November 21st, 2022 - Instalment #136
Welcome
Welcome to the AWS open source newsletter, edition #136, as featured on the latest episode of Build on Open Source. This week we feature new projects including "dynamoit" a JavaFX gui for Amazon DynamoDB, "building-apache-kafka-connectors", "msk-config-providers", and "msk-serverless-data-pipeline" projects to help make your life easier when working with Apache Kafka, "stowrs-to-s3" a tool for working with STOWRS data on AWS, "aws-device-lobby" a tool to make onboarding devices into AWS IoT Core easier, "aws-graviton-run-confidential-ml-workloads-using-nitro-enclaves" a nice example of how you can do Confidential Computing for machine learning use cases, "aws-hpc-builder" a tool to help you manage your open source HPC tools, and many more.
We also have AWS and community content covering some of your favourite open source projects, including Apache Kafka, Amazon Linux, Amazon EMR, Kubernetes, PostgreSQL, MySQL, Apache Airflow, GraphQL, Karpenter, Terraform, RabbitMQ, Prometheus, Redis, OpenSearch, AWS Amplify, Next.js, SpringBoot, Kubeflow, Krakatoa, XMesh, ffmpeg, and more.
Feedback
Please let me know how we can improve this newsletter as well as how AWS can better work with open source projects and technologies by completing this very short survey that will take you probably less than 30 seconds to complete. Thank you so much!
Celebrating open source contributors
The articles and projects shared in this newsletter are only possible thanks to the many contributors in open source. I would like to shout out and thank those folks who really do power open source and enable us all to learn and build on top of what they have created.
So thank you to the following open source heroes: Jonathan Swinney, Bharathi (Batty) Muthukrishnan, Conrad Wiebe, Evan Spearman, Subbusainath Rengasamy, Kartik Kalamadi, Rahul Kharse, Changbin Gong, Sandeep Palavalasa, Dan Mangum, Manabu McCloskey, Nima Kaviani, Kanwaljit Khurmi, James Eastham, Mike Jerome, Abhi Khanna, Ricardo Ferreira, Pavlo Iatsiuk, Jayaprakash Alawala, Paavan Mistry, Anton Babenko, Suresh Poopandi, Seb Kasprzak, Sheetal Joshi and Vipin Mohan.
Latest open source projects
The great thing about open source projects is that you can review the source code. If you like the look of these projects, make sure you that take a look at the code, and if it is useful to you, get in touch with the maintainer to provide feedback, suggestions or even submit a contribution.
Tools
dynamoit
dynamoit this project (love the name!) from Pavlo Iatsiuk is a simple DynamoDB graphical client written on JavaFX. This client allows easy viewing, editing, creating, and deleting of data.

building-apache-kafka-connectors
building-apache-kafka-connectors this repo from my colleague Ricardo Ferreira provides sample code that shows the important aspects of developing custom connectors for Kafka Connect. It provides the resources for building, deploying, and running the code on-premises using Docker, as well as running the code in the cloud. Building connectors for Apache Kafka is hard. Chances are that you just read the previous sentence, and you subconsciously nodded with your head. The reason this happens is that Kafka Connect, which is the runtime platform behind the executing connectors, uses a not so trivial software architecture. There is also a lack of a proper documentation that teaches how the development framework works, how it connects with the runtime, and which best practices you must follow. For situations like this, your best bet is to get hold of an existing code and try to do the same, hoping your own connector will be written the best way possible.
msk-config-providers
msk-config-providers In Apache Kafka, you can use the ConfigProvider class interface to prevent secrets from appearing in cleartext in connector configurations. This repository provides samples of Apache Kafka Config Providers that can be used to integrate Kafka client properties with other systems. It provides integration with AWS Secrets Manager, AWS Systems Manager Parameter Store, and Amazon S3.
stowrs-to-s3
stowrs-to-s3 STOW-RS is a standard specification for how to transfer images to target systems, typically used in medical imaging systems. This project is a Python based STOW-RS to S3 Service. This service receives DICOM PS18 compliant STOW-RS requests to store, and copies the data to a specified S3 bucket over parallel threads. This project can be deployed either in the AWS Cloud or on-premises. The project comes with an AWS CDK infrastructure as code package allowing to deploy it to the AWS Cloud easily, and can also be executed as a normal python process or as an OCI container ( eg. docker image ) if deployed on-premises.

