la plataforma de tiempo de ejecución detrás de los conectores de ejecución, utiliza una arquitectura de software no tan trivial. También falta una documentación adecuada que enseñe cómo funciona el marco de desarrollo, cómo se conecta con el tiempo de ejecución y qué mejores prácticas debe seguir. Para situaciones como esta, su mejor opción es obtener un código existente e intentar hacer lo mismo, con la esperanza de que su propio conector se escriba de la mejor manera posible.
msk-config-providers
msk-config-providers En Apache Kafka, puede usar la interfaz de clase ConfigProvider para evitar que los secretos aparezcan en texto no cifrado en las configuraciones del conector. Este repositorio proporciona ejemplos de proveedores de configuración de Apache Kafka que se pueden usar para integrar las propiedades del cliente de Kafka con otros sistemas. Proporciona integración con AWS Secrets Manager, AWS Systems Manager Parameter Store y Amazon S3.
stowrs-to-s3
stowrs-to-s3 STOW-RS es una especificación estándar para saber cómo transferir imágenes a sistemas de destino, normalmente utilizados en sistemas de imágenes médicas. Este proyecto es un servicio STOW-RS to S3 basado en Python. Este servicio recibe solicitudes STOW-RS compatibles con DICOM PS18 para almacenar y copia los datos en un depósito S3 específico a través de subprocesos paralelos. Este proyecto se puede implementar en la nube de AWS o en las instalaciones. El proyecto viene con una infraestructura AWS CDK como paquete de código que permite implementarlo fácilmente en la nube de AWS y también se puede ejecutar como un proceso normal de Python o como un contenedor OCI (por ejemplo, una imagen acoplable) si se implementa en las instalaciones.

aws-device-lobby
aws-device-lobby Esta solución proporciona un método para la incorporación de códigos QR de dispositivos a AWS IoT Core. Simplifica el proceso de aprovisionamiento e incorporación de dispositivos al eliminar el requisito de que se conozca una cuenta/región de nube final en el momento del aprovisionamiento del dispositivo en la fábrica. Esto permite a los fabricantes de dispositivos producir dispositivos IoT genéricos que no estén vinculados a los servicios de nube finales. Los operadores de la plataforma IoT pueden conectar estos dispositivos a sus servicios en el campo de manera flexible.

aws-hpc-builder
aws-hpc-builder es un sistema de gestión y creación de aplicaciones HPC universales (que se denomina módulo para el constructor) que facilita la compilación e implemente aplicaciones HPC en Amazon Linux 2 y Amazon Linux 2022, que admiten todas las plataformas principales que son Intel/AMD/Graviton. Esta herramienta compila aplicaciones HPC (WRF, VASP, etc.) y sus dependencias con compiladores de proveedores o compiladores GNU. Estandariza y modulariza el procedimiento de compilación en todas las plataformas compatibles.
Demos, Samples, Solutions and Workshops
deploy-stable-diffusion-model-on-amazon-sagemaker-endpoint
implementar-stable-diffusion-model-on-amazon-sagemaker-endpoint Stable Diffusion es un modelo de texto a imagen de aprendizaje profundo que es similar a otras aplicaciones como Dall-E y Midjourney. Se utiliza principalmente para generar imágenes detalladas condicionadas por descripciones de texto y está despertando mucho interés en este momento. Este repositorio contiene cuadernos que le muestran cómo puede implementar esto en Amazon SageMaker para que pueda comenzar a generar sus propias imágenes.

