
Software Engineering🔽
- It is a systematic, disciplined, cost-effective technique for software development.
- It is an Engineering approach to develop software.
🟢Software Engineering Process
1) Software Development Lifecycle
2) Requirements & Specification (SRS)
3) Architecture
4) Software Design Process
5) Implementation
6) Development
7) Testing
Software Development Lifecycle🔽
It is a process used by the software engineering industry to design develop and test high-quality software SDLC tends to produce high-quality software that meets customer expectations.
🟢SDLC Models
There are processes, methodologies and frameworks range from specific prescriptive steps that can be used by the organization there are many SDLC models that have been developed to achieve the different required objective the model specifies various stages of the process and the order in which they are carried out.
- Waterfall Model
- V Model
- Incremental Model
- Iterative Model
- Spiral Model
- RAD Model
- Prototype Model
- Agile Model
🟢Waterfall Model
It is a breakdown of project activities into linear sequential phases where each face depends on the deliverables of the previous one.
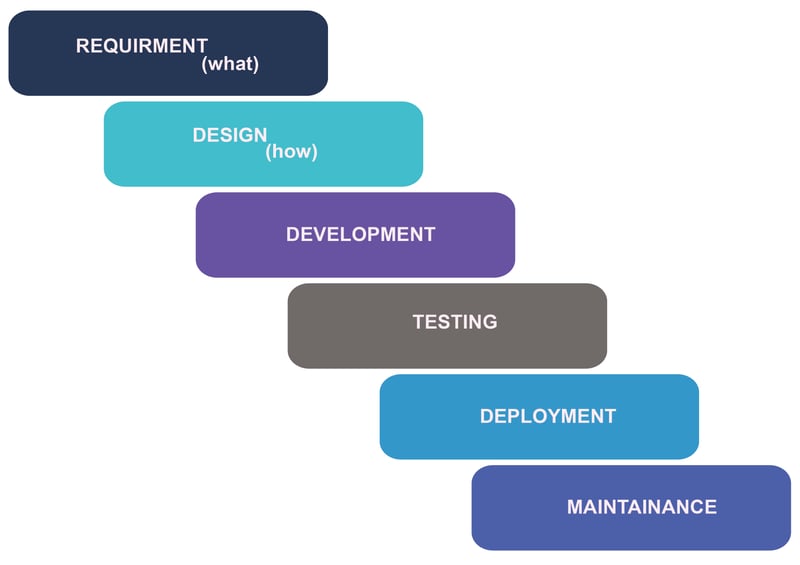
🟢Incremental Model
The incremental build model is a method of software development where the model is designed, implemented, and tested incrementally (a little more is added each time) until the product is finished the product defined finished when it satisfies all requirements
Each iteration passes through the requirement, design, coding, and testing phase and each subsequent release of the system adds function to the previous release until all designed functionality has been implemented.
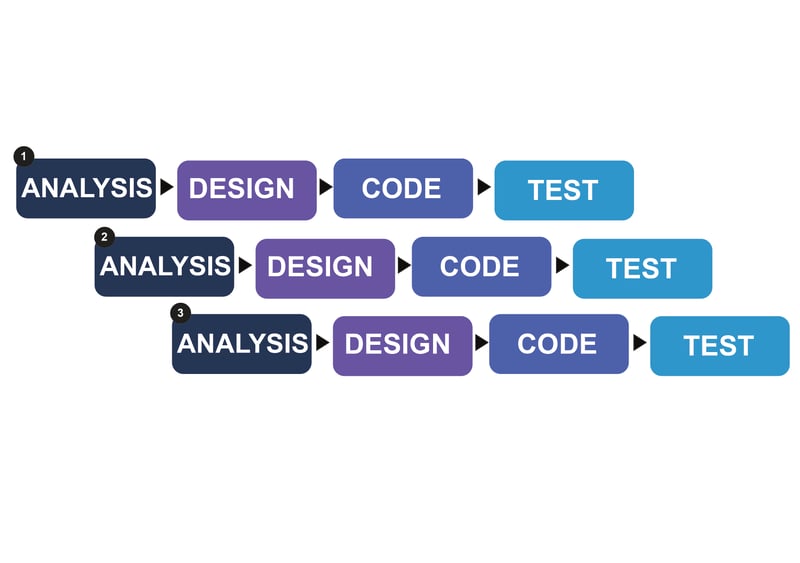
🟢Iterative Model
The iterative model is a particular implementation of a software development life cycle (SDLC) that focuses on an initial, simplified implementation, which then progressively gains more complexity and a broader feature set until the final system is complete. When discussing the iterative method, the concept of incremental development will also often be used liberally and interchangeably, which describes the incremental alterations made during the design and implementation of each new iteration.