aws-device-lobby
aws-device-lobby This solution provides a method for QR code onboarding of devices to AWS IoT Core. It simplifies the provisioning and onboarding process of devices by removing the requirement that an end cloud account/region is known at the time of device provisioning in the factory. This enables device makers to produce generic IoT devices not bound to end cloud services. IoT platform operators are then able to attach these devices to their services in the field in a flexible manner.

aws-hpc-builder
aws-hpc-builder is a universal HPC application(which is called module for the builder) build and management system that make it easy for you to compile and deploy HPC applications on Amazon Linux 2 and Amazon Linux 2022, which support all major platforms that are Intel/AMD/Graviton. This tool compiles HPC applications(WRF, VASP etc.) and their dependencies with vendor compilers or GNU compilers. It standardizes and modularizes the build procedure across all supported platforms.
Demos, Samples, Solutions and Workshops
deploy-stable-diffusion-model-on-amazon-sagemaker-endpoint
deploy-stable-diffusion-model-on-amazon-sagemaker-endpoint Stable Diffusion is a deep learning, text-to-image model that is similar to other applications such as Dall-E and Midjourney. It is primarily used to generate detailed images conditioned on text descriptions, and is getting a lot of interest at the moment. This repo contains notebooks that show you how you can deploy this onto Amazon Sagemaker so that you can start generating your own images.

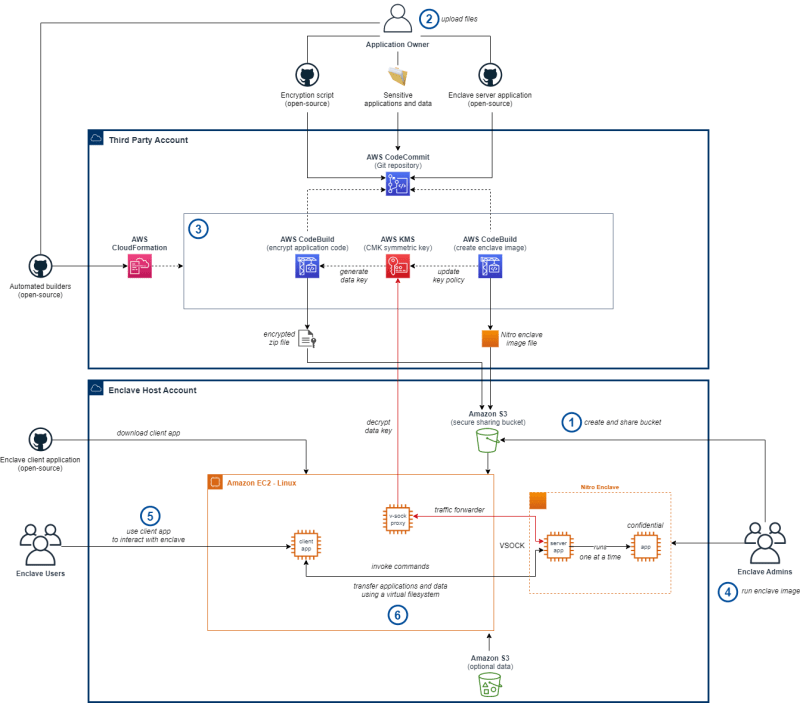
aws-graviton-run-confidential-ml-workloads-using-nitro-enclaves
aws-graviton-run-confidential-ml-workloads-using-nitro-enclaves Over the past three editions of this newsletter, we have seen more projects using AWS Nitro Enclaves. These have been either to show case use cases or to provide additional tooling to make it easier to use. AWS Nitro Enclaves enables customers to create isolated compute environments to maintain confidentiality of applications and data. The sample provided uses Nitro enclaves to enable sensitive file sharing and usage for ML workloads. The repo shows you how you can share your sensitive AI/ML files in a manner that safeguards application and data confidentiality. To present you with a familiar environment, we included the ability to do seamless data transfers to accelerate ML and DS workloads, as well as run software downloaded at runtime to process that data conveniently.