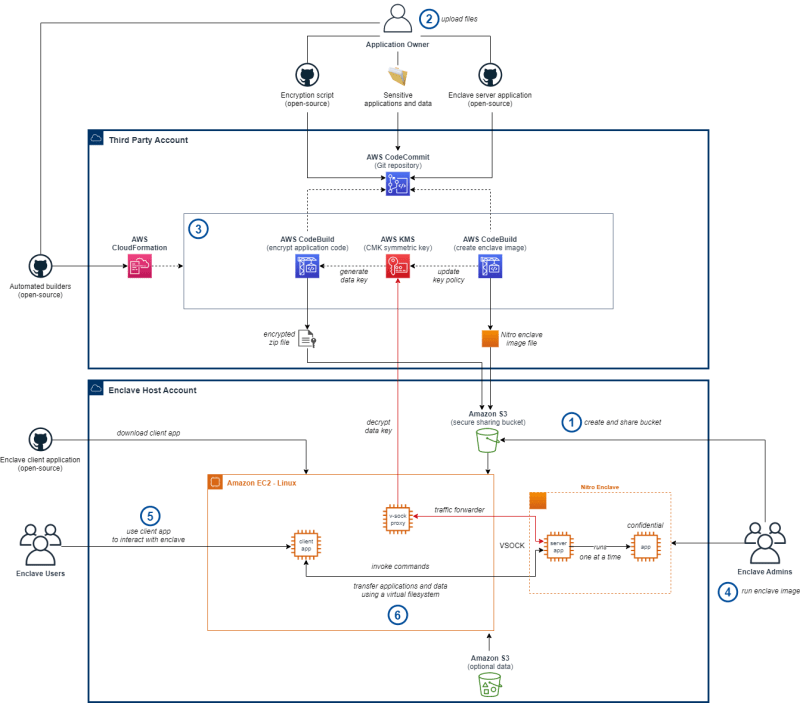
aws-graviton-run-confidential-ml-workloads-using-nitro-enclaves
aws-graviton-run-confidential-ml-workloads-using-nitro-enclaves Durante las últimas tres ediciones de este boletín, hemos visto más proyectos utilizando AWS Nitro Enclaves. Estos han sido para mostrar casos de uso de casos o para proporcionar herramientas adicionales para que sea más fácil de usar. AWS Nitro Enclaves permite a los clientes crear entornos informáticos aislados para mantener la confidencialidad de las aplicaciones y los datos. La muestra proporcionada utiliza enclaves de Nitro para permitir el uso compartido y el uso de archivos confidenciales para cargas de trabajo de ML. El repositorio le muestra cómo puede compartir sus archivos confidenciales AI/ML de una manera que salvaguarde la confidencialidad de la aplicación y los datos. Para presentarle un entorno familiar, incluimos la capacidad de realizar transferencias de datos sin interrupciones para acelerar las cargas de trabajo de ML y DS, así como ejecutar software descargado en tiempo de ejecución para procesar esos datos de manera conveniente.
amazon-memorydb-for-redis-java-client-examples
amazon-memorydb-for-redis-java-client-examples Este repositorio contiene ejemplos del uso de clientes Java para interactuar con Amazon MemoryDB para Redis. Estos ejemplos demuestran lo siguiente: cómo conectarse/desconectarse de Amazon MemoryDB para Redis mediante el cliente de código abierto Redis Jedis, agregar/actualizar registros a la base de datos, recuperar registros por clave y campo/ruta y eliminar registros por clave.
msk-serverless-data-pipeline
msk-serverless-data-pipeline Los servicios sin servidor nos permiten crear aplicaciones sin tener que preocuparnos por la infraestructura subyacente. Esto permite a los desarrolladores evitar el aprovisionamiento, el escalado y la gestión de la utilización de recursos. Este repositorio contiene el código utilizado en el taller en el que creará una canalización de datos sin servidor con Amazon MSK Serverless, que permite consumir datos de muchas aplicaciones cliente diferentes para realizar tareas posteriores, como paneles y análisis. La plantilla de CloudFormation lo ayudará a aprovisionar la infraestructura, luego deberá crear la aplicación Java usted mismo como consumidor.

Publicaciones de blog de AWS y la comunidad
Terraform
El héroe de AWS, Anton Babenko, compartió esta actualización en LinkedIn sobre su objetivo de trabajar en implementaciones sin servidor en Terrform. Ahora, gracias al trabajo de Anton, hay una nueva sección en Serverless Land que le permite filtrar los patrones de Serverless para aquellos que prefieren usar los módulos de Terraform AWS. Actualmente hay siete patrones, pero Anton está trabajando en más, así que asegúrese de conectarse/seguir a Anton para mantenerse al día con estos a medida que caen.
GraphQL
El entusiasta de AWS Subbusainath Rengasamy ha elaborado esta publicación de blog, How to create AWS AppSync with Lambda Authorizer using AWS CDK v2 with Nested Stack le muestra cómo puede comience a utilizar GraphQL en AWS con AWS AppSync y AWS CDK. [las manos en]

FFmpeg
FFmpeg es un proyecto de software gratuito y de código abierto que consiste en un conjunto de bibliotecas y programas para manejar videos, audio y otros archivos y transmisiones multimedia. He usado esta herramienta muchas veces en el pasado (uno de mis usos favoritos es unir imágenes de mi aplicación de lapso de tiempo Raspberry Pi en una buena película). En la publicación, Codificación de video optimizada con FFmpeg en los procesadores Graviton de AWS Jonathan Swinney explora cómo, con las mejoras recientes del proyecto, ahora puede ejecutarlo en un forma más rentable y sostenible utilizando los tipos de instancias de AWS Graviton. Lea la publicación para obtener la información completa.

