November 7th, 2022 - Instalment #134
Welcome
Welcome to the AWS open source newsletter, edition #134. This weeks newsletter was featured in the latest Build on Open Source on twitch.tv/aws, so I hope some of you were able to tune in and watch.
New projects that we featured include "enclaver", a toolkit to make working with enclaves easier, "s3crets_scanner" a new secrets scanning tool, "sandbox-accounts-for-events" a way to easily vend temporary environments, "frontend-discovery" helps you define and drive adoption of a frontend discovery patterns, "cf-sam-openapi-file-organization-demo", a tool to help you get started with API development, "decoupling-microservices-lambda-amazonmq-rabbitmq" a sample solution to get you started on how to use micro services with RabbitMQ, "how-to-write-more-correct-software-workshop" a workshop to get you developing better software, and more!
We also have content on AWS ParallelCluster, Apache Hudi, Apache Iceberg, Apache Flin, Hive, PrestoDB, Trino, Amazon EMR, Apache Kafka, Babelfish for Aurora PostgreSQL, Firecracker, MySQL, ArgoCD, PostgreSQL, Fluentbit, AWS Distro for OpenTelemetry, and more so be sure to check out all these great posts this week.
Finally, make sure you review the events section as there are plenty of open source events coming up on your radar over the coming weeks. I will be speaking at the Open Source Edinburgh event on Wednesday, so I hope to see some of you there.
Feedback
Please let me know how we can improve this newsletter as well as how AWS can better work with open source projects and technologies by completing this very short survey that will take you probably less than 30 seconds to complete. Thank you so much!
Celebrating open source contributors
The articles and projects shared in this newsletter are only possible thanks to the many contributors in open source. I would like to shout out and thank those folks who really do power open source and enable us all to learn and build on top of what they have created.
So thank you to the following open source heroes: John Russell, Beny Ibrani, Eilon Harel, Eugene Yahubovich, Richard Case, John Russell, Faizal Khan, Ashish Bhatia, Jagadeesh Chitikesi, Benson Kwong, Stanley Chukwuemeke, Baruch Assif Osoveskiy, and Kehinde Otubamowo
Latest open source projects
The great thing about open source projects is that you can review the source code. If you like the look of these projects, make sure you that take a look at the code, and if it is useful to you, get in touch with the maintainer to provide feedback, suggestions or even submit a contribution.
Tools
enclaver
enclaver is a new open source toolkit created to enable easy adoption of software enclaves (such as what is provided by AWS Nitro Enclaves), for new and existing backend software. Make sure you check the project documentation out which outlines in more detail some of the aspects of enclaves.
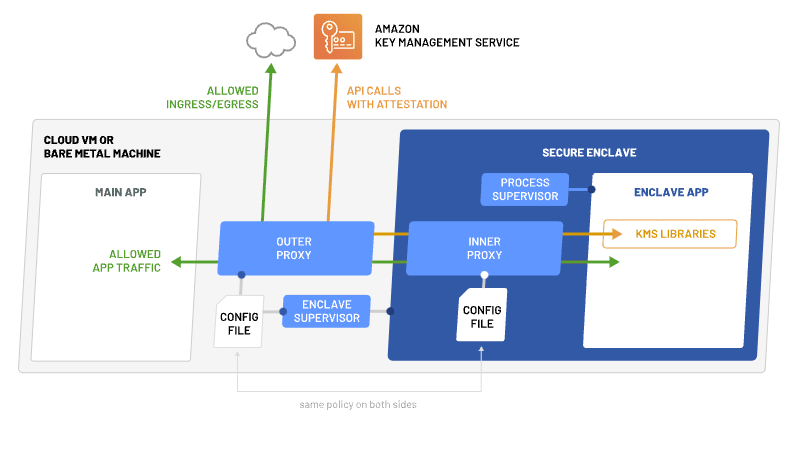
Eugene Yahubovich, the project founder has also put together a very nice blog post that dives deeper into use cases and how to get started. Go read, Introducing Enclaver: an open-source tool for building, testing and running code within secure enclaves. This weeks project of the week.