amazon-memorydb-for-redis-java-client-examples
amazon-memorydb-for-redis-java-client-examples This repository contains examples for using Java clients to interact with Amazon MemoryDB for Redis. These examples demonstrate the following, How to connect/disconnect to Amazon MemoryDB for Redis using the open-source Redis client Jedis, Add/update records to the database, Retrieve records by key and field/path, and Delete records by key.
msk-serverless-data-pipeline
msk-serverless-data-pipeline Serverless services allow us to build applications without having to worry about the underlying infrastructure. This allows developers to avoid provisioning, scaling, and managing resource utilisation. This repo contains code used in the workshop where you will build a serverless data pipeline using Amazon MSK Serverless which enables data to be consumed from many different client applications to accomplish downstream tasks such as dashboards and analytics. CloudFormation template will help you provision the infrastructure, then you will need to build the Java application yourself as the consumer.

AWS and Community blog posts
Terraform
AWS Hero Anton Babenko shared this update on LinkedIn about his aim on working on Serverless deployments on Terrform. Now thanks to Antons work, there is a new section on Serverless Land that allows you to filter the Serverless patterns for those who prefer using Terraform AWS modules. There are seven patterns currently, but Anton is working on more so make sure you connect/follow Anton so you keep up to date with these as they drop.
GraphQL
AWS Enthusiast Subbusainath Rengasamy has put together this blog post, How to create AWS AppSync with Lambda Authorizer using AWS CDK v2 with Nested Stack shows you how you can get started with GraphQL on AWS using AWS AppSync and AWS CDK. [hands on]

FFmpeg
FFmpeg is a free and open-source software project consisting of a suite of libraries and programs for handling video, audio, and other multimedia files and streams. I have used this tool many times in the past (one of my favourite uses is to stitch together pictures from my Raspberry Pi time lapse app into a nice movie). In the post, Optimized Video Encoding with FFmpeg on AWS Graviton Processors Jonathan Swinney explores how with recent improvements to the project, you can now run this in a more cost effective and more sustainable way using AWS Graviton instance types. Read the post to get the full low down.

Krakatoa and XMesh
Krakatoa and XMesh are part of a suite of AWS Thinkbox artist tools that simplify rendering, VFX, and simulation workflows. In the post AWS Thinkbox open sources Krakatoa MY and XMesh MY, Bharathi (Batty) Muthukrishnan, Conrad Wiebe, and Evan Spearman share more details about these plugins and how they are being used by customers. You might recognise some of the work from your favourite Boxsets.

