
Introduction
In the previous blog, an Amazon Neptune cluster was created using Amazon CloudFormation template with pre-configured AWS services in the Sydney region with a click of a button to create a quickstart stack in just 25 minutes.
This included automation with pre-selected AWS Service options including EC2 instances, DB cluster endpoint, IAM Neptune DB access to S3 bucket, cluster endpoints etc. which I think are more suitable for a large dataset in a production environment. Because in production, CloudFormation pre-selected the database r5 instances to save you time.
Tip: Avoid surprise bills at the end of month
You may wish to create your own Amazon Neptune database manually, using a Test and Development environment to allow you to access AWS Free tier if you are eligible and also use the smaller database instance sizing.
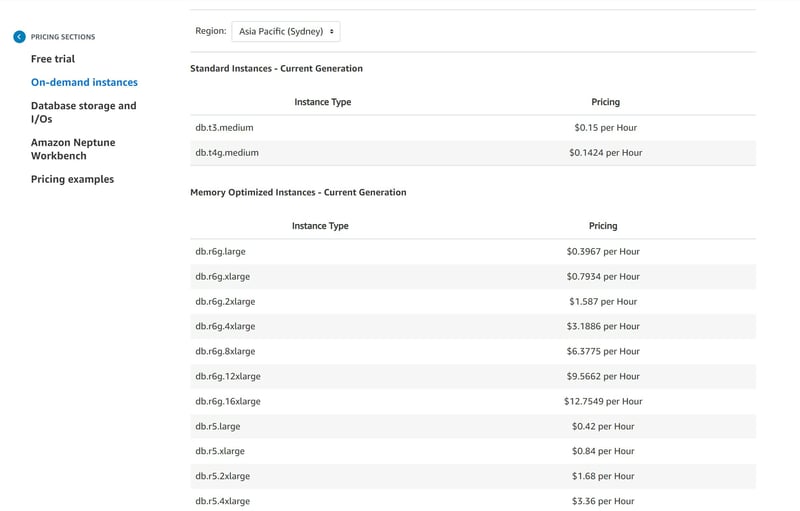
If you wish to use production environment with Amazon Cloudformation, please delete the EC2 and Neptune database instances using default db.r5 when you no longer require to use the resources to avoid expensive charges by the hour.
Here I will share my experience in a production environment, it can accumulate costs quickly by the hour due to the default instance size db r5.large setting:


Create an Amazon Neptune Cluster in testing environment - AWS Free Tier
Access the AWS Free Tier if your organization has never used Amazon Neptune before. This will allow you to select a development and testing environment to select the DB instance classes db.t3.medium or db.t4g.medium.
If you use Amazon CloudFormation template to create an Amazon Neptune DB cluster, the template will provision the resources under a production environment to only allow you access to DB instance classes starting with r5 that are pre-determined.
- Production:

- Test and Development
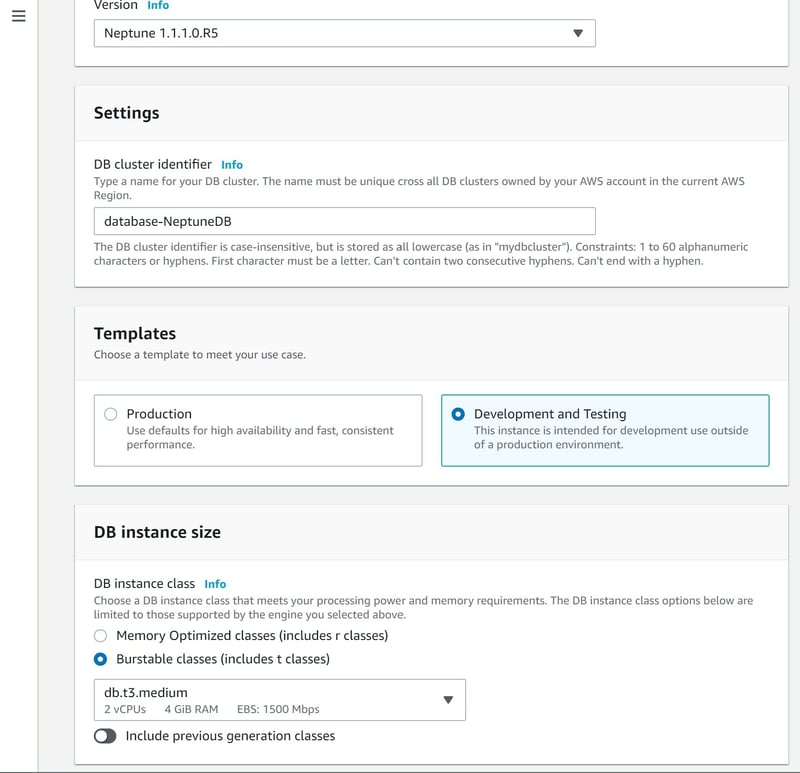
Tutorial: Create an Amazon Neptune database using the Amazon Management Console
Step 1: Navigate to the Amazon Neptune console and on the left select Databases followed by Create Database.

