Maybe you’ve heard about OpenAI’s CLIP model that was released last year, on January 5, 2021. Maybe you even tried to read an article on the OpenAI’s website or the paper where the development of the CLIP model is described. Maybe you remember that the model is somehow related to deep learning, text-to-image generation and other cutting-edge technologies from the machine learning world. And maybe after all of this you want to understand CLIP on a deeper level. So let’s unpack the CLIP model.
What is CLIP?
Put simply, CLIP or Contrastive Language-Image Pre-training is a multimodal model that combines knowledge of image description and concepts written in English with semantic knowledge of images.
The CLIP model is trained on 400 000 000 image and text pairs. Those pairs were a picture and its description written in English, so the CLIP model was trained using the data of 400 000 000 matched up pictures and their descriptions — it seems like a lot, but it is clear that it’s still not all the images that exist on the Internet and therefore pictures and descriptions of not all things existing in the world. Nevertheless, this training gave the CLIP model the ability to describe any picture possible. So if you input an image into the CLIP model, it will return the most suitable description, caption or summary of that image.
It is called “zero-shot learning”. Usually most of the machine learning models learn one specific task. For example, they are trained to classify houses and cars. So it is expected that those models will do well on the task that is given to them: classifying houses and cars. Generally no one expects a machine learning model trained on houses and cars to be good at detecting, for example, planes or trees. However, the CLIP model tends to perform well on tasks it isn’t directly trained to do.
CLIP can easily distinguish between images of simple objects like a house or a car but also between something more complex like a bumblebee that loves capitalism or a lightbulb that is trying its best, although CLIP has never seen such things in its training data: it just has a generalized knowledge of what those English words and phrases mean and what those pixels represent.
Summarizing all of the things said, the CLIP model is a vision and text model that was trained on hundreds of millions of images and their descriptions, can return the likeliest caption to a given image, has “zero-shot” capabilities using which ut can accurately predict entire classes it wasn’t trained on.
How does CLIP work?
To connect images and text to one another, you need them to be embedded. Imagine you have one house and two cars. You could represent them as a dot on a graph:
Source: WolframAlpha
And, basically, that is the process of embedding. We just embedded the information on the XY grid. You can think of embedding as a way to transport information into mathematical space, just like we did: we took information about a house and two cars and transported it into mathematical space. The same thing can be done with text and images.
The CLIP model consists of two sub-models or two encoders: image encoder and text encoder
During the training, the images and their text descriptions in a mini-batch are transformed to vectors of the same length by their corresponding encoders, respectively. After normalization, the image vectors are pulled closer to their matching text vectors, and pushed apart from the other text vectors. The same happens with the text vectors and their corresponding image vectors.
- Contrastive pre-training
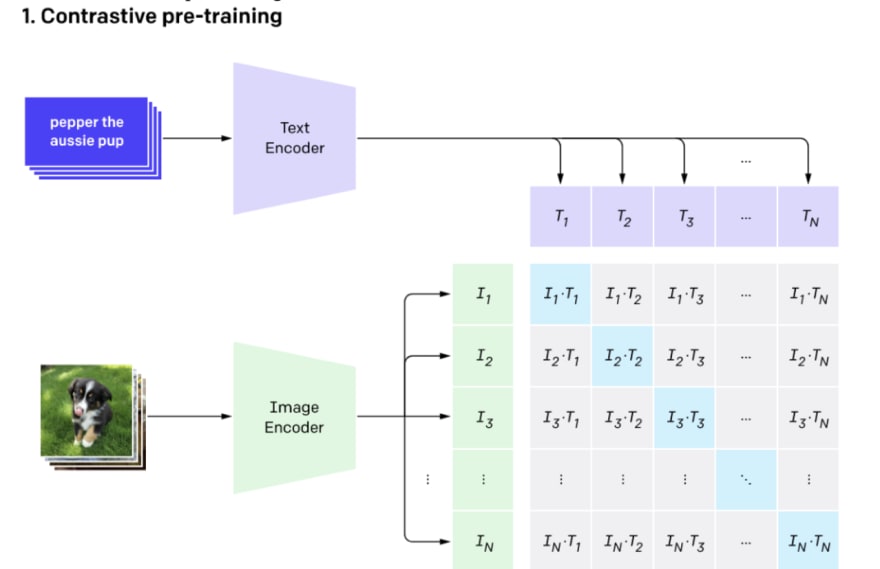
Source: OpenAI
Input images and texts are encoded, and their vector representations are used to build a similarity matrix (I*T is an inner product). During training CLIP learns that the values on the diagonal represent correct classifications, so their similarity must be higher than those in the same row and column. This approach contrasts what the CLIP model knows goes together (diagonal values) to what doesn’t go together (non-diagonal values). Each row is a classification task: given an input image (I1), the CLIP model predicts the text. Similarly, each column is a classification task: given an input text (T1), the CLIP model predicts the image. During training of CLIP, OpenAI used a very large size of mini-batches 32768 (N on the figure above).