Karpenter
In the post, Use Karpenter to speed up Amazon EMR on EKS autoscaling Changbin Gong and Sandeep Palavalasa shows how to integrate Karpenter into your Amazon EMR on EKS architecture to achieve faster and capacity-aware auto scaling capabilities to speed up your big data and machine learning (ML) workloads while reducing costs. [hands on]

Amazon Linux
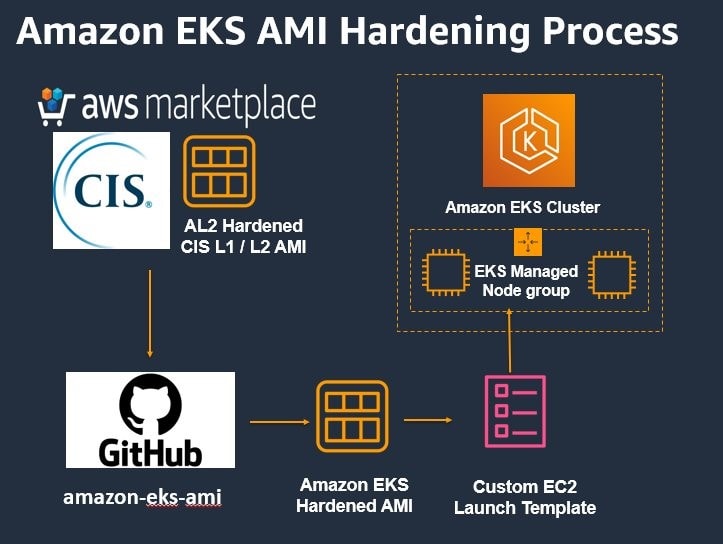
Center for Internet Security (CIS) Benchmarks are current good practices for the secure configuration of a target system. They define various Benchmarks for Kubernetes control plane and the data plane. In the post, Building Amazon Linux 2 CIS Benchmark AMIs for Amazon EKS Jayaprakash Alawala and Paavan Mistry share a detailed, step-by-step instructions on how customers can build an Amazon EKS Amazon Machine Image (AMI) compliant with the CIS Amazon Linux2 Benchmarks. [hands on]
Other posts and quick reads
- Automatically enable group metrics collection for Amazon EKS managed node groups shows you how to enable Auto Scaling group metrics collection for Amazon EKS managed node groups [hands on]

- Migrate ROW CHANGE TIMESTAMP from IBM Db2 for z/OS to Amazon RDS for PostgreSQL or Amazon Aurora PostgreSQL-Compatible Edition shows you how to migrate ROW CHANGE TIMESTAMP from Db2 for z/OS to Amazon RDS for PostgreSQL [hands on]
- Build an optimized self-service interactive analytics platform with Amazon EMR Studio shows you how to implement a self-service analytics platform with Amazon EMR and Amazon EMR Studio to improve the agility of your data science and data engineering teams without compromising on the security, scalability, resiliency, and cost efficiency of your big data workloads [hands on]

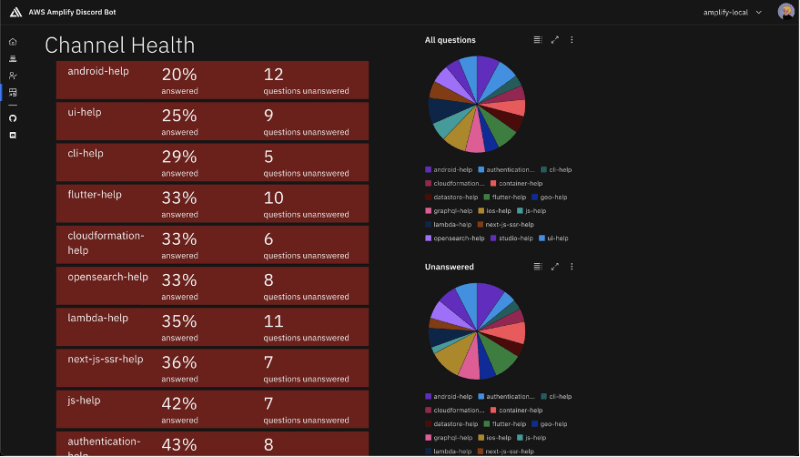
- AWS Amplify presents: “Hey, Amplify!” A Discord Bot looks at in more details a Discord bot aimed at improving the AWS Amplify community experience
Case Studies
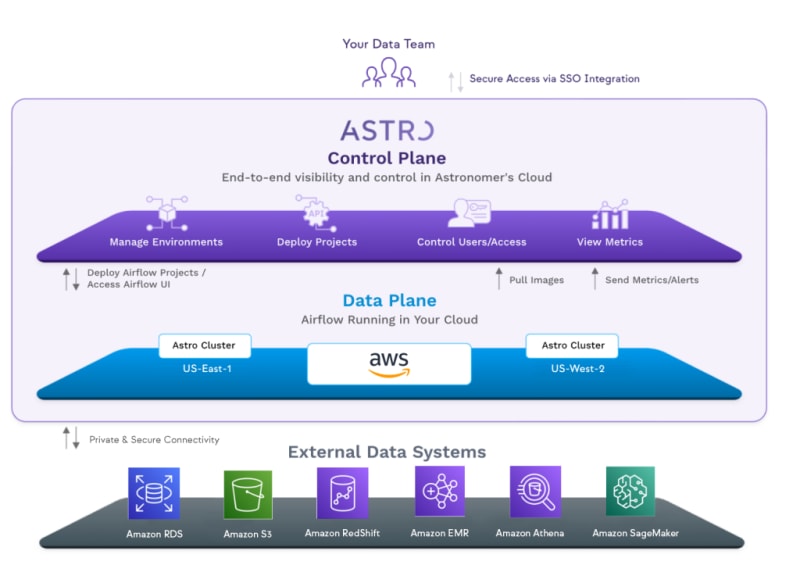
- Meet Astro — Astronomer’s managed Apache Airflow service built and hosted on AWS read more about how Astronomer have built their managed Apache Airflow service on AWS
Quick updates
Apache Airflow