Krakatoa and XMesh
Krakatoa y XMesh forman parte de un conjunto de herramientas para artistas de AWS Thinkbox que simplifican los flujos de trabajo de representación, VFX y simulación. En la publicación AWS Thinkbox open source Krakatoa MY y XMesh MY, Bharathi (Batty) Muthukrishnan, Conrad Wiebe y Evan Spearman comparten más detalles sobre estos complementos. y cómo están siendo utilizados por los clientes. Es posible que reconozcas algunos de los trabajos de tus Boxsets favoritos.

Karpenter
En la publicación, Usar Karpenter para acelerar el escalado automático de Amazon EMR en EKS Changbin Gong y Sandeep Palavalasa muestran cómo integrar Karpenter en su arquitectura de Amazon EMR en EKS para lograr capacidades de escalado automático más rápidas y conscientes de la capacidad para acelerar sus cargas de trabajo de big data y aprendizaje automático (ML) mientras reduce los costos. [hands on]

Amazon Linux
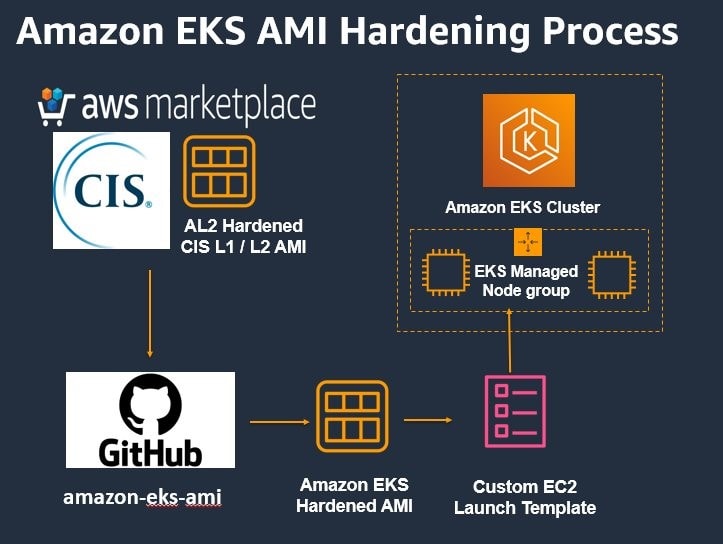
Los puntos de referencia del Centro para la seguridad de Internet (CIS) son buenas prácticas actuales para la configuración segura de un sistema de destino. Definen varios puntos de referencia para el plano de control de Kubernetes y el plano de datos. En la publicación, Building Amazon Linux 2 CIS Benchmark AMIs for Amazon EKS Jayaprakash Alawala y Paavan Mistry comparten instrucciones detalladas paso a paso sobre cómo los clientes pueden crear una imagen de máquina de Amazon (AMI) de Amazon EKS compatible con los puntos de referencia de CIS Amazon Linux2. [hands on]
Otras publicaciones y lecturas rápidas
- Habilitar automáticamente la recopilación de métricas de grupo para grupos de nodos administrados de Amazon EKS muestra cómo habilitar la recopilación de métricas de grupo de Auto Scaling para grupos de nodos administrados de Amazon EKS [práctica ]

- Migrar ROW CHANGE TIMESTAMP de IBM Db2 para z/OS a Amazon RDS para PostgreSQL o Amazon Aurora PostgreSQL-Compatible Edition muestra cómo migrar ROW CHANGE TIMESTAMP de Db2 para z/OS a Amazon RDS para PostgreSQL [práctica]