Unlike the more traditional waterfall model, which focuses on a stringent step-by-step process of development stages, the iterative model is best thought of as a cyclical process. After an initial planning phase, a small handful of stages are repeated over and over, with each completion of the cycle incrementally improving and iterating on the software. Enhancements can quickly be recognized and implemented throughout each iteration, allowing the next iteration to be at least marginally better than the last.
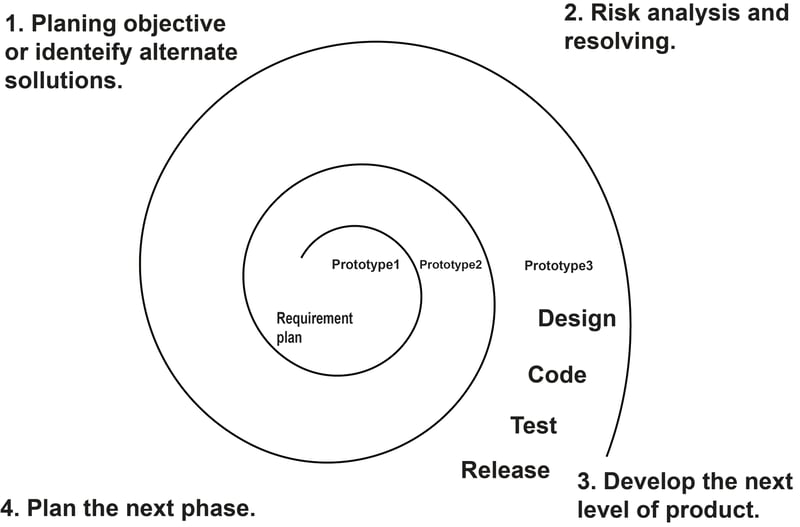
🟢Spiral Model
The spiral model combines the idea of iterative development with the systematic, controlled aspects of the waterfall model. This Spiral model is a combination of the iterative development process model and sequential linear development model i.e. the waterfall model with a very high emphasis on risk analysis. It allows incremental releases of the product or incremental refinement through each iteration around the spiral.
🟢Agile Model
The meaning of Agile is swift or versatile." Agile process model" refers to a software development approach based on iterative development. Agile methods break tasks into smaller iterations or parts that do not directly involve long-term planning. The project scope and requirements are laid down at the beginning of the development process. Plans regarding the number of iterations, the duration, and the scope of each iteration are clearly defined in advance.
Each iteration is considered as a short time "frame" in the Agile process model, which typically lasts from one to four weeks. The division of the entire project into smaller parts helps to minimize the project risk and to reduce the overall project delivery time requirements. Each iteration involves a team working through a full software development life cycle including planning, requirements analysis, design, coding, and testing before a working product is demonstrated to the client.
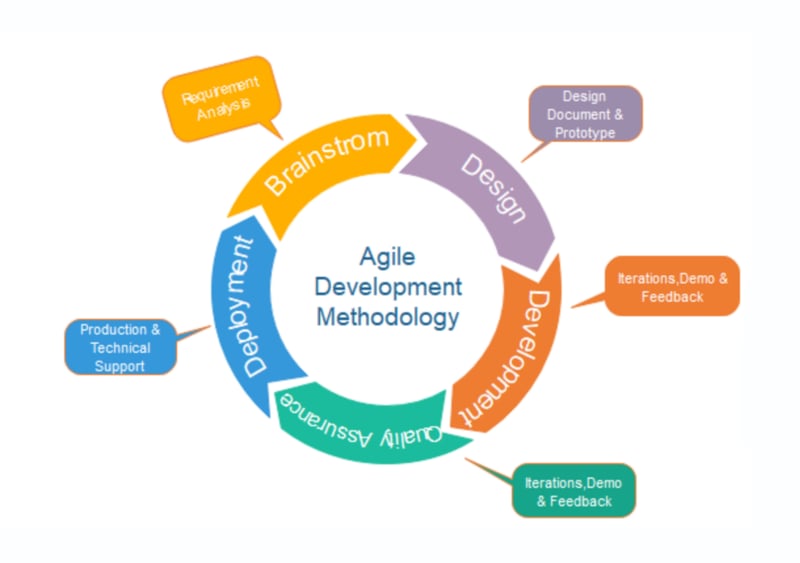
Agile is a methodology. It's a way of thinking. It is NOT a model in and of itself.
Agile was invented because the scope of software development was changing. Waterfall methods aren't bad, they're just slow, and not built for a lot of modern problems.
This is largely due to the complexity of modern systems which make them hard to plan 100%. This means at some point, a change will be required, and production will stop until all the documents are updated.
With agile however, we can move a little bit quicker. We are constantly looking for and adjusting to change.
📌Agile Manifesto
The agile manifesto is a set of guiding principles for agile development. They are:
🔺Individuals and interactions over process and tools.
