
One of the main trends due to the advances in the industry in relation to artificial intelligence is to give access to people without the need to have an academic or technical background in the area of computer science, mathematics, or statistics. Moreover, the goal of large companies linked to the design and implementation of solutions based on artificial intelligence is to create platforms, which through simple steps and a friendly interface, manage to deploy AI solutions, machine learning, or even deep learning, bringing such tools to certain departments within an organization, streamlining and achieving greater accuracy when making decisions.
In the following publication we are going to show the Amazon Sagemaker CANVAS service, functionality that is born under the concept of No code, where you can load data from your local computer, or connect any database already deployed in AWS, analyze and transform your dataset (feature engineering), building the best model you can achieve with your data, generate predictions, either in batch or singular form, also review distinct metrics that allow you to analyze the performance of the models developed by CANVAS. To explore the service in detail, we will use a customer churn dataset to build a binary classification model, without writing any line of code, showing the main advantages of the service.
Setting up the service
The Amazon Sagemaker CANVAS service is located in the Sagemaker console, where one must click and create a user for the service:

When creating a user, we must complete the information requested in the panel, and then wait for the successful creation of the user:
Once the user has been created, we launch the CANVAS application:


Main interface
Once the application is launched, the initial interface is shown below, where the option to create our first model is explicitly enabled.