- Crear una plataforma de análisis interactivo de autoservicio optimizada con Amazon EMR Studio muestra cómo implementar una plataforma de análisis de autoservicio con Amazon EMR y Amazon EMR Studio para mejorar la agilidad de sus equipos de ciencia e ingeniería de datos sin comprometer la seguridad, la escalabilidad, la resiliencia y la rentabilidad de sus cargas de trabajo de big data [práctica]

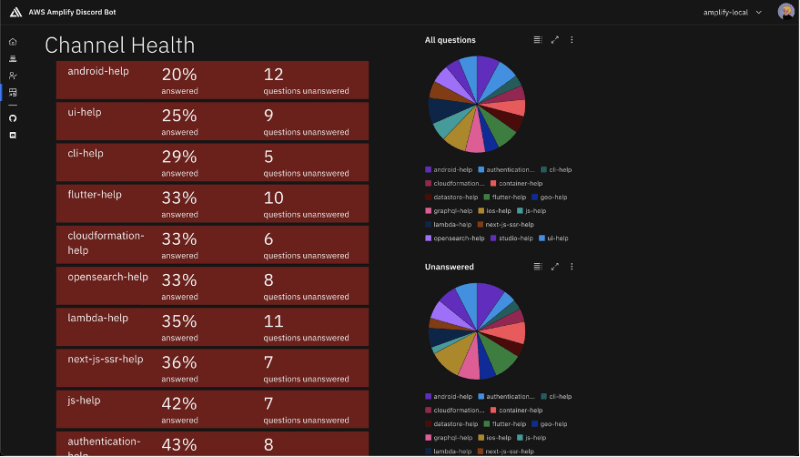
- AWS Amplify presenta: "¡Oye, Amplify!" Un bot de Discord analiza con más detalle un bot de Discord dirigido a mejorar la experiencia de la comunidad de AWS Amplify
Case Studies
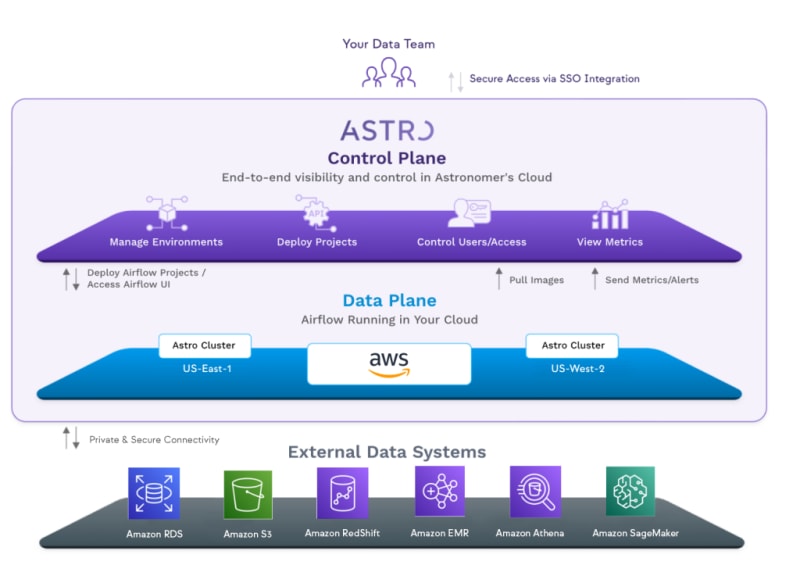
- Conozca a Astro: el servicio Apache Airflow administrado de Astronomer creado y alojado en AWS Obtenga más información sobre cómo Astronomer ha creado su servicio Apache Airflow administrado en AWS
Quick updates
Apache Airflow
Amazon Managed Workflows for Apache Airflow (MWAA) ahora es elegible para HIPAA (Ley de Portabilidad y Responsabilidad de Seguros Médicos), algo que sé que muchos clientes han estado pidiendo. Amazon MWAA es un servicio de orquestación administrado para Apache Airflow que facilita la configuración y el funcionamiento de canalizaciones de datos integrales en la nube. La elegibilidad de HIPAA significa que los clientes sujetos a HIPAA, incluidas las compañías de seguros de salud, los proveedores de atención médica, las cámaras de compensación de atención médica, los programas gubernamentales que pagan la atención médica, los programas de salud para militares y veteranos, así como sus asociados, ahora pueden usar Amazon MWAA para administrar los flujos de trabajo de AWS que almacenar, procesar o transmitir información de salud protegida (PHI). Si tiene un Anexo para socios comerciales (BAA) de HIPAA con AWS, ahora puede comenzar a usar Amazon MWAA para los flujos de trabajo que manejan PHI en entornos nuevos.