s3crets_scanner
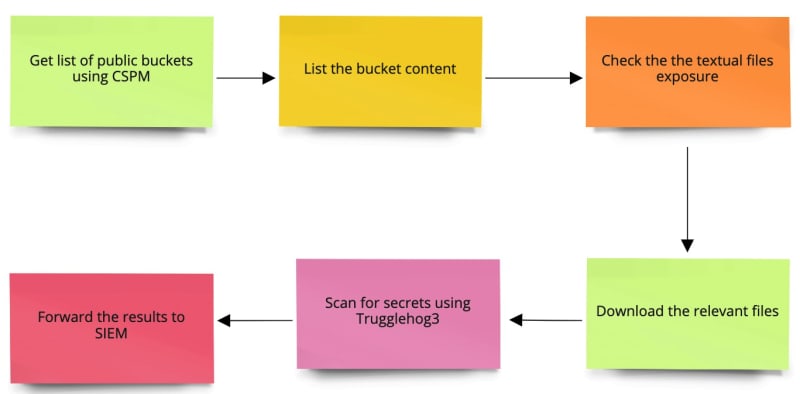
s3crets_scanner is an open source tool from Eilon Harel that is designed to provide a complementary layer for the Amazon S3 Security Best Practices by proactively hunting secrets in public S3 buckets. It can be executed as scheduled task or run On-Demand.

Eilon Harel has also put together a blog post diving deeper into this, in the post Hunting After Secrets Accidentally Uploaded To Public S3 Buckets
sandbox-accounts-for-events
sandbox-accounts-for-events "Sandbox Accounts for Events" allows to provide multiple, temporary AWS accounts to a number of authenticated users simultaneously via a browser-based GUI. It uses the concept of "leases" to create temporary access tickets and allows to define expiration periods as well as maximum budget spend per leased AWS account. Check out the docs for some example uses cases where you might find a tool like this useful, as well as understanding more how this works under the hood.

frontend-discovery
frontend-discovery The aim of this project is to define and drive adoption of a frontend discovery pattern, with a primary focus on client-side rendered (CSR), server-side rendered (SSR) and edge-side rendered (ESR) micro-frontends. The frontend discovery pattern improves the development experience when developing, testing, and delivering micro-frontends by making use of a shareable configuration describing the entry point of micro-frontends, as well as additional metadata that can be used to deploy in every environment safely.
Check out the readme to find out more about the motives behind the project, and dive into it with an example.
Demos, Samples, Solutions and Workshops
mapper-for-fhir
mapper-for-fhir FHIR is a standard for health care data exchange, and this repo provides assets that allow for the automated deployment of an HL7v2, leveraging native AWS services. The repo provides a CDK application that simplifies deployment.
cf-sam-openapi-file-organization-demo
cf-sam-openapi-file-organization-demo The project is the API back-end for a widget tracking website. Widget tracking is simplistic - widgets have only a unique name and a colour descriptor for properties. If you want to explore how to approach API design, then this is a good repo to explore.

sam-accelerate-nested-stacks-demo
sam-accelerate-nested-stacks-demo This repository shows how to use CloudFormation nested stacks with AWS SAM Accelerate. Nested stacks are stacks created as part of other stacks. In this demo repo, there are four separate stacks that make up the entire solution. AWS SAM manages all four as CloudFormation nested stacks. During development, we show how to use SAM Accelerate to quickly update resources, shortening the development loop.
