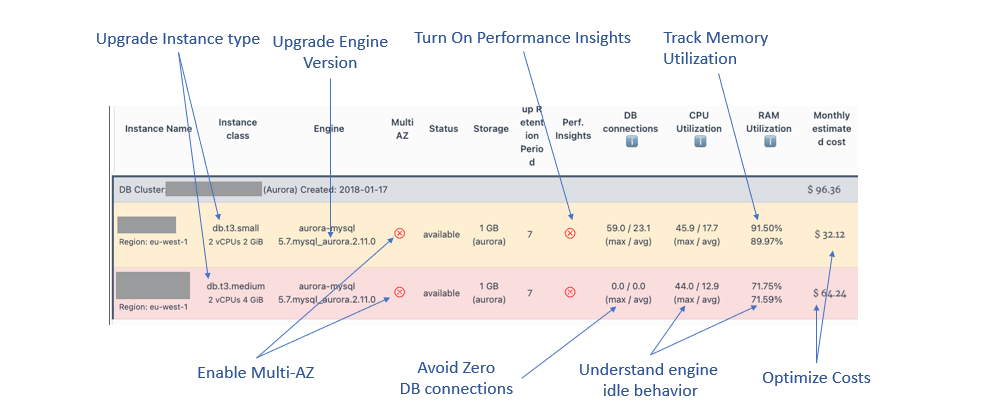
It all started with a simple post from Pawel Zubkiewicz (AWS Serverless Hero) on our AWS Community Builder slack with this image and an ask for any help in optimizing the Aurora MySql database.

The screengrab is from his https://cloudpouch.dev/ cost optimization application with some details masked and represents a real cluster running on Amazon Web Services.
How much can you really glean from a single image?
I found 8 different items to review from that image :

