
Silos
Most organisations that process data will have experienced the concept of data in silos. This is where an application is built for a particular purpose and tied to a data store. While this may solve a particular business problem, as time passes developers and engineers may start to spend time extracting data from these silos for other purposes such as analytics and machine learning.
If you are lucky your teams might have provided API's to access the data, but what if that API is missing two key fields that you need or returns too much data?
For older software that is using a relational database for its data store its more likely that the software is using SQL with JDBC/ODBC and you might not have an API available.
Pulling disparate datasets together to present them for new projects can be time consuming. Engineers also have to deal with application modernisation projects such breaking up monoliths as part of a cloud migration. Keeping the lights on whilst providing a path to making your architecture cloud friendly is a delicate balancing act.
This post looks into GraphQL, specifically the AWS implementation via AppSync and how it can be used to help:
- Provide a flexible API for developers
- Join data from silos together
- Provide a migration path for application modernisation by moving some data into DynamoDB while keeping some in a RDBMS.
What's GraphQL?
Organizations choose to build APIs with GraphQL because it gives developers the ability to query multiple databases, microservices, and APIs with a single GraphQL endpoint.
What's AppSync?
AWS AppSync is a fully managed service that makes it easy to develop GraphQL APIs. Out of the box it allows connections to data sources like AWS DynamoDB, Lambda, and more.
Data Sources
In this example we will provide a unified API that is able to query data from the following data stores:
- DynamoDB - Representing a fairly new cloud native application.
- RDS - Representing a traditional 3 tier app that has been migrated to the cloud.
- Lambda - Representing a serverless application.
Throughout we'll use dummy/test vehicle data that we want to bring together.
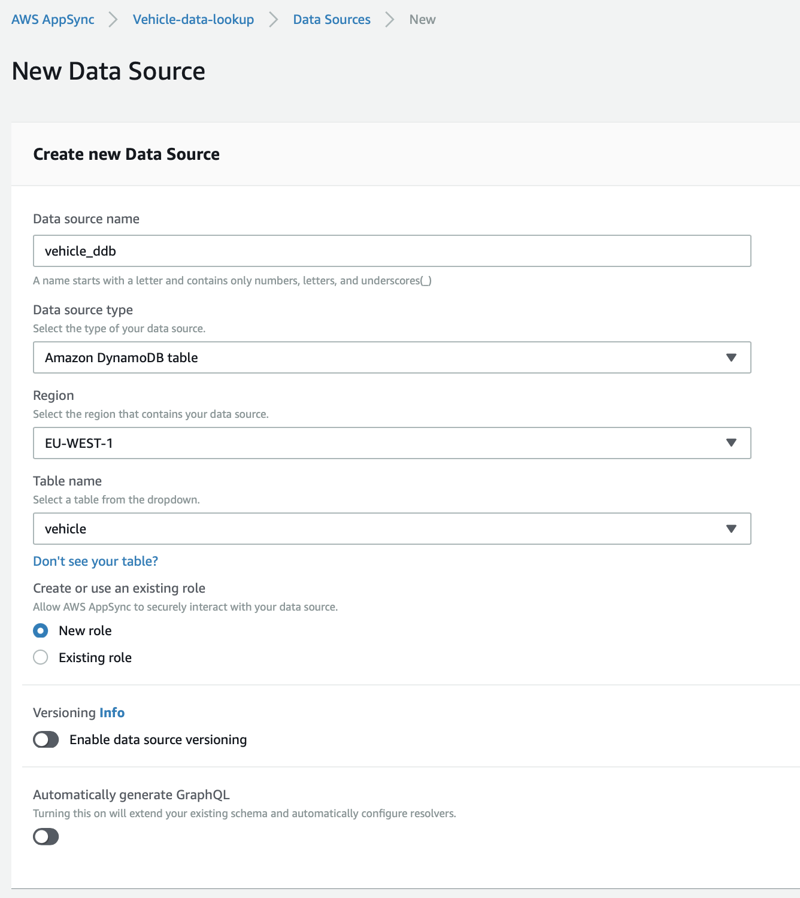
DynamoDB
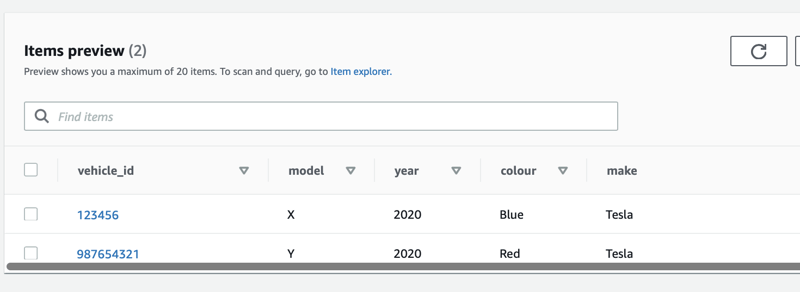
Create a table named vehicle. The key is vehicle_id (string).