MySQL
Amazon Relational Database Service (Amazon RDS) para MySQL ahora es compatible con MySQL versión secundaria 8.0.31. Le recomendamos que actualice a las versiones secundarias más recientes para corregir las vulnerabilidades de seguridad conocidas en versiones anteriores de MySQL y beneficiarse de las numerosas correcciones, mejoras de rendimiento y nuevas funciones agregadas por la comunidad de MySQL.
Amazon Relational Database Service (Amazon RDS) para MySQL ahora es compatible con MySQL versión secundaria 5.7.40. Le recomendamos que actualice a las versiones secundarias más recientes para corregir las vulnerabilidades de seguridad conocidas en versiones anteriores de MySQL y beneficiarse de las numerosas correcciones, mejoras de rendimiento y nuevas funciones agregadas por la comunidad de MySQL.
PostgreSQL
Tras el anuncio de actualizaciones de la base de datos de PostgreSQL por parte de la comunidad de código abierto, hemos actualizado Amazon Aurora PostgreSQL-Compatible Edition para admitir PostgreSQL 14.5, 13.8, 12.12 y 11.17. Estos lanzamientos contienen correcciones de errores y mejoras por parte de la comunidad de PostgreSQL. Esta versión incluye nuevas funciones para Babelfish para Aurora PostgreSQL versión 2.2. Consulte la política de versiones de Aurora para ayudarlo a decidir con qué frecuencia actualizar y cómo planificar su proceso de actualización. Como recordatorio, si está ejecutando cualquier versión de Amazon Aurora PostgreSQL 10, debe actualizar a una versión principal más nueva antes del 31 de enero de 2023.
Esta versión también contiene una mejora para el rendimiento de la replicación lógica. Esta mejora, habilitada como caché de escritura simultánea, ayudará a mejorar el rendimiento de Aurora PostgreSQL al leer continuamente un flujo de replicación lógica (para minimizar el retraso de la replicación). Cada ranura de replicación puede leer datos recientes de la memoria caché en lugar de Aurora Storage. Además de las mejoras de rendimiento, la memoria caché puede ayudar a reducir la E/S. La memoria caché está disponible para las versiones 14.5, 13.8, 12.12 y 11.17 de Aurora PostgreSQL.
Kubernetes
Una semana muy ocupada para las actualizaciones de Kubernetes.
Primero fue la noticia de que ahora puede usar Amazon EKS y Amazon EKS Distro para ejecutar la versión 1.24 de Kubernetes. Los cambios notables en la versión 1.24 de Kubernetes incluyen el reemplazo de Docksershim por contenedor como el tiempo de ejecución del contenedor, un cambio en el comportamiento de la API beta y sugerencias de topología para un tráfico eficiente el enrutamiento está habilitado de forma predeterminada. Además, debe tener en cuenta que PodSecurityPolicy (PSP) está programada para su eliminación en Kubernetes 1.25. Para obtener información detallada sobre estos cambios, consulte la publicación del blog de EKS y las notas de la versión del proyecto Kubernetes. Puede profundizar más en la publicación del blog, Amazon EKS ahora es compatible con la versión 1.24 de Kubernetes de Sheetal Joshi y Vipin Mohan.
Los controladores de AWS para Kubernetes (ACK) para el controlador de servicios de Amazon EC2 ya están disponibles de forma general. ACK le permite aprovisionar y administrar recursos de red de EC2, como VPC, grupos de seguridad y puertas de enlace de Internet mediante la API de Kubernetes. ACK le permite definir y utilizar los recursos del servicio de AWS directamente desde los clústeres de Kubernetes. Con ACK, puede aprovechar los servicios administrados de AWS para sus aplicaciones de Kubernetes sin necesidad de definir recursos fuera del clúster o ejecutar servicios que brinden capacidades de soporte como bases de datos, colas de mensajes o instancias dentro del clúster. ACK ahora es compatible con 14 controladores de servicios de AWS como están disponibles en general con 12 adicionales en versión preliminar.
Prometheus
Amazon Managed Service para Prometheus ahora admite 200 millones de métricas activas por espacio de trabajo. Amazon Managed Service for Prometheus es un servicio de monitoreo compatible con Prometheus totalmente administrado que facilita el monitoreo y las alarmas de las métricas operativas a escala. Prometheus es un proyecto de código abierto de Cloud Native Computing Foundation para monitoreo y alertas que está optimizado para entornos de contenedores como Amazon EKS y Amazon ECS. Con esta versión, los clientes pueden enviar hasta 200 millones de métricas activas a un solo espacio de trabajo después de presentar un aumento de límite y pueden crear muchos espacios de trabajo por cuenta, lo que permite el almacenamiento y análisis de miles de millones de métricas de Prometheus. Obtenga más información leyendo Amazon Managed Service for Prometheus agrega soporte para 200 millones de métricas activas de Abhi Khanna.
