Taylor Riggar is the one who did this session! I was glad to be part of the session.
More information about data strategy, graph databases, graph use cases, introduction to Neptune, and amazon Neptune serverless may be found in this blog.
We found that due to the recent transition from monolithic programs to more micro-service apps, current applications require a purpose-built datastore for delivering the data for various types of micro-services, their access pattern, and optimizing them. The micro-services' ownership and management of the given dataset also comes down to this. Architecture frequently refers to CQRS (Command, Query Responsibility, Segregation) as one of the terms. The screenshot shows the ECOMM website, which has several features and functionalities. For instance, a search engine or a product catalog with a shopping cart, customer reviews, or driving recommendation. Each feature has a unique access pattern and characteristic, which cause them to be stored in a specific types of database for a specific purpose. If you see recommendation is using graph database, common graph algorithm or graph pattern.

https://bookstoredemo.com is a git-hub repo. Which helps to explain the different purposeful database used in the context. I have also attached the screenshot which help to answer the question what types of access pattern I am really solving.
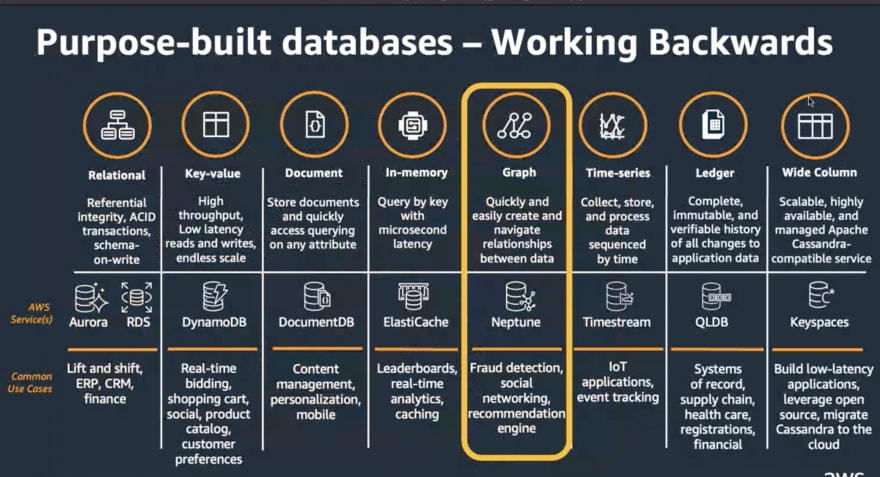
Let's take a closer look at the graph database, which will help in the analysis of highly connected datasets. This are dataset where number of relation tends to out number the dataset. The query are complex join of patterns or ability to recursive iterate over the table(CTE). Graph database helps to store the data in optimal way and query language which are easier to expressed when it comes from the perspective of building query for this pattern.
Use case of graph database
Knowledge graph: Attempt to make sense of how data from disparate sources will be combined. A notable example of this is Wikipedia, which must refer to the wiki data underlying.
Identity graph: By utilizing social media, discover audience interest, preferences, and purchases.
Fraud graph: Identify and stop fraudulent transaction trends.
Security graph: You can use a security graph to find threats in your environment, including un-authorized user access to an application or exposed resources.
Amazon Neptune:
Fast, reliable, full managed graph database service that makes it easy to build and run applications that work with highly connected database. It is mainly used when there is a highly connected dataset. There are two kinds of primary model for the graph database.
Label property graph: This one is familiar to the majority of developers. The concept is to represent data or entities as nodes and their connections as edges.
Resource description framework: Semantic web movement of late 1990 or early 2000s, which is really trying to drive context to things entity or model that are linked. Wikipedia is good canonical model for this!
With Neptune query would run with no second latency. Query are extremely faster and it scale out too. It easy process to use the graph database. AWS has launched openCypher the query language to support and make it easier for the user. It allows to add query in ASCII expression.





Oldest comments (0)