Amazon Managed Workflows for Apache Airflow (MWAA) is now HIPAA (Health Insurance Portability and Accountability Act) eligible, something I know a lot of customers have been asking for. Amazon MWAA is a managed orchestration service for Apache Airflow that makes it easier to set up and operate end-to-end data pipelines in the cloud. HIPAA eligibility means that customers subject to HIPAA—including health insurance companies, healthcare providers, healthcare clearinghouses, government programs that pay for healthcare, military and veterans' health programs, as well as their associates—can now use Amazon MWAA to manage AWS workflows that store, process or transmit Protected Health Information (PHI). If you have a HIPAA Business Associate Addendum (BAA) in place with AWS, you can now start using Amazon MWAA for workflows handling PHI on new environments.
MySQL
Amazon Relational Database Service (Amazon RDS) for MySQL now supports MySQL minor version 8.0.31. We recommend that you upgrade to the latest minor versions to fix known security vulnerabilities in prior versions of MySQL, and to benefit from the numerous fixes, performance improvements, and new functionality added by the MySQL community.
Amazon Relational Database Service (Amazon RDS) for MySQL now supports MySQL minor version 5.7.40. We recommend that you upgrade to the latest minor versions to fix known security vulnerabilities in prior versions of MySQL, and to benefit from the numerous fixes, performance improvements, and new functionality added by the MySQL community.
PostgreSQL
Following the announcement of updates to the PostgreSQL database by the open source community, we have updated Amazon Aurora PostgreSQL-Compatible Edition to support PostgreSQL 14.5, 13.8, 12.12, and 11.17. These releases contain bug fixes and improvements by the PostgreSQL community. This release includes new features for Babelfish for Aurora PostgreSQL version 2.2. Refer to the Aurora version policy to help you to decide how often to upgrade and how to plan your upgrade process. As a reminder, if you are running any version of Amazon Aurora PostgreSQL 10, you must upgrade to a newer major version by January 31, 2023.
This release also contains an improvement for logical replication performance. This improvement, enabled as a write-through cache, will help improve the performance of Aurora PostgreSQL when continuously reading a logical replication stream (to minimise replication lag). Each replication slot can read recent data from the cache instead of Aurora Storage. In addition to performance improvements, the cache can help reduce I/O. The cache is available for Aurora PostgreSQL versions 14.5, 13.8, 12.12, and 11.17.
Kubernetes
A very busy week for Kubernetes updates.