AWS SAM
La interfaz de línea de comandos (CLI) del modelo de aplicación sin servidor (SAM) de AWS anuncia la versión preliminar de las pruebas y la depuración locales de AWS Lambda en Terraform. La CLI de AWS SAM es una herramienta para desarrolladores que facilita la creación, prueba, empaquetado e implementación de aplicaciones sin servidor. Terraform es una herramienta de infraestructura como código que le permite crear, cambiar y crear versiones de recursos locales y en la nube de forma segura y eficiente. Los clientes ahora pueden usar SAM CLI para probar y depurar localmente una función de Lambda definida en su aplicación Terraform. SAM CLI puede leer la información de recursos de infraestructura del proyecto Terraform e iniciar funciones Lambda localmente en un contenedor docker para invocar con una carga útil de evento, o adjuntar un depurador utilizando kits de herramientas de AWS en IDE para recorrer paso a paso el código de función Lambda. Esta función es compatible con Terraform versión 1.1 o superior. Para obtener la experiencia más fluida, utilícelo con terraform-aws-modules/lambda versión 4.6.1+. Si quiere ponerse manos a la obra, lea Mejor juntos: AWS SAM CLI y HashiCorp Terraform
RabbitMQ
Amazon MQ ahora brinda soporte para RabbitMQ versión 3.10, una nueva versión que incluye varias correcciones y mejoras a las versiones anteriores de RabbitMQ compatibles con Amazon MQ, 3.8 y 3.9. Con RabbitMQ 3.10, hemos habilitado la compatibilidad con la última versión de colas clásicas (CQv2) de forma predeterminada, que viene con mejoras de memoria y rendimiento. Si está ejecutando versiones anteriores de RabbitMQ, como 3.9 o 3.8, le recomendamos encarecidamente que actualice a RabbitMQ 3.10. Esto se puede lograr con solo unos pocos clics en la consola de administración de AWS. También lo alentamos a habilitar las actualizaciones automáticas de versiones secundarias en RabbitMQ 3.10 para ayudar a garantizar que sus corredores aprovechen las futuras correcciones y mejoras en 3.10.
Redis
Amazon ElastiCache ahora admite el acceso de autenticación de AWS Identity and Access Management (IAM) a los clústeres de Redis. Al usar IAM, puede asociar usuarios y roles de IAM con usuarios de ElastiCache para Redis y administrar su acceso al clúster. Puede configurar la autenticación de IAM creando un usuario de ElastiCache habilitado para IAM y luego asignando este usuario a un grupo de usuarios de ElastiCache apropiado a través de la Consola de administración de AWS, la CLI de AWS o el SDK de AWS. Con las políticas de IAM, puede otorgar o revocar el acceso de clúster a diferentes identidades de IAM. Las aplicaciones de Redis ahora pueden usar las credenciales de IAM para autenticarse en sus clústeres de ElastiCache mientras se conectan a ellos.
OpenSearch
Amazon OpenSearch Service ahora es compatible con OpenSearch y OpenSearch Dashboards versión 2.3. Con esta versión, Amazon OpenSearch Service agrega varias funciones, como nuevos algoritmos a la biblioteca común de aprendizaje automático (ML), mejoras en las agregaciones, mejoras en las visualizaciones de mapas, alertas, detección de anomalías y más.
OpenSearch 2.3 usa Lucene 9.1, y el cambio a la última versión de Lucene ofrece una serie de avances interesantes y seguirá ofreciendo más valor en versiones futuras. Algunas de las mejoras en OpenSearch Service que vienen con OpenSearch 2.3 (incluye funciones que se lanzaron como parte de las versiones 2.0, 2.1 y 2.2 de OpenSearch) incluyen nuevos algoritmos de ML que se agregaron a ML Commons, como regresión lineal, regresión logística, localización, y RCFSummarise, compatibilidad con la búsqueda k-NN basada en Lucene y experiencia de usuario mejorada de Dashboards para la detección de anomalías. Además, esta versión agrega soporte para alertas a nivel de documento, soporte para agregación de términos múltiples como parte del núcleo de OpenSearch, la capacidad de cargar GeoJSON personalizados para visualizaciones de mapas de regiones y mejores niveles de zoom (14x), soporte para búsqueda por relevancia usando SQL y PPL, gestión centralizada de notificaciones en Dashboards, y más. Para obtener una lista completa de las nuevas funciones y mejoras, consulte las notas de la versión de las versiones 2.0, 2.1, 2.2 y 2.3 de OpenSearch.