Add some test data by adding a couple of items.
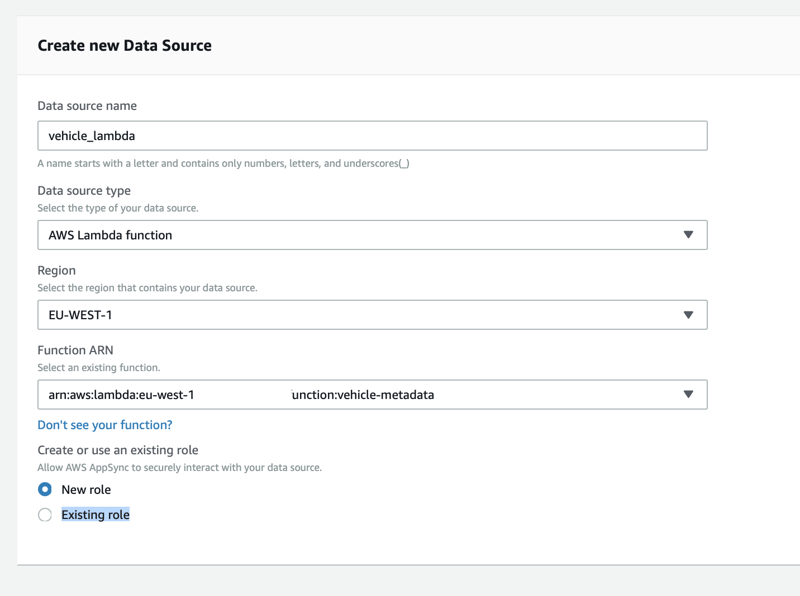
Lambda
We now create a quick Lambda that will mock returning some data for a vehicle_id.
The lambda code is shown below.
import json
print('Loading function')
def lambda_handler(event, context):
print (json.dumps(event))
print (context)
vehicle_id={}
vehicle_id=event['source']['vehicle_id']
print(vehicle_id)
vehicles = {
"123456" : { "vehicle_id" : "123456", "fuel" : "electric", "category": "SUV" },
"987654321" : { "vehicle_id" : "987654321", "fuel": "hybrid", "category": "Saloon"}
}
print(vehicles[vehicle_id])
return (vehicles[vehicle_id])
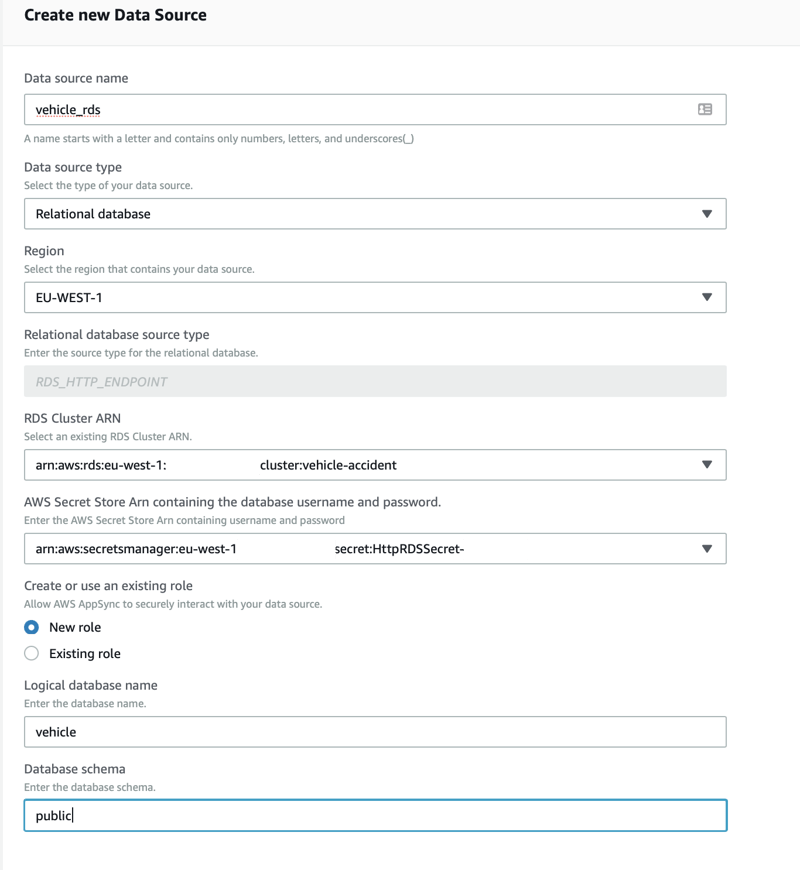
RDS (Aurora PostgreSQL)
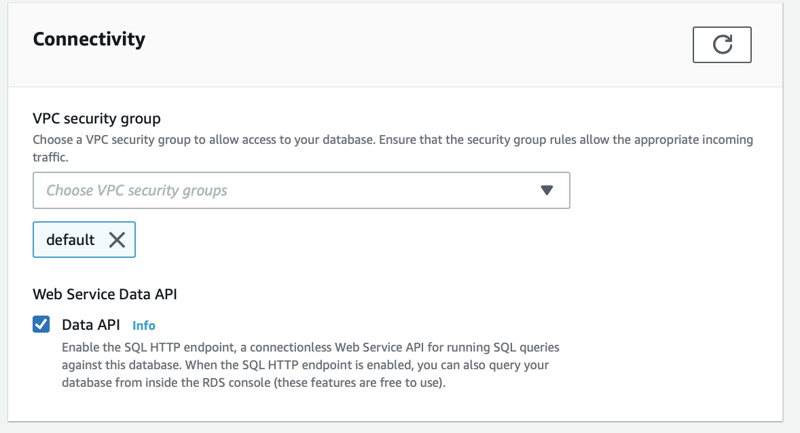
Out of the box AppSync supports Aurora Serverles RDS instances. Create an RDS Aurora PostgreSQL instance named vehicle-accident.
It's important to enable the Data API feature which is a connectionless Web Service API for running SQL queries against the database.
