
When you work on real-world data it is often to have lots of missing values. There is much cause of missing data may be People do not respond to specific questions in the survey, Data entry errors, The individual drops out before sampling or many more reasons. The handling of data is very important during the preprocessing of the dataset because most machine learning algorithms do not support missing values.
In this article, I try to cover many ways to handle missing values in the dataset.
- Variable Deletion
- Replacing missing values with Mean/Median/Mode
- Impute missing values for continuous variable
- Impute missing values for categorical variable
- Assigning An Unique Category
- Predicting The Missing Values
- Using Algorithms that Support missing values
1. Variable Deletion
This method commonly used to handle the null values. In this variable Deletion method, we delete a whole column with missing values and it depends on case to case. We use this method only when there are lots of missing values in a particular column than variables. Let's see it with an example
For this example, we are going to use the famous Kaggle dataset house price prediction
data=pd.read_csv('house_price.csv')
total = data.isnull().sum().sort_values(ascending=False)
percent =total/len(data)*100
pd.concat([total,percent], axis=1, keys=['Total','Percent']).head(5)

Here you can clearly see that 4 columns have Null values higher than 80% so it is good to drop those columns from our data.
data=data[data.columns[data.isnull().mean() < 0.80]]
You can also drop specific rows with a higher number of missing values. This may increase the accuracy of your model rather than filling these columns. This is beneficial only when you have a large amount of data.
data.isnull().sum(axis=1).sort_values(ascending=False).head()

Complete removal of data with missing values results in a robust and highly accurate model if it does not have a high weightage. But if the column has a high correlation with the output we recommend not to delete it because it may lead to less accuracy and Loss of a lot of information.
2. Replacing missing values with Mean/Median/Mode
Impute missing values for continuous variable
This is another common technique use to handle missing data. In this method we replace missing values of numerical data like age, a salary of a person with the mean/median of the column, that's why it can prevent the loss of data compared to the previous method.

# The missing values are replaced by the mean value
data['MSSubClass']=data['MSSubClass'].fillna(data['MSSubClass'].mean())
Impute missing values for categorical variable
The above code is only for numerical values for catagirical values we replacing the missing values with the maximum occurred value in a feature.
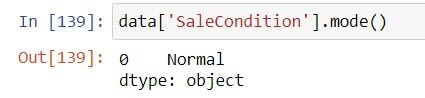
# The missing values are replaced by the median value.
data['SaleCondition']=data['SaleCondition'].fillna(data['SaleCondition'].mode()[0])
Assigning An Unique Category
If the number of missing values is very large then it can be replaced with a new category. Let's understand it with an example
For this example, we are going to use the Titanic dataset from Kaggle.
# Read data from CSV
data=pd.read_csv('titanic.csv')
data['Cabin']

# Replace null values with New category 'U'
data['Cabin']=data['Cabin'].fillna('U')
data['Cabin']
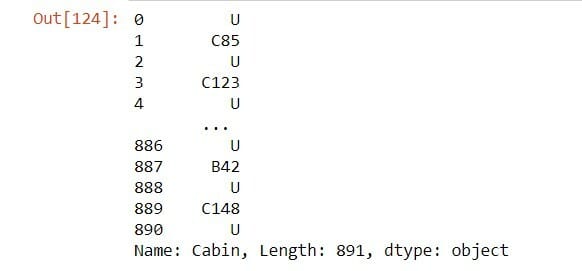
This method is an approximation that may lead to variance in our data but it is better than dropping a whole column/row that's why it Prevent data loss and work better with a small dataset. this method works better on linear data but may cause data leakage.
3. Predicting The Missing Values
In this method, we use the features which have not null values and train a model to predict missing values. This method may give us better accuracy than replacing it with the mean/mode/median if the null values are less. let see it with an example.
In this example, we are going to Kaggle the Stroke dataset and train a RandomForestRegressor model using other available features to predict the missing values in 'bmi' feature.
# Load dataset
data=pd.read_csv('healthcare-dataset-stroke-data.csv')
# Find Column with null values
data.isnull().sum().sort_values(ascending=False).head(3)

# Predict null values and replace null values with predicted values in data
data1=data[data['bmi'].notnull()]
data2=data[data['bmi'].isnull()]
temp1_Y=data1['bmi']
temp1_X=data1.drop(['bmi'] , axis=1)
temp2_X=data2.drop(['bmi'] , axis=1)
from sklearn.ensemble import RandomForestRegressor
mod=RandomForestRegressor()
mod.fit(temp1_X,temp1_Y)
pred=mod.predict(temp2_X)
k=0
for i in range(len(data['bmi'])):
if(data['bmi'][i]==0.0):
data['bmi'][i]=pred[k]
k=k+1
It gives a better result than earlier methods.
4. Using Algorithms that Support missing values
All the machine learning algorithms don’t support missing values but some may. The k-nearest neighbors (KNN) algorithm is a simple, supervised machine learning algorithm that can be used to solve both classification and regression problems. It works on the principle of a distance measure that's why it can ignore a column when a value is missing. Naive Bayes can also support missing values when making a prediction. But in python, The sklearn implementations of naive Bayes and k-Nearest Neighbors do not support missing values. In these both algorithms you no need to handle missing values in each column as ML algorithms will handle them efficiently
Conclusion
In this article, I discuss many ways to deal with missing values and I try my best to explain these methods but there is no perfect method to handle missing data, all the methods give the best performance on different conditions depend on data. now let it stop here I hope you find this article useful and able to learn new things from it.
Thank you for reading👏





Top comments (0)