🔺Working software over comprehensive documentation.
🔺Customer collaboration over contract negotiation.
🔺Responding to change over following a plan.
With this set of rules, all agile models are created. Note, in here we aren't throwing out processes and tools, and we aren't going without a plan. We are simply just creating priorities within the development process. We want to make the piece of software that is needed. To do this, we need to keep communication channels open and collaborate with all involved.
Through this manifesto, models were created that fit these rules.
📌Agile Models
🔺Scrum - Scrum is focused on sprints. Sprints are these 1-4 week production cycles. We take the software, come up with a goal of where we want it to be, and then build it to there.
Once we finish a sprint, we then go back to the stakeholders, show them the software, take suggestions, and move on to the next sprint.
All of this allows us to stay flexible. We are communicating with the stakeholders almost every 2 weeks with this model. This means we are constantly able to take those suggestions and change the direction of development.
For more deeper understanding

🔺Kanban - The kanban system is one of optimization. With kanban, we are trying to analyze the flow of production and figure out the slowdowns.
To do this, we usually use some sort of visual flowchart. We break the project up into tasks and fill up the chart. We are then able to see if any part of production has a slowdown. Maybe for example, our review process is slowing us down, or maybe it's planning.
With kanban, we are trying to make small adjustments into the right direction. We want to work with the existing process, not replace it.
🔺Lean Startup - Lean startup is a way of testing out the market before spending on development. Here we create a MVP (Minimum Viable Product) to see if there is interest in the product we are developing.
Production costs a lot of money. It would be really bad if we spent $500,000 on a project, just to figure out that nobody is actually interested in that product.
An example of this would be to build a website that sells a certain product. Get it working to the point where people can place that item into a cart. Then when they go to purchase, have it give them a friendly message stating that this feature will be coming soon. We then track how many people are actually interested in buying products off our website.
If we have a lot of interest, then we are good to go ahead with production. If we don't have as much interest, then maybe we need to rethink our design.
🟢Waterfall Model Example
1) Requirements
- collecting email & message
- store in db
- prevent bad input
2) Design
- using HTML & CSS for building
- JS for input verification
- MySQL for backend
3)Development
- actual coding
- documenting
4) Testing
- does form collect input
- does it send info. to db
- does it prevent bad input
5) Deployment
- deploying on AWS
6) Maintainence
- fixing bugs
- adding features
Requirements & Specification🔽
🟢Requirements
A way of figuring out the exact specification of what the software should do all things that define the goal of the system.
A non-tech definition of something the user requires from the system.
Anyone can understand.
ex - ability to submit a request for medical treatment form.
🟢Specification
A more technical way of figuring out exactly what the software should do we can say it is the technical aspect of requirements.
A technical definition of what users require from the system.
Keep it simple we are not trying to design.
ex - send AES 256 form data from the frontend to the server.
🟢Example
Requirement
- The tire must work on SUV automobiles.
Specification
- Must support 75,00lbs pressure.
- Tire must fill US DOT standards.
- T or greater speed quality.
🟢Types of Requirements
On the basis of functionality there are two types of requirements
1.Functional
What are the functions of the program
what should the system do
2.Non-Functional
what goals should be met
How should the system work
Other than these two there are three more types of requirements
1.Product
must have of the product itself
ex - the app must be coded in kotlin
2.Organizational
company policies, standards, style, etc
ex - data should be encrypted by AES 256
ex - project should be developed by SCRUM
3.External
external law, regulations, trends, etc
ex - it must use SSL due to law Xyz in the US
Design: Architecture🔽
🟢Architecture Introduction
Architecture is the highest level of design within a system. It is the link between idea and reality. It takes our idea for the system, and creates a plan for it. We focus on only the largest areas of the system here. We want to break it down from idea, into concrete areas to build.
In software, bad architecture is something that CAN'T be fixed with good programming. It is a critical step within the development process. Once we decide on an architecture, we have to understand that it can't be changed.