First up was news that you can now use Amazon EKS and Amazon EKS Distro to run Kubernetes version 1.24.Notable changes in Kubernetes version 1.24 include containerd replacing Docksershim as the container runtime, a change to beta API behaviour, and topology aware hints for efficient traffic routing being enabled by default. Additionally, you should note that PodSecurityPolicy (PSP) is scheduled for removal in Kubernetes 1.25. For detailed information on these changes, see the EKS blog post and the Kubernetes project release notes. You can dive deeper by checking out the blog post, Amazon EKS now supports Kubernetes version 1.24 from Sheetal Joshi and Vipin Mohan.
The AWS Controllers for Kubernetes (ACK) for the Amazon EC2 service controller is now generally available. ACK lets you provision and manage EC2 networking resources, such as VPCs, SecurityGroups and Internet Gateways using the Kubernetes API. ACK lets you define and use AWS service resources directly from Kubernetes clusters. With ACK, you can take advantage of AWS managed services for your Kubernetes applications without needing to define resources outside of the cluster or run services that provide supporting capabilities like databases, message queues or instances within the cluster. ACK now supports 14 AWS service controllers as generally available with an additional 12 in preview.
Prometheus
Amazon Managed Service for Prometheus now supports 200M active metrics per workspace. Amazon Managed Service for Prometheus is a fully managed Prometheus-compatible monitoring service that makes it easy to monitor and alarm on operational metrics at scale. Prometheus is a Cloud Native Computing Foundation open source project for monitoring and alerting that is optimised for container environments such as Amazon EKS and Amazon ECS. With this release, customers can send up to 200M active metrics to a single workspace after filing a limit increase, and can create many workspaces per account, enabling the storage and analysis of billions of Prometheus metrics. Find out more by reading Amazon Managed Service for Prometheus adds support for 200M active metrics from Abhi Khanna.
AWS SAM
The AWS Serverless Application Model (SAM) Command Line Interface (CLI) announces the preview of AWS Lambda local testing and debugging on Terraform. The AWS SAM CLI is a developer tool that makes it easier to build, test, package, and deploy serverless applications. Terraform is an infrastructure as code tool that lets you build, change, and version cloud and on-premises resources safely and efficiently. Customers can now use the SAM CLI to locally test and debug a Lambda function defined in their Terraform application. SAM CLI can read the infrastructure resource information from the Terraform project and start Lambda functions locally in a docker container to invoke with an event payload, or attach a debugger using AWS toolkits on IDE to step through the Lambda function code. This feature is supported with Terraform version 1.1 +. For the most seamless experience, use it with the terraform-aws-modules/lambda version 4.6.1+. If you want to get hands on, then read Better together: AWS SAM CLI and HashiCorp Terraform
RabbitMQ
Amazon MQ now provides support for RabbitMQ version 3.10, a new release which includes several fixes and improvements to the previous versions of RabbitMQ supported by Amazon MQ, 3.8 and 3.9. With RabbitMQ 3.10, we have enabled support for the latest version of classic queues (CQv2) as default, which comes with memory and performance improvements. If you are running earlier versions of RabbitMQ such as 3.9 or 3.8, we strongly encourage you to upgrade to RabbitMQ 3.10. This can be accomplished with just a few clicks in the AWS Management Console. We also encourage you to enable automatic minor version upgrades on RabbitMQ 3.10 to help ensure your brokers take advantage of future fixes and improvements in 3.10.
Redis
Amazon ElastiCache now supports AWS Identity and Access Management (IAM) authentication access to Redis clusters. By using IAM, you can associate IAM users and roles with ElastiCache for Redis users and manage their cluster access. You can configure IAM authentication by creating an IAM-enabled ElastiCache user and then assigning this user to an appropriate ElastiCache user group via the AWS Management Console, AWS CLI, or the AWS SDK. Using IAM policies, you can grant or revoke cluster access to different IAM identities. Redis applications can now use IAM credentials to authenticate to your ElastiCache clusters while connecting to them.