Once the instance has been created, connect to it using the RDS query editor and run the following SQL.
create table accident (
vehicle_id varchar,
accident_date date,
damage varchar,
cost integer);
insert into accident values (123456, '2020-11-23 18:00:00', 'windscreen smashed', 100);
insert into accident values (987654321, '2020-11-24 18:00:00', 'dent in front passenger door', 600);
commit;
In order for AppSync to connect to RDS later we need to store database credentials in AWS Secrets Manager.
Create a file names creds.json with the database credentials in.
{
"username": "xxxxxxxxxxxxxx",
"password": "xxxxxxxxxxxxxx"
}
Add the credentials using the AWS CLI.
aws secretsmanager create-secret --name HttpRDSSecret --secret-string file://creds.json --region eu-west-1
Make a note of the ARN returned as this is needed later.
Create The GraphQL API
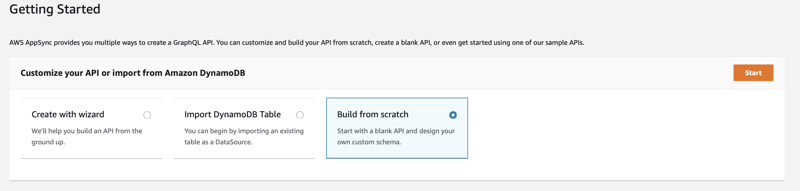
From the AppSync console select build from scratch.
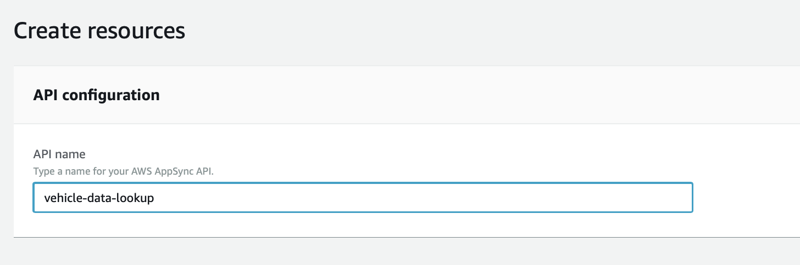
Give your API a name.
Schema
Click edit schema.