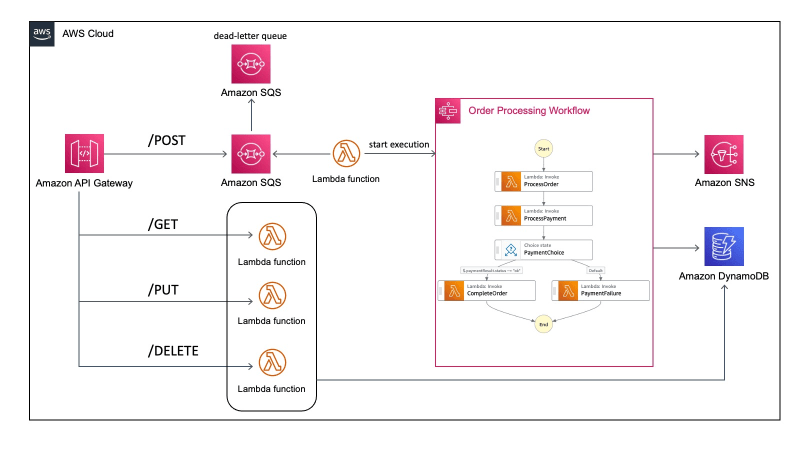
decoupling-microservices-lambda-amazonmq-rabbitmq
decoupling-microservices-lambda-amazonmq-rabbitmq This project is a solution architecture that demonstrates decoupling micro services with Amazon MQ for RabbitMQ and AWS Lambda. A decoupled application architecture allows each component to perform its tasks independently and a change in one service shouldn't require a change in the other services.

how-to-write-more-correct-software-workshop
how-to-write-more-correct-software-workshop so last week I featured duvet, a tool to help you codify and automate validation of your software against honouring RFC specs. This repo contains a workshop that walks you through a practical example of that, but also features dafny, a programming language that formally verifies your implementation matches your specification. I have this on my weekend to do list.
AWS and Community blog posts
Kubernetes
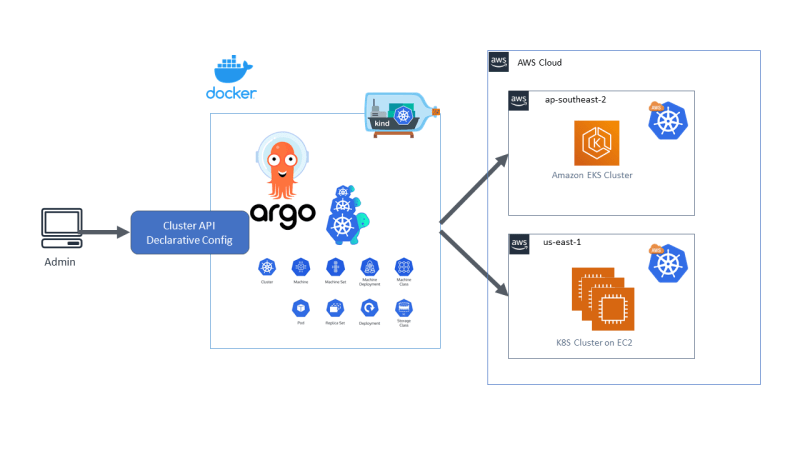
Benson Kwong has been busy putting this blog post together, Multi-cluster management for Kubernetes with Cluster API and Argo CD where he introduces what Cluster API is and explained why you can use this useful tool for managing multiple Kubernetes clusters instead of struggling with different APIs and tool sets to maintain them. He also covers how you can also integrate ArgoCD to add that sprinkle of continuous delivery with Git as your source of truth. [hands on]
CoreWCF
CoreWCF is a port of the service side of Windows Communication Foundation (WCF) to .NET Core. The goal of this project is to enable existing WCF services to move to .NET Core. In the post, Running your modern CoreWCF application on AWS Ashish Bhatia and Jagadeesh Chitikesi show you how to deploy a CoreWCF application on an Amazon Linux Graviton2 instance. [hands on]
MySQL
In the post, Enable change data capture on Amazon RDS for MySQL applications that are using XA transactions Stanley Chukwuemeke, Baruch Assif Osoveskiy, and Kehinde Otubamowo have collaborated to present a solution to safely replicate change streams from a MySQL database using XA transactions, to down stream OpenSearch. [hands on]

Other posts and quick reads
- Create a Multi-Region Python Package Publishing Pipeline with AWS CDK and CodePipeline walks you through how to deploy a CodePipeline pipeline to automate the publishing of Python packages to multiple CodeArtifact repositories in separate regions [hands on]

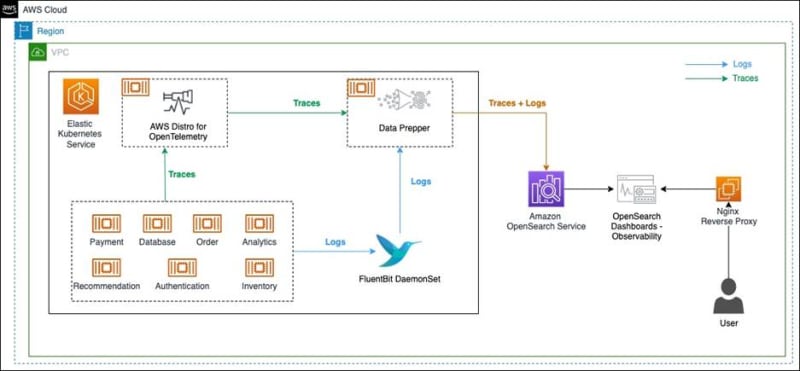