CANVAS addresses the 4 main technical stages of a modeling process for a machine learning algorithm, by this we mean, feature engineering, i.e. the process of analyzing, visualizing, cleaning, and transforming the features that will enter the model, then configuring the type of model to perform the training (binary or multiple classification problem, regression, or time series), then displaying dashboards with the training evaluation showing general metrics as well as the impact of each variable to finally make predictions. In other words, this tool performs the fundamental steps to deploy a machine learning solution in a customized way, but at the same time automatically, without requiring code syntax or elaborate advanced data preprocessing functions. Below is an overview of each stage, generated by the tool itself when it is the first time you run a solution in the service

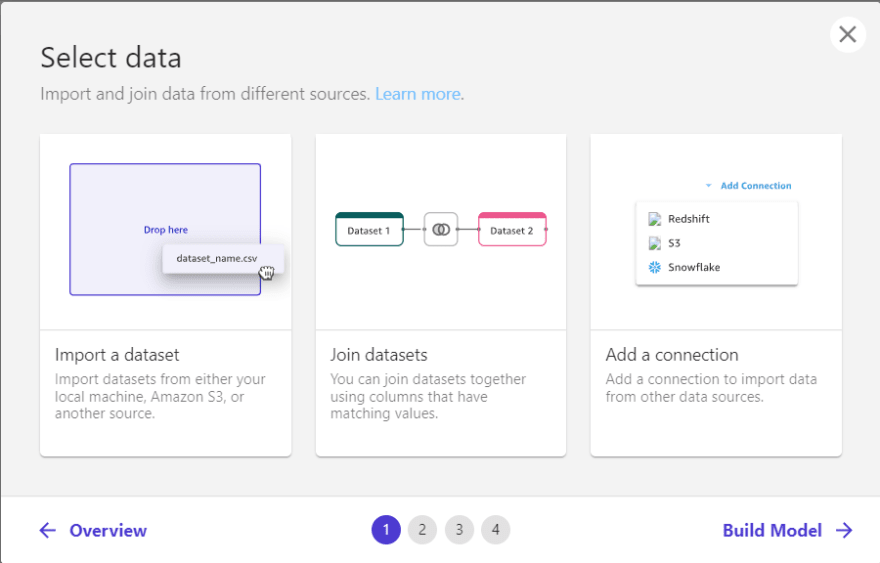

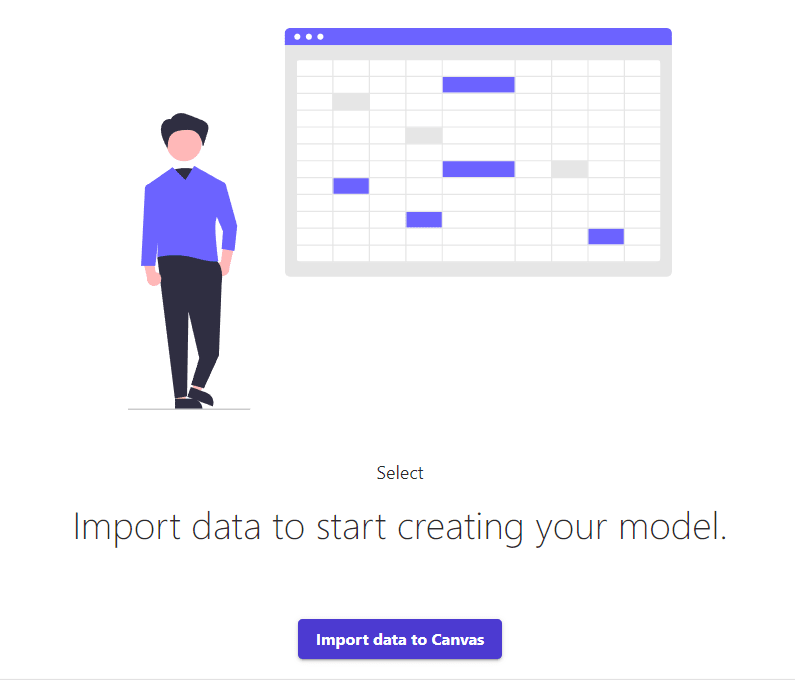
First step: Load data
Already introduced the main concepts of Sagemaker CANVAS, we will begin the exploration of each stage. The first is to load our data, where we have two options, the first is to connect data from services such as S3 or another database within the AWS ecosystem, and the other option is to load data from your laptop, being this option chosen by me, requiring additional configuration to enable this feature that will be explained below:
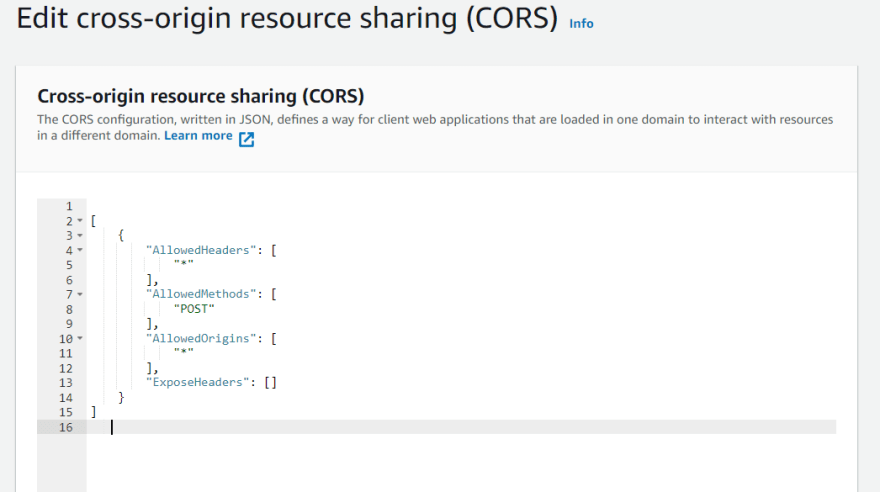
Additional: Setting of bucket for import local data
As shown in the following figure, a policy must be added to the default bucket offered by S3 for the sagemaker service, adding special permissions to enable local uploading. (This process is guided by the application, directing you to the link with the necessary documentation to complete the process).

Finally
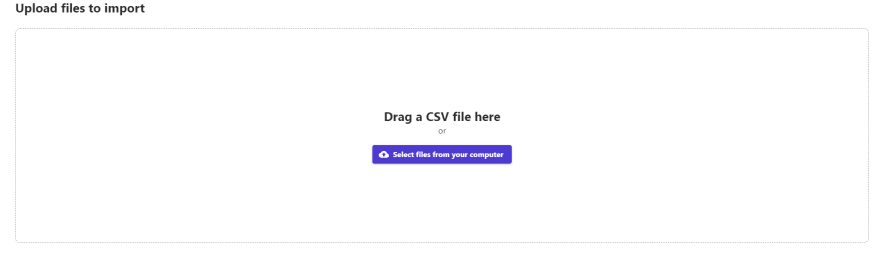
After loading the information, you can see the header of the dataset. It is recommended to use comma-separated value files.