Add the following schema.
type Query {
#Get a single vehicle.
singleVehicle(vehicle_id: String): Vehicle
}
type Vehicle {
vehicle_id: String
model: String
year: String
colour: String
make: String
fuel: String
category: String
accident_date: String
accident_damage: String
accident_cost: String
}
schema {
query: Query
}
Data Sources
Next we define the three data sources. DynamoDB, RDS and Lambda. Click Data Sources and add them one by one.
Resolvers
DynamoDB
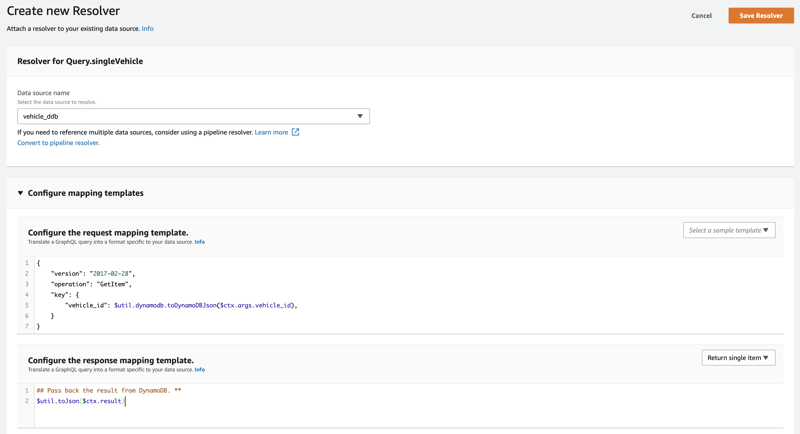
Back on the Schema screen select Attach for the resolver of "singleVehicle(...): Vehicle"
Select vehicle_ddb as the data source and add the following for the request mapping temple.
{
"version": "2017-02-28",
"operation": "GetItem",
"key": {
"vehicle_id": $util.dynamodb.toDynamoDBJson($ctx.args.vehicle_id),
}
And the following for the response template.
## Pass back the result from DynamoDB. **
$util.toJson($ctx.result)
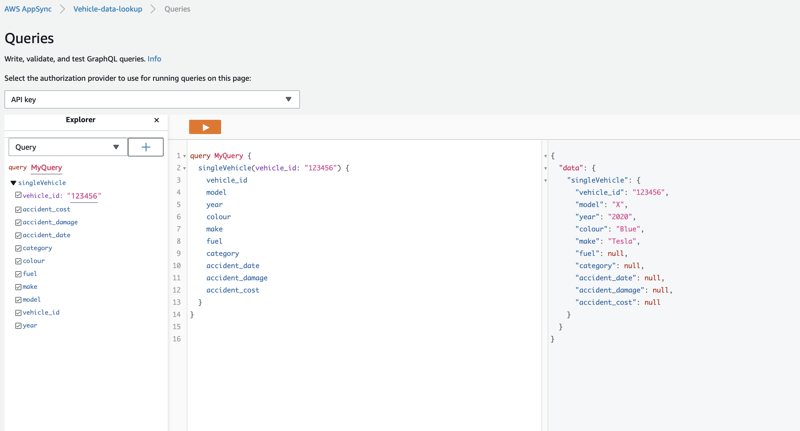
At this point the data for some of the defined schema will be able to be queried. You can check this on the query screen of AppSync.
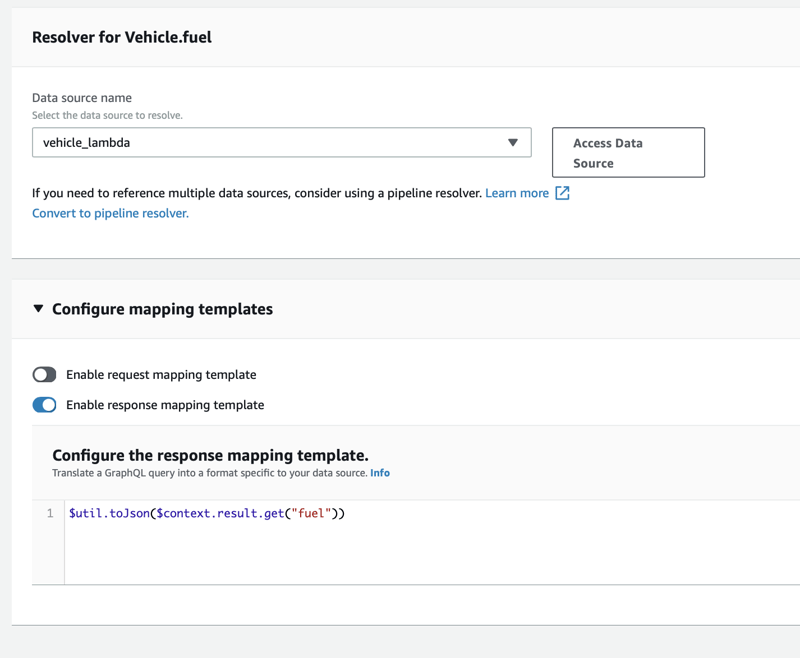
Lambda
On the schema definition screen scroll down to the fuel field and click attach.