AWS Amplify & Next.js
Esta semana se anunció que AWS Amplify Hosting es compatible con Next.js 12 y 13, incluido el middleware, la regeneración estática incremental (ISR) a pedido y la optimización de imágenes. Con este lanzamiento, AWS Amplify Hosting ofrece implementaciones de CI/CD totalmente administradas y alojamiento para aplicaciones renderizadas del lado del servidor (SSR) creadas con Next.js y aplicaciones web estáticas. Si desea sumergirse en esto, consulte esta publicación Implemente una aplicación Next.js 13 en AWS con Amplify Hosting de Mike Jerome [hands on].
Videos of the week
SpringBoot
SpringBoot es el marco de aplicaciones de Java más utilizado, pero ¿sabía que puede ejecutar sus aplicaciones SpringBoot en AWS Lambda en tan solo 10 minutos sin cambiar una sola línea de código? En este video, James Eastham se sumerge en tomar una API de Spring existente e implementarla en AWS Lambda en 10 minutos utilizando el modelo de aplicación sin servidor de AWS.
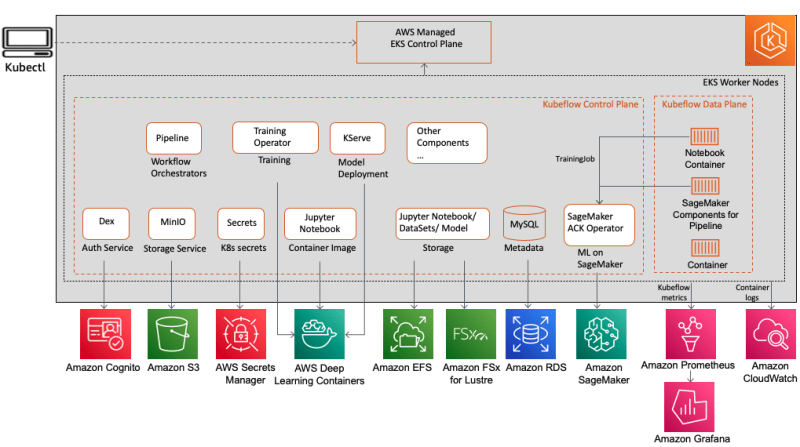
Kubeflow
Su host Kanwaljit Khurmi explora los conceptos básicos de Kubeflow, por qué se usa como un conjunto de herramientas de ML en Kubernetes, por qué a los clientes les encanta y demuestra Kubeflow en AWS (una distribución de Kubeflow específica de AWS) y el valor que agrega a nuestros clientes a través de la integración de altamente Servicios de AWS optimizados, nativos de la nube y listos para la empresa con Kubeflow.
Bonus
Esta semana también presentamos Kubeflow en la publicación de blog, Habilitación de flujos de trabajo de aprendizaje automático híbrido en Amazon EKS y Amazon SageMaker con Kubeflow con un solo clic en la implementación de AWS donde Kanwaljit Khurmi, Kartik Kalamadi y Rahul Kharse echan un vistazo a algunas de las características de la versión 1.6.1 de Kubeflow y destacan tres integraciones importantes que debe conocer: soluciones de infraestructura como código para facilitar la implementación, soporte para capacitación distribuida en Amazon SageMaker y monitoreo y observabilidad mejorados. [hands on]
Crossplane
El equipo de Containers from the Couch se reúne con el orador invitado Dan Mangum de Upbound, los creadores de Crossplane, así como los mantenedores del proyecto Manabu McCloskey y Nima Kaviani de AWS, brindan todo lo que necesita saber para comenzar a comprender y usar Crossplane.
Build on Open Source
Para aquellos que no están familiarizados con este programa, Build on Open Source es donde repasamos este boletín y luego invitamos a invitados especiales a profundizar en su proyecto de código abierto. Espere mucho código, demostraciones y, con suerte, risas.