- Microservice observability with Amazon OpenSearch Service part 1: Trace and log correlation is a two part blog that uses a sample micro service to show you how you can implement observability using a number of open source tools such as Fluentbit, AWS Distro for OpenTelemetry, and OpenSearch [hands on]
- Migrate Oracle hierarchical queries to Amazon Aurora PostgreSQL demonstrates via sample queries how you can migrate Oracle hierarchical queries using a number of keywords to PostgreSQL [hands on]
- What to consider when modernizing APIs with GraphQL on AWS provides a good primer on how GraphQL works and how integrating it with AWS services can help you build modern applications
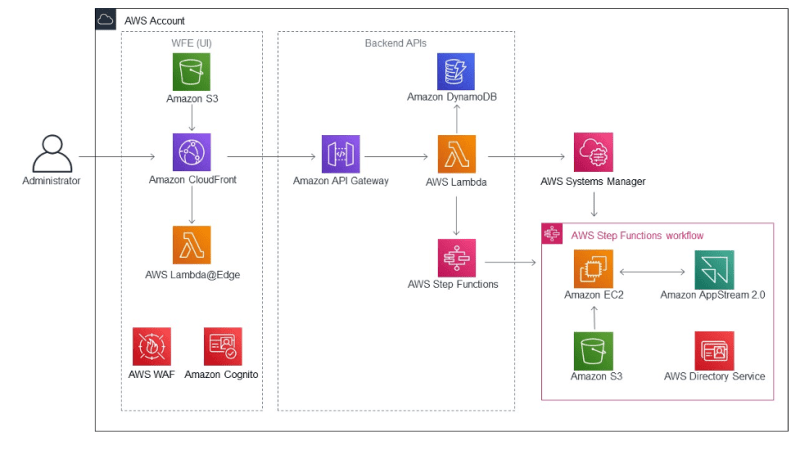
- Managing Computer Labs on Amazon AppStream 2.0 with Open Source Virtual Application Management provides a hands on guide to using an open source project previously featured in this newsletter, to help administrators programmatically create AppStream 2.0 images [hands on]
Quick updates
PHP
AWS App Runner now supports PHP 8.1, Go 1.18, .Net 6, and Ruby 3.1 managed runtimes for building and running web applications and APIs. These runtimes enable you to leverage the App Runner “build from source” capability to build and deploy directly from your source code repository without needing to learn the internals of building and managing your own container images.
Starting today, you can build and run your services based on PHP 8.1, Go 1.18, .Net 6, and Ruby 3.1 directly from your source code on App Runner. All these new managed runtimes in App Runner are active long-term support (LTS) major versions.
Apache Kafka
Amazon Managed Streaming for Apache Kafka (MSK) now offers Tiered storage that brings a virtually unlimited and low-cost storage tier. Tiered Storage lets you store and process data using the same Kafka APIs and clients , while saving your storage costs by 50% or more over existing MSK storage options . Tiered Storage makes it easy and cost-effective when you need a longer safety buffer to handle unexpected processing delays or build new stream processing applications. You can now scale your compute and storage independently, simplifying operations.
Amazon MSK Connect also now supports Private DNS hostnames for enhanced security. With Private DNS hostname support in MSK Connect, you can configure connectors to reference public or private domain names. Connectors will use the DNS servers configured in your VPC’s DHCP option set to resolve domain names. You can now use MSK Connect to privately connect with databases, data warehouses and other resources in your VPC to comply with your security needs.