Select the lambda function created earlier and enable the response mapping template with and add the following.
$util.toJson($context.result.get("fuel"))
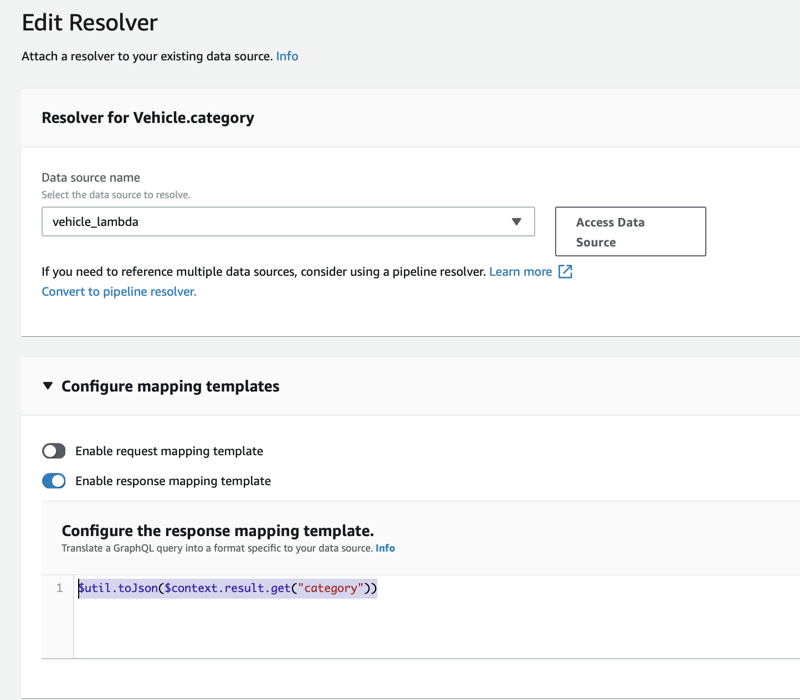
Repeat these steps for the category field. The response mapping template should be defined as follows.
$util.toJson($context.result.get("category"))
RDS
On the schema definition screen scroll down to the accident_date field and click attach.
Select the RDS database created earlier. Configure the request mapping template as follows.
{
"version": "2018-05-29",
"statements": [
$util.toJson("select accident_date from accident WHERE vehicle_id = '$ctx.source.vehicle_id'")
]
}
Specify the response mapping template as below.
#if($ctx.error)
$util.error($ctx.error.message, $ctx.error.type)
#end
#set($output = $utils.rds.toJsonObject($ctx.result)[0])
## Make sure to handle instances where fields are null
## or don't exist according to your business logic
#foreach( $item in $output )
#set($accident_date = $item.get('accident_date'))
#end
$util.toJson($accident_date)
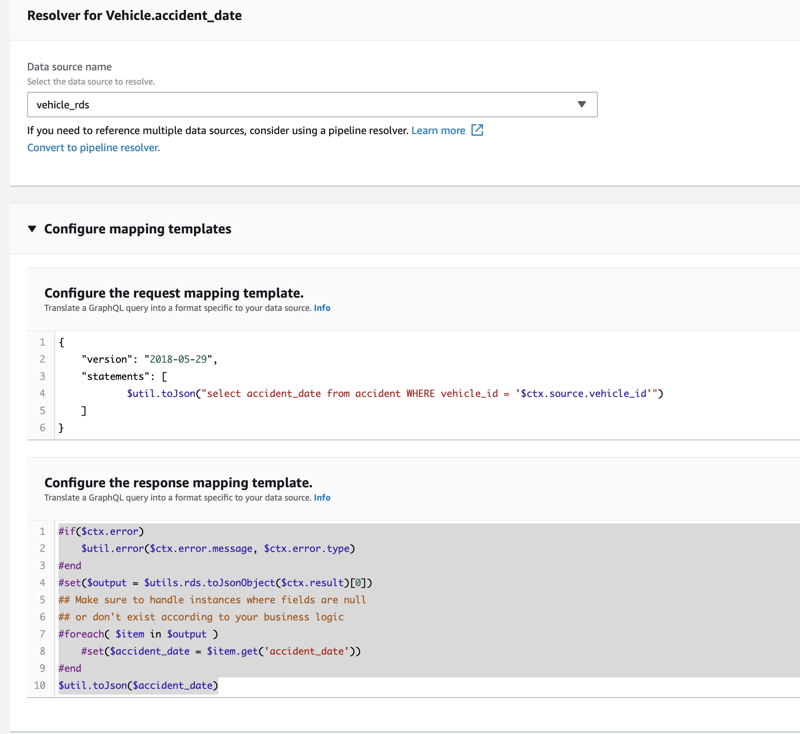
Repeat these steps for the accident_damage and accident_cost fields. The request and response mapping templates are shown below.