Hemos creado una lista de reproducción para que pueda acceder fácilmente a todos los demás episodios del programa Build on Open Source. [ingles] Build on Open Source playlist
Eventos para tu agenda
Apache Hudi Meetup - re:Invent
November 28th - December 3rd, Las Vegas
Apache Hudi es una tecnología de plataforma de datos que ayuda a crear lagos de datos confiables y escalables. Hudi lleva el procesamiento de flujo a big data, sobrecargando sus lagos de datos, haciéndolos mucho más eficientes.
Hudi es ampliamente utilizado por muchas empresas como Uber, Walmart, Amazon.com, Robinhood, GE, Disney Hotstar, Alibaba, ByteDance que construyen lagos de datos transaccionales o de transmisión. Hudi también viene prediseñado con Amazon EMR y está integrado con Amazon Athena, AWS Glue y Amazon Redshift. También está integrado en muchos otros proveedores de la nube, como la nube de Google y la nube de Alibaba.
Únase a la comunidad de Apache Hudi para una reunión organizada por Onehouse y la comunidad de Apache Hudi en el sitio de re:Invent. Aquí están los diferentes horarios y ubicaciones (hora local de Las Vegas):
- Nov 28th [7:00 pm - 7:20 pm] Networking
- Nov 28th [7:20 pm - 7:50 pm] Hudi 101 (Speaker TBA)
- Nov 28th [7:50 pm - 8:20 pm] How Hudi supercharges your lake house architecture with streaming and historical data by Vinoth Chandar
- Nov 28th [8:20 pm - 8:40 pm] Roadmap (Speaker TBA)
- Nov 28th [8:40 pm - 9:00 pm] Open floor for Q&A
Se llevará a cabo en la sala de conferencias "Chopin 2" en el Hotel Encore.
re:Invent
November 28th - December 3rd, Las Vegas
Re:Invent está a solo unas semanas de distancia, así que quiero compartir algunas cosas que espero sean de interés.
En primer lugar, ejecutaremos la transmisión Build On Live a lo largo de re:Invent y nos encantaría presentarte. Si usted mismo, o tal vez conoce a un miembro de la comunidad que va a re:Invent y cree que le encantará asistir a la transmisión en vivo, queremos saber de usted. Nomine a un miembro de la comunidad del que desee escuchar durante Build On Live utilizando esta encuesta.
En segundo lugar, consulte esta forma práctica de ver todas las increíbles sesiones de código abierto, luego consulte este panel [es necesario registrarse]. Me encantaría saber cuáles te entusiasman, así que házmelo saber en los comentarios o a través de Twitter. Si desea escuchar cuáles son mis tres sesiones principales, debe verlas, entonces esto es a lo que asistiría (lamentablemente, como empleado de AWS, no puedo asistir a las sesiones)
- OPN306 AWS Lambda Powertools: Lecciones del camino hacia los 10 millones de descargas: Heitor Lessa brindará una sesión increíble sobre el viaje desde la idea hasta una de las herramientas de código abierto más queridas y utilizadas para los usuarios de AWS Lambda.
- BOA204 Cuando la seguridad, la protección y la urgencia importan: Manejo de Log4Shell: no puedo esperar a esta sesión de Abbey Fuller, quien nos explicará cómo manejamos este incidente.
- OPN202 Mantenimiento de AWS Amplify Framework al aire libre: Matt Auerbach y Ashish Nanda compartirán detalles sobre cómo los gerentes de ingeniería de Amplify trabajan con la comunidad OSS para crear software de código abierto.
Hay muchas otras excelentes sesiones de código abierto y, con suerte, intentaré armar una lista más completa a medida que me acerque a re:Invent.
OpenSearch
Every other Tuesday, 3pm GMT
Esta reunión regular es para cualquier persona interesada en OpenSearch y Open Distro. Todos los niveles de habilidad son bienvenidos y cubren y dan la bienvenida a charlas sobre temas que incluyen: búsqueda, registro, análisis de registros y visualización de datos.
Regístrese para la próxima sesión, OpenSearch Community Meeting
Manténgase en contacto con el código abierto en AWS
Espero que este resumen haya sido útil. Recuerde consultar la página de inicio de Open Source para mantenerse actualizado al día con toda nuestra actividad en código abierto siguiéndonos en @AWSOpen





Latest comments (0)