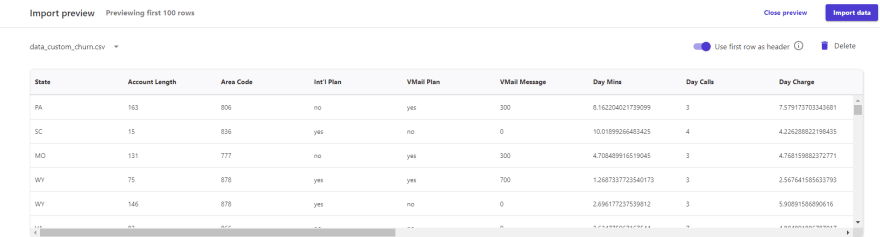
Next, we select the dataset and start the build stage.
Build
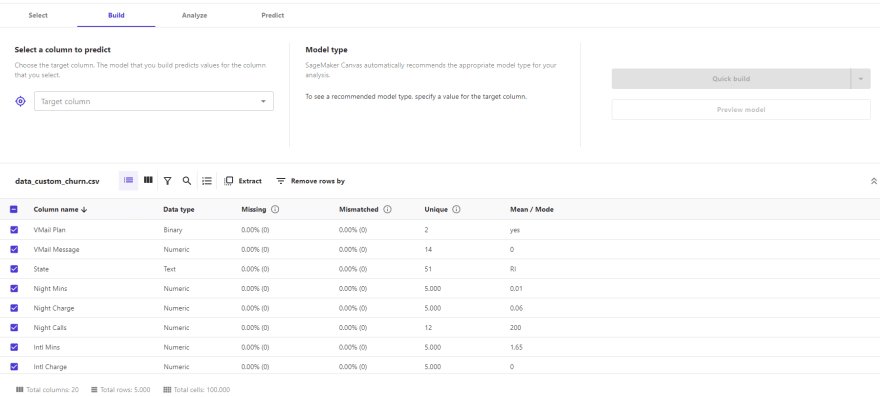
In this step, we proceed to analyze our data sets, where a table with basic, but no less important, information about the condition of our variables is immediately displayed. We can see the missing values, and unique values of each column, in the case of a categorical variable this is understood as the cardinality of the variable, as well as other descriptive indicators of the data set.
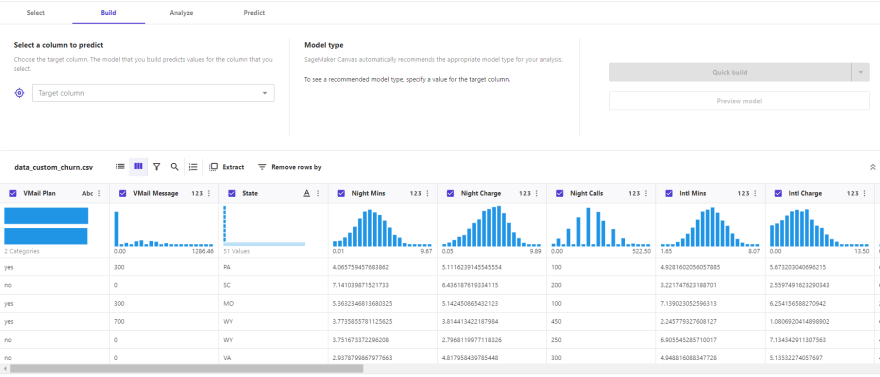
We also have another way to visualize the data, whereby by means of graphs we can see the distribution of each column present in the dataset.
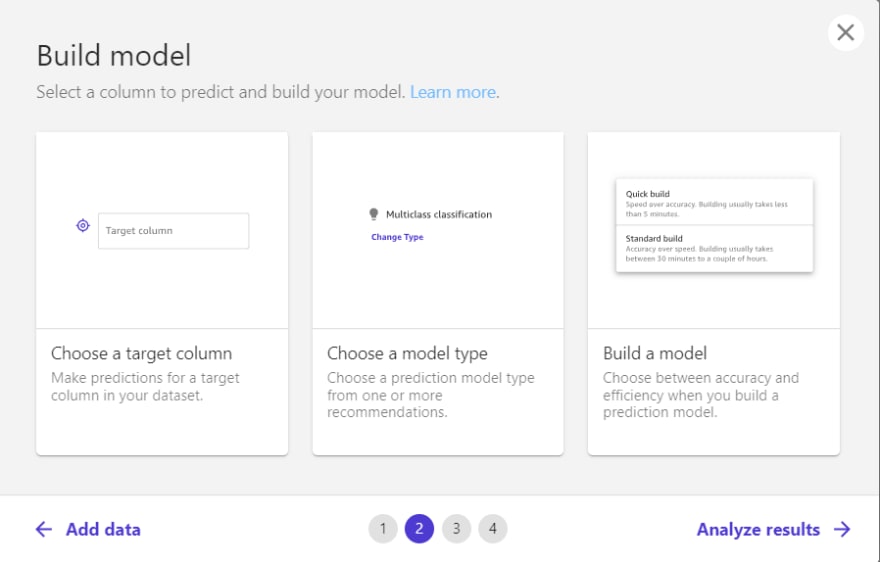
Another feature that CANVAS offers is to select the target variable, i.e. what we want to answer with our model, for this example is whether or not the customer abandons a service. In addition, we can drop the columns that are not considered as part of the training of the classification algorithm, all this only by clicks, no code. For this example, we do not consider 2 columns of the total attributes of the dataset.