{
"version": "2018-05-29",
"statements": [
$util.toJson("select damage from accident WHERE vehicle_id = '$ctx.source.vehicle_id'")
]
}
#if($ctx.error)
$util.error($ctx.error.message, $ctx.error.type)
#end
#set($output = $utils.rds.toJsonObject($ctx.result)[0])
## Make sure to handle instances where fields are null
## or don't exist according to your business logic
#foreach( $item in $output )
#set($damage = $item.get('damage'))
#end
$util.toJson($damage)
{
"version": "2018-05-29",
"statements": [
$util.toJson("select cost from accident WHERE vehicle_id = '$ctx.source.vehicle_id'")
]
}
#if($ctx.error)
$util.error($ctx.error.message, $ctx.error.type)
#end
#set($output = $utils.rds.toJsonObject($ctx.result)[0])
## Make sure to handle instances where fields are null
## or don't exist according to your business logic
#foreach( $item in $output )
#set($cost = $item.get('cost'))
#end
$util.toJson($cost)
Query
The three data sources are now in place to resolve all the fields for our API. Go back to the query screen and check that the fields all get populated when you run a query.

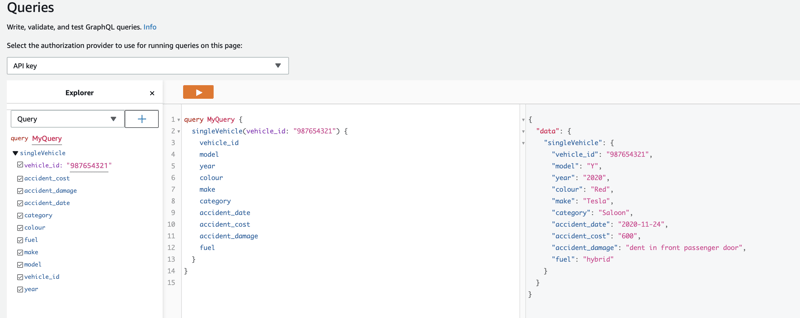
Tips
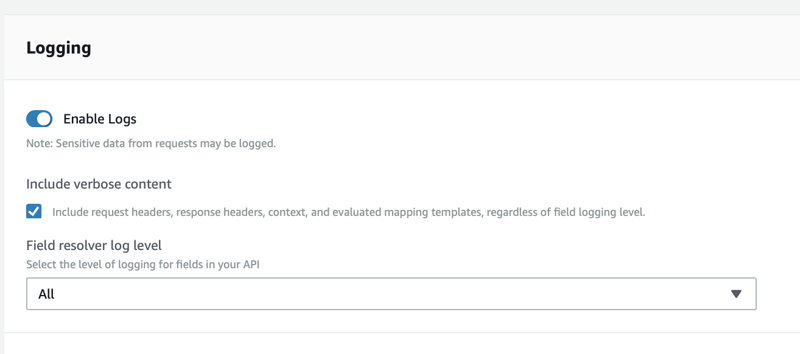
Turn on CloudWatch Logs so you can see details of any errors. You can do this under settings.
The following webpages were useful to me getting started with this demo.
https://adrianhall.github.io/cloud/2019/01/03/early-return-from-graphql-resolvers/
https://stackoverflow.com/questions/58031076/aws-appsync-rds-util-rds-tojsonobject-nested-objects





Oldest comments (0)