Step 2: Provide a name for your notebook
Step 3: You can create an IAM role. You must have certain IAM permissions attached to access the Neptune DB cluster.
Step 4: Check the box link notebook with internet access to use Amazon Sagemaker.
Alternatively you may use VPC with NAT gateway.
Step 5: You may also select other suggested and optional configurations
Step 6: Once the Neptune DB cluster has been successfully created, you may open the graph notebook.
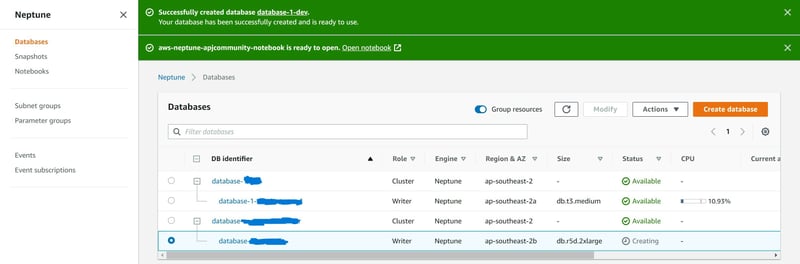
Please note, I have created a production and testing Neptune cluster for my own purpose having taken a snapshot of my first production cluster under db.r5.large
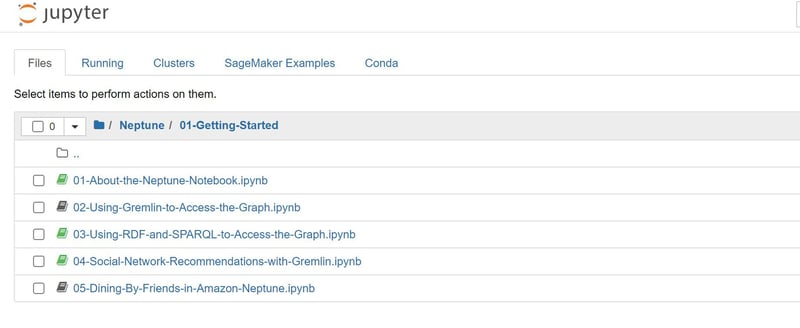
You may explore the gremlin and SPARL graph notebooks produced by Amazon as a template and modify with your own code.
Conclusion
I hope that you learnt how to create an Amazon Neptune database in a test environment allowing you to access the graph notebooks but avoid surprise month end costs because you will have access to a more controlled environment with 750 hours of usage of AWS Free Tier for the first 30 days under a smaller database instance size and after 30 days you will be charged on-demand costs.
Until the next lesson, happy learning! 😁
Next Lesson
In Part 2 of this graph database series I will explain an introduction to loading data in a production environment
Reference
🚀 Hot off the press: Introducing Amazon Neptune Global Database
From 27 July 2022, AWS Neptune Global Database can build graph relationships in multiple regions including US East (N. Virginia), US East (Ohio), US West (N. California), US West (Oregon), Europe (Ireland), Europe (London), and Asia Pacific (Tokyo) Regions.
You can read about this announcement from the AWS Database Blog written by author Navtanay Sinha here.
Register for Australia's biggest data engineering conference DataEngBytes:
- Melbourne: 27 September 2022
- Sydney: 29 September 2022
Register here: https://dataengconf.com.au/






Latest comments (0)