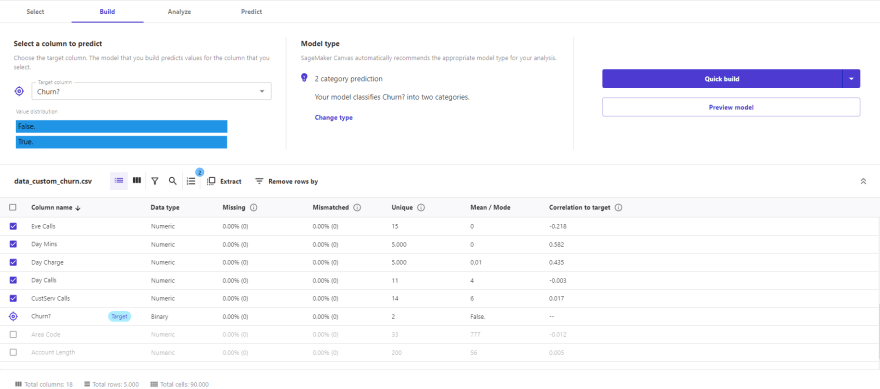
Also, we can review and change the type model to employ
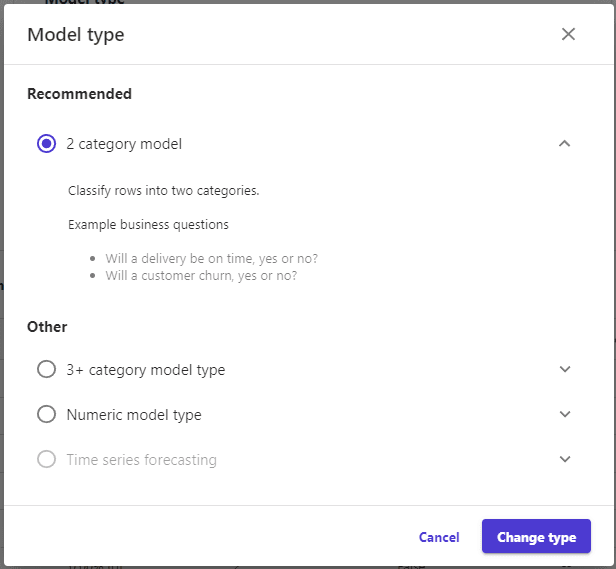
With the settings defined, a model preview is displayed in the lower right part of the screen, i.e. a model built quickly indicating the first partial values of training, with speed prevailing over the accuracy, adding the impact of the variables in the model fitting process, allowing to obtain which variable is relevant in the learning process. For our data set and the problem to be modeled the results are encouraging even bordering on overfitting.