During inference one takes a set of labels, creates texts based on those labels and runs these texts through the text encoder. Text embeddings are later matched to visual representation.
- Create dataset classifier from label text &
- Use for zero-shot prediction
 Source: OpenAI
Source: OpenAI
Classic classification training cares only about the predefined labels. If it is successful in finding houses and cars, then it doesn’t care if it is a photo or a sketch of a house or a car or a specific number of storeys in a house or a brand of a car. Whereas CLIP learns various aspects of images and points attention to details due to its training coupled with a large dataset.
The CLIP model is sensitive to words used for image descriptions. Texts “a photo of a bird”, “a photo of a bird sitting near bird feeder”, or “an image of a bird” all produce different probability paired with the same image:
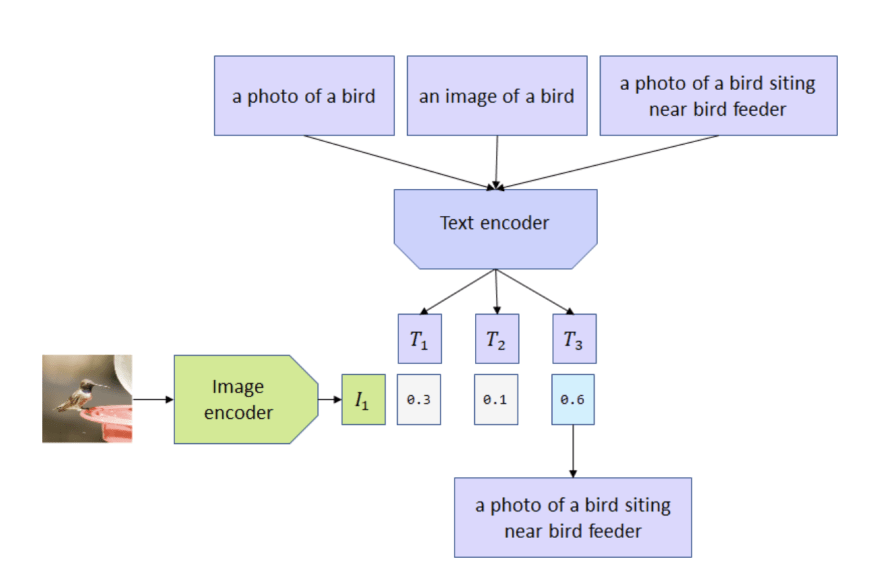
Source: OpenAI
Why does CLIP matter?
The CLIP model has a lot of advantages and applications due to its progressive usage of computer vision and language processing. For example, CLIP is used in DALL·E 2, an AI system that can create realistic images and art from a text prompt in a second. If you want to learn more about this AI system and the CLIP’s part in it, read my article about DALL·E 2.





Latest comments (0)