OpenSearch
Amazon OpenSearch Service now supports OpenSearch and OpenSearch Dashboards version 2.3. With this version, Amazon OpenSearch Service adds several features such as new algorithms to the machine learning (ML) commons library, improvements to aggregations, improvements to map visualisations, alerting, anomaly detection, and more.
OpenSearch 2.3 uses Lucene 9.1, and the move to the latest version of Lucene offers a number of exciting advancements, and will continue to offer more value in future releases. Some of the improvements in OpenSearch Service that come with OpenSearch 2.3 (includes features that were launched as part OpenSearch versions 2.0, 2.1, and 2.2) include new ML algorithms that have been added to ML Commons such as Linear regression, Logistic Regression, Localisation, and RCFSummarise, support for Lucene-based k-NN search, and improved Dashboards user experience for anomaly detection. In addition, this release adds support for document-level alerting, support for multi-terms aggregation as part of OpenSearch core, the ability to upload custom GeoJSONs for region map visualisations and better zoom levels (14x), support for searching by relevance using SQL and PPL, centralised management of notifications on Dashboards, and more. For a complete list of new features and improvements, please see the release notes for OpenSearch versions 2.0, 2.1 2.2, and 2.3.
AWS Amplify & Next.js
Announced this week was AWS Amplify Hosting supports Next.js 12 and 13, including middleware, on-demand incremental static regeneration (ISR), and image optimization. With this release, AWS Amplify Hosting offers fully managed CI/CD deployments and hosting for server-side rendered (SSR) apps built using Next.js and static web apps. If you want to dip your toes into this, then check out this post Deploy a Next.js 13 app to AWS with Amplify Hosting from Mike Jerome [hands on].
Videos of the week
SpringBoot
SpringBoot is the most widely used application framework in Java, but did you know you can run your SpringBoot applications on AWS Lambda in as little as 10 minutes without changing a single line of code. In this video James Eastham dives into taking an existing Spring API and deploying that to AWS Lambda in 10 minutes using the AWS Serverless Application Model.
Kubeflow
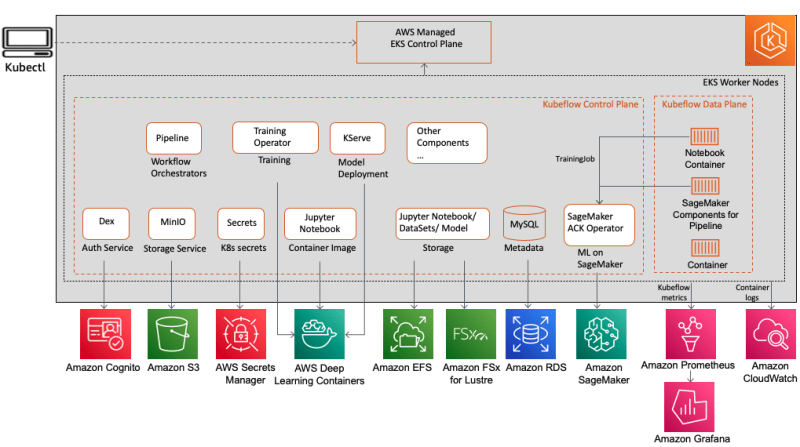
Your host Kanwaljit Khurmi explores Kubeflow basics, why it is used as a ML toolkit on Kubernetes, why customers love it and he demonstrates Kubeflow on AWS (an AWS-specific distribution of Kubeflow) and the value it adds to our customers through integration of highly optimised, cloud-native, enterprise-ready AWS services with Kubeflow.
Bonus
This week we also featured Kubeflow in the blog post, Enabling hybrid ML workflows on Amazon EKS and Amazon SageMaker with one-click Kubeflow on AWS deployment where Kanwaljit Khurmi, Kartik Kalamadi, and Rahul Kharse take a look at some of the Kubeflow release 1.6.1 features, and highlight three important integrations that you need to know about: infrastructure as code solutions to make it easier to deploy, support for distributed training on Amazon SageMaker, and enhanced monitoring and observability. [hands on]
Crossplane
The Containers from the Couch crew assemble with guest speaker Dan Mangum from Upbound, creators of Crossplane, as well as project maintainers Manabu McCloskey and Nima Kaviani from AWS, provide everything you need to know to get started with understanding and using Crossplane.