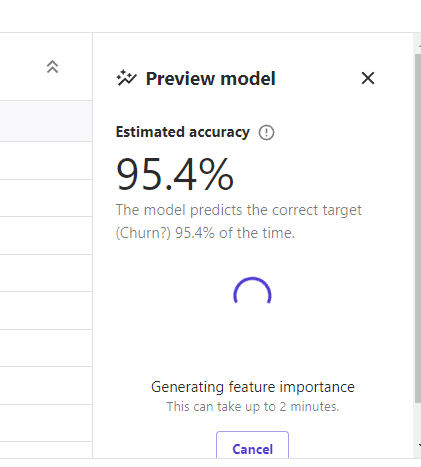
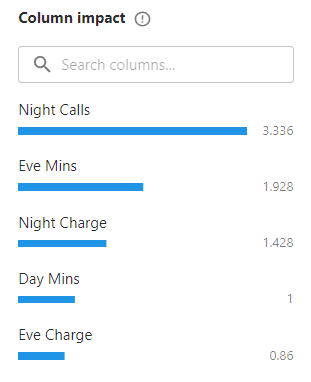
The last action at this stage is to define the final training task, and for that, there are two ways to generate this predictor. One option is to create a model in a fast way but probably will not reach an adequate accuracy (in this case in a fast way if good performance is reached), and the other option is to consider a training where it prevails to reach a good accuracy metric, but taking a longer adjustment time, where this decision depends purely on the user.

Analize
After indicating the type of training in the previous step, a third window is enabled that will allow us to see the results of the training at a general level, that is, by means of metrics typical of a classification problem, as well as at the variable level, where we can see the response and performance of each variable against our target variable, for the latter, different graphs are displayed to understand the process.
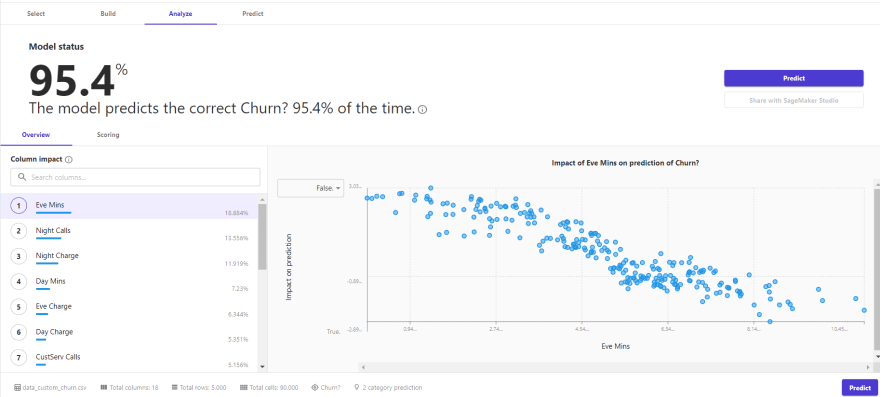
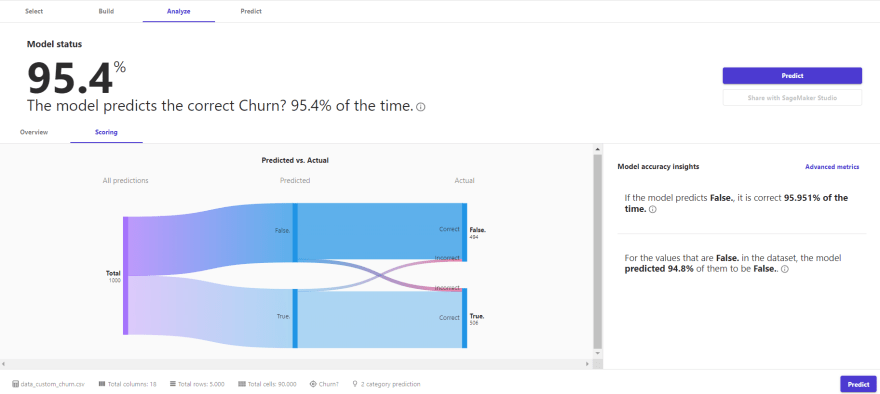
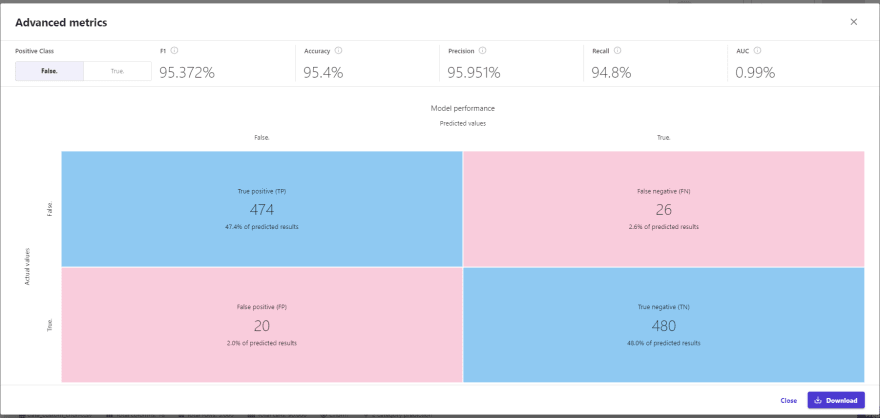
For our example, we can see a very good performance in all the metrics offered for a classification problem, i.e. Accuracy, Recall, F1 Score, and even the AUC of the model. Again I reiterate that the analysis and importance of each metric depend on the modeled phenomenon, and what is the cost of error in the business for a prediction.