Amazon EMR
Amazon EMR 6.8 has seen a number of updates that you should be aware of.
PrestoDB and Trino
With PrestoDB and Trino on EMR 6.8, users benefit from a configuration setting, called the strict mode that prevents cost overruns due to long running queries.Customers have told us that poorly written SQL queries can sometimes run for long times, and consume resources from other business critical workloads. To help administrators take action on such queries, we are introducing strict mode setting that allows warning or rejecting certain types of queries. Examples include queries without predicates on partitioned columns that result in large table scans, or queries that involve cross join between large tables, and/or queries that sort large number of rows without limit. You can set up strict mode configuration during cluster creation and also override the setting using session properties. You can apply strict mode checks for select, insert, create table as select and explain analyse query types.
We are also excited to announce that Amazon EMR PrestoDB and Trino has added a new features to handle spot interruptions that helps run your queries cost effectively and reliably. Spot Instances in Amazon EMR allows you to run big data workloads on spare Amazon EC2 capacity at a reduced cost compared to On-Demand instances. However, Amazon EC2 can interrupt spot instances with a two-minute notification. PrestoDB/Trino queries fail when spot nodes are terminated. This has meant that customers were unable to run such workloads on spot instances and take advantage of lower costs. In EMR 6.7, we added a new capability to PrestoDB/Trino engine to detect spot interruptions and determine if the existing queries can complete within two minutes on those nodes. If the queries cannot finish, we fail quickly and retry the queries on different nodes. Amazon EMR PrestoDB/Trino engine also does not schedule new queries on spot nodes that are about to be reclaimed. With these two new features, you will get best of both worlds - improved resiliency with PrestoDB/Trino engine on Amazon EMR, and running queries economically on spot nodes.
Hive
Hive users run Metastore check command with the repair table option (MSCK REPAIR table) to update the partition metadata in the Hive metastore for partitions that were directly added to or removed from the file system (S3 or HDFS). When run, MSCK repair command must make a file system call to check if the partition exists for each partition. This step could take a long time if the table has thousands of partitions. In EMR 6.5, we introduced an optimisation to MSCK repair command in Hive to reduce the number of S3 file system calls when fetching partitions . This feature improves performance of MSCK command (~15-20x on 10k+ partitions) due to reduced number of file system calls especially when working on tables with large number of partitions. Previously, you had to enable this feature by explicitly setting a flag. Starting with Amazon EMR 6.8, we further reduced the number of S3 filesystem calls to make MSCK repair run faster and enabled this feature by default.
In addition to MSCK repair table optimisation, we also like to share that Amazon EMR Hive users can now use Parquet modular encryption to encrypt and authenticate sensitive information in Parquet files. It is a challenging task to protect the privacy and integrity of sensitive data at scale while keeping the Parquet functionality intact. Data protection solutions such as encrypting files or storage layer are currently used to encrypt Parquet files, however, they could lead to performance degradation. With Parquet modular encryption, you can not only enable granular access control but also preserve the Parquet optimisations such as columnar projection, predicate pushdown, encoding and compression. Using Parquet modular encryption, Amazon EMR Hive users can protect both Parquet data and metadata, use different encryption keys for different columns, and perform partial encryption of only sensitive columns. It also allows clients to check integrity of the data retrieved while keeping all Parquet optimisations.
Apache Flink
Amazon EMR includes Apache Flink 1.15.1. This feature is available on EMR on EC2.
Apache Flink is an open source framework and engine for processing data streams. Apache Flink 1.15.1 on EMR 6.8 includes 62 bug fixes, vulnerability fixes, and minor improvements over Flink 1.15.0. Key features include:
Watermark alignment (Beta) across data sources : Event-time processing in Flink depends on special timestamped elements, called watermarks, that are inserted into the stream either by the data sources or by a watermark generator. A watermark with a timestamp t can be understood as an assertion that all events with timestamps < t have already arrived. Watermark alignment is useful when processing sources with different velocity of events e.g. when one source is idle or one source emits records relatively faster than others, you can enable watermark alignment for each source separately. Flink aligns watermarks by pausing the highest velocity source and continuing to read records from other sources until the watermarks are aligned.