Let's dive in and do a deep-dive or rather a "mini" Well Architected Review of all these items.
Aurora MySQL Clusters
The image shows an Amazon Aurora MySQL Cluster with 2 database instances. An Aurora cluster can have one primary instance and a number of (optional) replica instances.
Use cases for replicas
Aurora Replicas have two main uses
Horizontal read scaling
Replicas can be used for read only workloads like reporting or Business Intelligence tools. In cases where we have large read heavy workloads, you can have multiple replicas OR replicas sized larger than the primary instance.
This way the primary can continue to handle reads/writes without being bogged down by the heavy read only workloads which are handled by the replicas. This is Aurora's horizontal read scaling model.
Improving Availability
To build a new Aurora instance takes a while (sometimes upto 30 minutes). AWS has to source an appropriate sized compute instance in the right AZ / Region / VPC , bootstrap the correct database engine version, apply all the database configurations / parameter group settings and then attach the storage (with all the data) before the database can even start accepting connections.
Since the replica's have gone through all these steps already and are active on the network, promoting a replica when the primary instance fails is very simple. Aurora can quickly promote the replica to a primary (usually takes 30 seconds) and then create a fresh replica. This is an excellent availability model with a very low RTO (Recovery Time Objective) and the RPO (Recovery Point Objective) is the last commit from the primary. As before we tend to create replicas in another AZ to the primary and this covers us for complete AZ failures too.
For production use cases, the recommendation is to always use a replica but this does mean double the compute cost as the second instance is charged while its running.
Avoiding replicas - compromises
To optimize for cost, we could compromise a little bit of availability on non-critical / Non-Production workloads by not creating Replicas. This does change the availability / RTO as there is no fast recovery if the primary fails. You have to wait the 15-30 minutes it could take to create a fresh instance.
Also the instance is always recovered in the same AZ and if the entire AZ is having issues, the instance may not get recovered without some manual intervention (bringing up the instance in another AZ)
Analysing the DB Cluster
From the screenshot, the second database (using the db.t3.medium sizing) has zero DB connections.
So I am going to assume its the replica and it is is currently idle.
So we have a db.t3.small sized primary database instance and a replica which has double the memory but has zero connections.
This is fairly unusual as we usually size replicas to match primary instances at a minimum (so if it takes over as primary it has same capacity).
Maybe the user created a larger instance but forgot to swap it as the primary. Either way - having an idle instance with double the configuration is a red flag to follow up on.
Cpu / RAM usage Analysis.
Replica CPU / RAM usage
We generally see low CPU / RAM utilization on replicas especially if they have zero DB connections. Aurora replicates data within a cluster using its own native storage level replication.
So the compute instance does next to nothing and all the heavy lifting is done by the storage layer underneath.
So one of the anamolies here is to identify why the replica is showing 44% max usage especially when there are NO db connections.
What is the engine really doing and what is driving the usage?
Maybe its doing some internal optimizations or managing the buffers / caches etc but this does look a bit high and would be another red flag to follow up on.
One reason for high usage on replicas could be where we are not using the native Aurora replication but using MySQL's binlog replication or other logical replication mechanisms where the replica has to ingest the data from primary. This is unlikely to be the case as such replication are usually between clusters and not within a cluster.
Primary instance RAM usage
The RAM utilization is peak 92% / Avg 90% which sounds high but its only a 2GB instance and these days its easy to use that up.
Generally high ram utilization on its own is not a cause for major concern as you gave it all that ram to use and its doing a good job using it!
We have to make sure the performance of workloads is not impacted by RAM shortage and we could check if the system is swapping which could indicate some bottlenecks.
Two metrics we would check in Cloudwatch to start with would be the SwapUsage and Freeable Memory and we would see if there is some sort of correlation. If Freeable memory is dropping while swap is increasing, it could indicate memory pressures on the system and switching to an instance with more memory would be beneficial.
This is an Yellow Flag we would follow up with the owner of the compute instance on.
Opportunity to adopt Graviton 2 based instances.
You may have heard of Amazon's Graviton cpu's which are built and managed by AWS themselves. They run on a different cpu architecture (ARM) but the beauty of managed services like Aurora is that there is no need to worry about this as we leave AWS to figure out how to run MySQL on these CPU's.
I always recommend using Graviton based instances as these perform just as well as other Intel based instances and are 10% cheaper than them. There could be workloads that benefit from intel based instances but for anything running on the "T" series burstable instances, a migration from "t3" to the graviton based "t4g" instance type should be straightforward. The usual caveat almost always exists on testing things out but if there are issues with t4g it is always easy to switch back to t3 instance types.
One note of Caution : Before changing instance types, we have to check if we have locked in any committed spend discounts with AWS (like RDS Reserved Instances) as changing the instance type could have a serious impact. If you move from an instance type with RI coverage to one without, we would be hit with a double whammy of losing the RI discounts and since RI's are committed, we have to still pay for them. You could end up with double the costs!
Engine Versions
There are 2 current versions of MySQL - 5.7 and 8.0 (there was no 5.8 - it just jumped to 8.x) .
MySQL 5.7, the community driven upstream project, released in 2015 and plans to end releases as of October 2023. Amazon take the code from this project to integrate into their Aurora MySQL Compatible engine and will continue to make changes and support it on their own terms.
Aurora MySQL version 5.6 was just deprecated in Feb 2023 and there is no published date for Aurora 5.7.
However it is better to start looking at migrating off 5.7 to 8.0 rather than wait till end of the year.
Also of importance are the minor versions of MySQL Engine.
Assuming minor engine auto updates is enabled, this should not be a problem. If that is disabled, we need to upgrade to later versions manually.
Performance Insights - Optimizing for Observability.
Performance Insights is a tool to obtain insights into the performance (duh!) of Aurora engine identifying the top impactful queries and helping developers fine tune them and/or the design.
Performance Insights offers a rolling seven days of performance data history at ZERO cost and there is practically zero impact / performance penalty on the database by turning this on.
So this should ideally be turned on as default for all Aurora databases.
Suggestions for Optimizations
While we would dig further into the actual red flags mentioned earlier, some early suggestions come up for optimizing this environment
- Adopt Graviton and size up the primary
The first recommendation I would have is to add a t4g.medium replica.
We would then promote this new t4g.medium replica to primary and make sure all connections are working with this instance.
If this was a production workload, using our recommendation discussed above, we would add another t4gt.medium replica in a different AZ.
We would keep the existing primary around as a replica just in case we need to fall back for any reason but once workloads are confirmed to be working fine then delete the t3.small and t3.medium instances
As a result of these migrations we should see
- 10% Lower baseline cost per instance
- Increasing RAM should drop any swapping / provide some headroom
- If we are keeping a replica, fast failover
Applying Well Architected Principles
As an architect, I always try and use the Well Architected Framework for anything I am reviewing.
Here is how I believe we have covered the individual pillars in this review.
Operational Excellence
- We would be looking into CloudWatch metrics for some the redflags we noticed
- We would be reviewing upgrades to the database engine to ensure we stay upto date on engine upgrades
- We looked at turning on Performance Insights for improving queries / performance
Security
- we did not cover any security related changes but a deeper dive could include reviews of database encryption (at rest), connection encryption (enforce TLS on incoming connections), review of the security groups, credentials use etc
- The move to Graviton Instances does brings some hidden security features (example memory encryption) and latest Nitro enhancements - these are all behind the scenes but good to have
Reliability
- Use of Aurora already brings added durability / RPO as any commit of data includes 6 copies across 3 AZ's and the system was designed to withstand a failure of an entire AZ plus another node (see Amazon Aurora paper on this)
- We reviewed the RTO advantage and single AZ failure resilience of having replicas
Performance Efficiency
- We covered CPU / RAM usage and looked at options for Graviton to boost performance
Cost Optimization
- Graviton move drops 10% baseline - deleting larger replicas can save 75%!
Sustainability
- We tried to balance removing idle usage (the compute instance sitting there idle) and also graviton cpu's have lower carbon impact (apparently)
Conclusion
That was a lot to cover from a single image and is almost what I call an "Architecture on a Post-it Note".
If you got to the bottom of this article - thank you!
Please let me know if I have missed anything or if you have any other feedback.





Oldest comments (0)