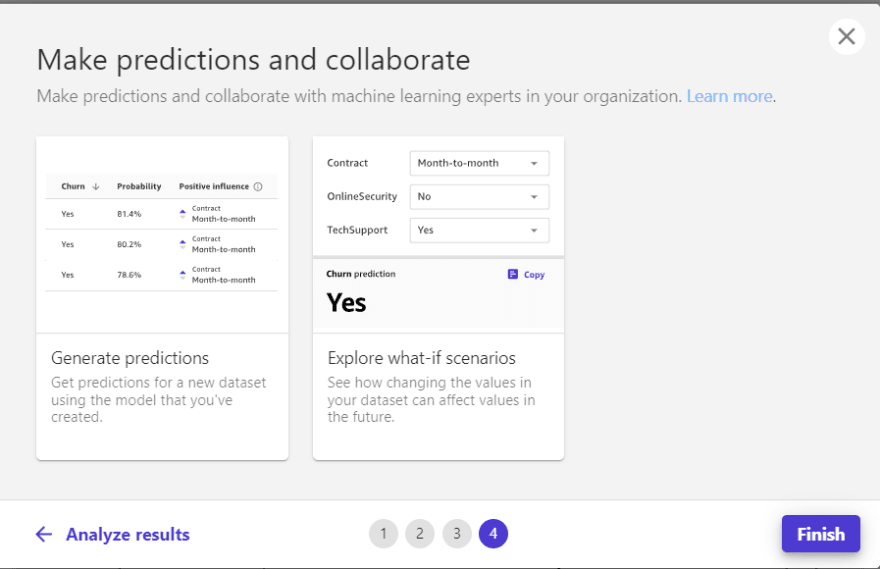
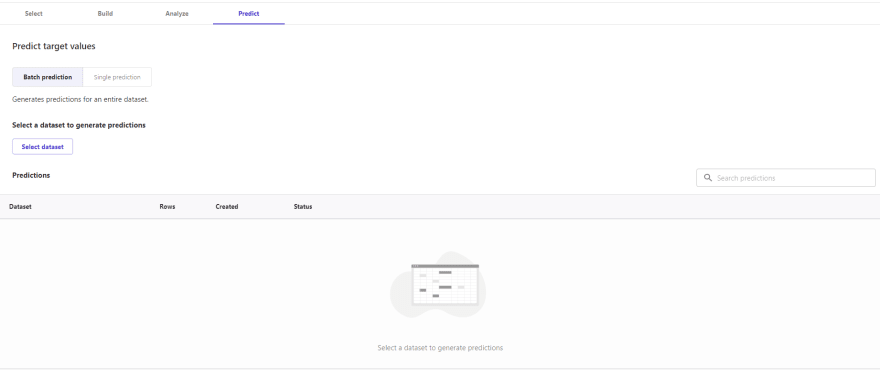
Predict
Finally, once a model has been built, there is the option to generate predictions at both batch and single levels. For batch predictions, a sample containing the attributes considered in the training process is needed, while to test singular predictions, it is possible to modify the values of each variable in a panel, showing the model prediction.

Discussion and conclusion
With this exercise we reviewed each step of the Amazon Sagemaker CANVAS service, discovering a great tool to develop machine learning solutions under the concept of not code, allowing us to create classification, regression, and time-series models. At each stage natural questions arise for a model developer, such as what algorithms to consider in each type of problem, for example, does XGBoost use for classification problems? what portion of data is used for training and testing? or how is the performance for a classification problem with unbalanced labels? and other unknowns associated with each stage of the process offered by CANVAS. However, regardless of those questions, it is a great tool, which above all brings people closer to creating their artificial intelligence models, in particular machine learning models.





Top comments (0)