SQL version upgrade : Introducing JSON plans which are JSON functions that make it easier to import and export structured data in SQL. Today, version upgrades can alter the topology of SQL queries which can introduce snapshot incompatibility across versions. This makes upgrading Flink versions challenging. With this feature, both the Table API and SQL will provide a way to compile and execute a plan ensuring the same topology for SQL queries throughout different versions, making it more reliable to upgrade to future versions. Users who want to give it a try can create a JSON plan that can then be used to restore a Flink job based on the old operator structure.
Apache Hudi and Apache Iceberg
Amazon EMR release 6.8 now supports Apache Hudi 0.11.1 and Apache Iceberg 0.14.0. You can use these frameworks on Amazon EMR on EC2, and Amazon EMR on EKS as well as on Amazon EMR Serverless.
Apache Hudi 0.11.1 on Amazon EMR 6.8 includes support for Spark 3.3.0, adds Multi-Modal Index support and Data Skipping with Metadata Table that allows adding bloom filter and column stats indexes to tables which can significantly improve query performance, adds an Async Indexer service which allows users to create different kinds of indices (e.g., files, bloom filters, and column stats) in the metadata table without blocking ingestion, includes Spark SQL improvements adding support for update or delete records in Hudi tables using non-primary-key fields and Time travel query via timestamp as of syntax, includes Flink integration improvements with support for both Flink 1.13.x and 1.14.x and support for complex data types such as Map and Array etc. In addition, Hudi 0.11.1 includes bug fixes over Hudi 0.11.0 available in Amazon EMR release 6.7.
Apache Iceberg 0.14.0 on Amazon EMR 6.8 includes support for Spark 3.3.0, adds Merge-on-read support for MERGE and UPDATE statements, adds support to rewrite partitions using Z-order that allows to re-organize partitions to be efficient with query predicates on multiple columns and also to keep similar data together, includes several performance improvements for scan planning in Spark queries, add support for row group skipping using Parquet bloom filters, etc.
AWS ParallelCluster
AWS ParallelCluster 3.3 is now generally available and introduces a new feature for compute resource optimisation. With this new feature, you can map a compute resource to a list of Amazon EC2 instance types with an allocation strategy to optimize compute capacity for your HPC jobs. Other features include updates that support dynamically mounting shared storage, Slurm accounting, and Amazon EC2 on demand capacity reservations (ODCR).
Check out the announcement for more details, AWS ParallelCluster 3.3: multiple instance type allocation and other top requested features
Matt Vaughn has also published a blog post, Support for Instance Allocation Flexibility in AWS ParallelCluster 3.3, where he explains in detail how a new feature that was also announced called “multiple instance type allocation” in ParallelCluster 3.3.0. This feature enables you to specify multiple instance types to use when scaling up the compute resources for a Slurm job queue. Your HPC workloads will have more paths forward to get access to the EC2 capacity they need, helping you to get more computing done.
Videos of the week
Firecracker
In this lightening talk from KubeCon, Richard Case from SUSE brings you up to speed with what microVMs are, how they can be useful and provides plenty of examples. This is great stuff for having a better understanding of then how you might use Firecracker, an open source microVM project from AWS.
Babelfish for Aurora PostgreSQL
Join fellow Developer Advocate John Russell as he shows you how to set up a database server using the combination of Babelfish and Aurora, connect to the database, and run both PostgreSQL and T-SQL statements. Babelfish for PostgreSQL is an open source project that provides a compatibility layer for the SQL dialect (T-SQL) used by Microsoft SQL Server. Babelfish helps migrate database applications onto PostgreSQL with minimal changes to the application code.
Build on Open Source
For those unfamiliar with this show, Build on Open Source is where we go over this newsletter and then invite special guests to dive deep into their open source project. Expect plenty of code, demos and hopefully laughs.