Build on Open Source
For those unfamiliar with this show, Build on Open Source is where we go over this newsletter and then invite special guests to dive deep into their open source project. Expect plenty of code, demos and hopefully laughs.
We have put together a playlist so that you can easily access all the other episodes of the Build on Open Source show. Build on Open Source playlist
Events for your diary
Apache Hudi Meetup - re:Invent
November 28th - December 3rd, Las Vegas
Apache Hudi is a data platform technology that helps build reliable and scalable data lakes. Hudi brings stream processing to big data, supercharging your data lakes, making them orders of magnitude more efficient.
Hudi is widely used by many companies like Uber, Walmart, Amazon.com, Robinhood, GE, Disney Hotstar, Alibaba, ByteDance that build transactional or streaming data lakes. Hudi also comes pre-built with Amazon EMR and is integrated with Amazon Athena, AWS Glue as well as Amazon Redshift. It is also integrated in many other cloud providers such as Google cloud and Alibaba cloud.
Please join the Apache Hudi community for a Meetup hosted by Onehouse and the Apache Hudi community at the re:Invent site. Here are the different times and locations (local Vegas time):
- Nov 28th [7:00 pm - 7:20 pm] Networking
- Nov 28th [7:20 pm - 7:50 pm] Hudi 101 (Speaker TBA)
- Nov 28th [7:50 pm - 8:20 pm] How Hudi supercharges your lake house architecture with streaming and historical data by Vinoth Chandar
- Nov 28th [8:20 pm - 8:40 pm] Roadmap (Speaker TBA)
- Nov 28th [8:40 pm - 9:00 pm] Open floor for Q&A
It will be hosted in Conference room “Chopin 2” at the Encore Hotel
re:Invent
November 28th - December 3rd, Las Vegas
re:Invent is only a few weeks away so I want to share a few things that will hopefully be of interest.
First up, we will be running the Build On Live stream throughout re:Invent and we would love to feature you! If either yourself, or perhaps you know a community member going to re:Invent and think they will absolutely love to attend the livestream, we want to hear from you. Please nominate a community member you want to hear from during Build On Live using this survey.
Second, check out this handy way to look at all the amazing open source sessions, then check out this dashboard [sign up required]. I would love to hear which ones you are excited about so please let me know in the comments or via Twitter. If you want to hear what my top three, must watch sessions, then this is what I would attend (sadly, as an AWS employee I am not allowed to attend sessions)
- OPN306 AWS Lambda Powertools: Lessons from the road to 10 million downloads - Heitor Lessa is going to deliver an amazing session on the journey from idea to one of the most loved and used open source tools for AWS Lambda users
- BOA204 When security, safety, and urgency all matter: Handling Log4Shell - Cannot wait for this session from Abbey Fuller who will walk us through how we managed this incident
- OPN202 Maintaining the AWS Amplify Framework in the open - Matt Auerbach and Ashish Nanda are going to share details on how Amplify engineering managers work with the OSS community to build open-source software
There are many other great open source sessions, and hopefully I will try and put together a more comprehensive list as approach re:Invent.
OpenSearch
Every other Tuesday, 3pm GMT
This regular meet-up is for anyone interested in OpenSearch & Open Distro. All skill levels are welcome and they cover and welcome talks on topics including: search, logging, log analytics, and data visualisation.
Sign up to the next session, OpenSearch Community Meeting
Stay in touch with open source at AWS
I hope this summary has been useful. Remember to check out the Open Source homepage to keep up to date with all our activity in open source by following us on @AWSOpen





Latest comments (0)