We have put together a playlist so that you can easily access all the other episodes of the Build on Open Source show. Build on Open Source playlist
Events for your diary
OpenSearch - Development Backlog & Triage Meeting Security
7th November - 12pm PT
The OpenSearch engineering team working on the Security repo have opened up their Backlog & Triage meetings to the public. This is a great opportunity to find out more about the inner workings of open source projects such as OpenSearch. Don't worry if you cannot make this meeting as they are currently scheduled from the 7th of November out through Dec 19th.
Check out the entire list here.
Open Source & AWS IoT
7th November, 4pm IST
Internet of Things and other categories of hardware devices with edge computing capabilities that communicate over the internet to perform remote actions require a stable, easy-to-use and, most importantly, secure operating software that can be audited independently. In this session, the presenter will look at ways that AWS supports and contributes to the open-source community to make these devices more resilient and feature-rich through solutions such as AWS Greengrass and AWS IoT Core.
AWS Hero Faizal Khan will be your host, and you can sign up via the registration page here.
Open Source Edinburgh
9th November, 5:30pm Scott Logic in Edinburgh
I will be talking at the Open Source Edinburgh meet-up this week, and you can find details on the location and how to reserve your spot by clicking on the meetup.com link. Hope to see some of you there.
Running Open Source Transcoding Server on Amazon EKS
Friday, 18th, 19:00 WIB
Join Beny Ibrani and the AWS User Group Indonesia for this session (local language I believe) where Beny will show you how you can use open source transcoding software running on Amazon EKS.
This session will be streamed on YouTube, so check it out here
Build on AWS Open Source
November 18th, 9am BST
Join us for the sixth episode of the Build on AWS series, featuring a live round up of the latest projects and news as well as a special guest speaker. We have another special guest lined up, and we will announce this next week. Follow the show on @buildonopen for more details. Check it out on https://twitch.tv/aws
AWS Elastic Kubernetes Service (EKS) Workshop
November 10th, London 5pm
Join us for an interactive workshop on containers, Docker, Fargate and Amazon EKS, hosted by ClearScale and AWS. This live, virtual workshop includes three hours of interactive presentation and hands-on lab work. You will take part in the setup and deployment of containers using EKS. Follow along and work directly with AWS professionals and ClearScale (an AWS Premier Tier Services Partner) in this Level 200 training session.
You can find out more about this event by checking out the event page and signing up.
re:Invent
November 28th - December 3rd, Las Vegas
re:Invent is only a few weeks away so I want to share a few things that will hopefully be of interest.
First up, we will be running the Build On Live stream throughout re:Invent and we would love to feature you! If either yourself, or perhaps you know a community member going to re:Invent and think they will absolutely love to attend the livestream, we want to hear from you. Please nominate a community member you want to hear from during Build On Live using this survey.
Second, check out this handy way to look at all the amazing open source sessions, then check out this dashboard [sign up required]. I would love to hear which ones you are excited about so please let me know in the comments or via Twitter. If you want to hear what my top three, must watch sessions, then this is what I would attend (sadly, as an AWS employee I am not allowed to attend sessions)
- OPN306 AWS Lambda Powertools: Lessons from the road to 10 million downloads - Heitor Lessa is going to deliver an amazing session on the journey from idea to one of the most loved and used open source tools for AWS Lambda users
- BOA204 When security, safety, and urgency all matter: Handling Log4Shell - Cannot wait for this session from Abbey Fuller who will walk us through how we managed this incident
- OPN202 Maintaining the AWS Amplify Framework in the open - Matt Auerbach and Ashish Nanda are going to share details on how Amplify engineering managers work with the OSS community to build open-source software
There are many other great open source sessions, and hopefully I will try and put together a more comprehensive list as approach re:Invent.
OpenSearch
Every other Tuesday, 3pm GMT
This regular meet-up is for anyone interested in OpenSearch & Open Distro. All skill levels are welcome and they cover and welcome talks on topics including: search, logging, log analytics, and data visualisation.
Sign up to the next session, OpenSearch Community Meeting
Stay in touch with open source at AWS
I hope this summary has been useful. Remember to check out the Open Source homepage to keep up to date with all our activity in open source by following us on @AWSOpen





Top comments (1)
Amazing job!!! thx for share again!