🟢Architecture Overview
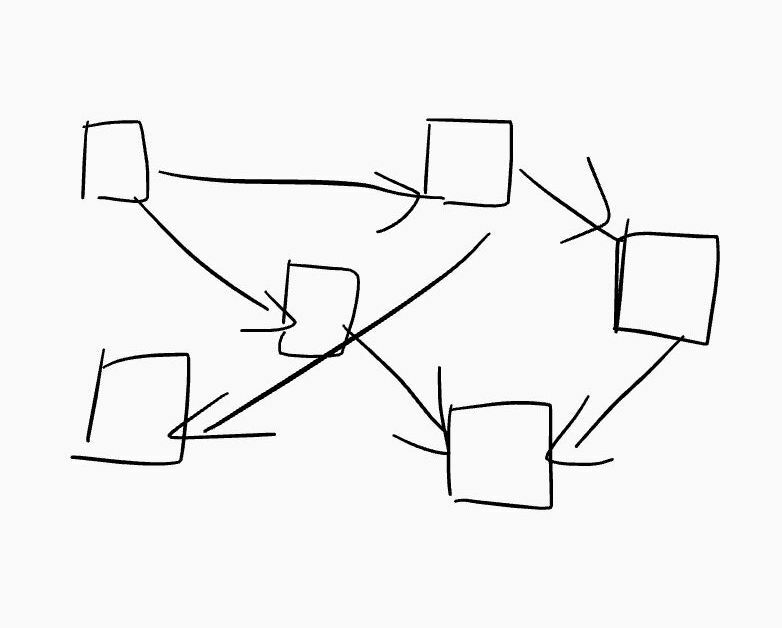
📌Bad Architecture
📌Good Architecture
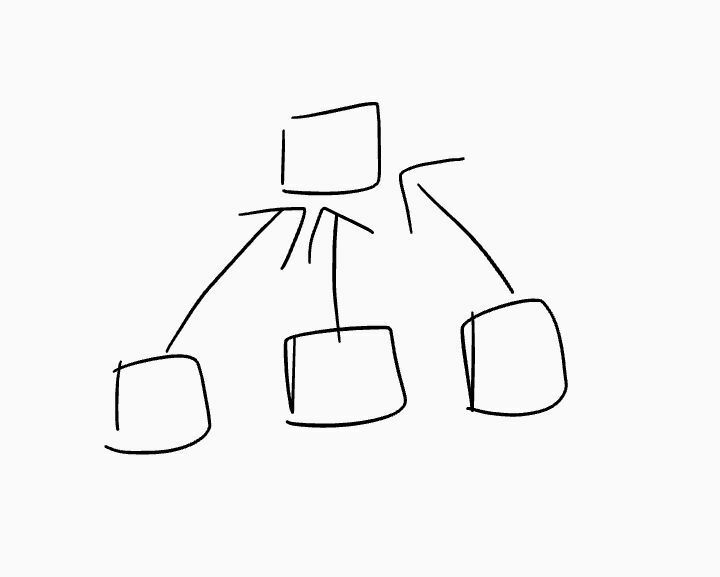
Software architecture is all about breaking up larger systems and ideas, into smaller focused systems. Our first step is to take the requirements, and build an initial architecture. We take this broad set of ideas and guidelines, and have to organize it into functioning areas.
Each of these areas are then put through the same process to break them up into smaller and smaller pieces. Eventually we will have a blueprint for the entire system designed.
Good architecture is hard. It takes a lot of resources to develop correctly. However, this upfront cost is almost always recovered from how maintainable the software is. This will reduce the amount of bugs, and the time to fix those bugs.
Good architecture also helps for faster development and better resource utilization. If we break up the project into small pieces, we will understand how to have multiple developers work at the same time on it.
🟢Software Architecture example
1.We are going to design an architecture of a game.
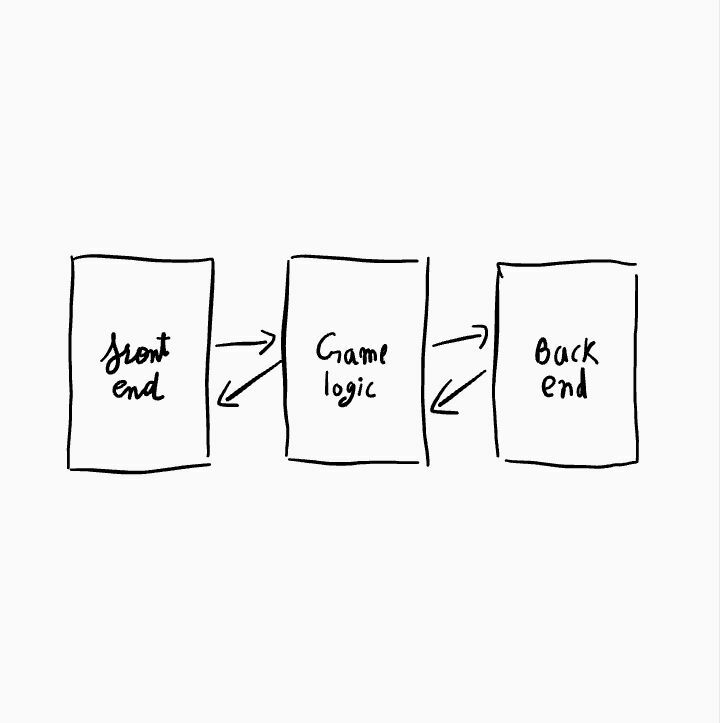
2.now we should divide these layers based on functionality.
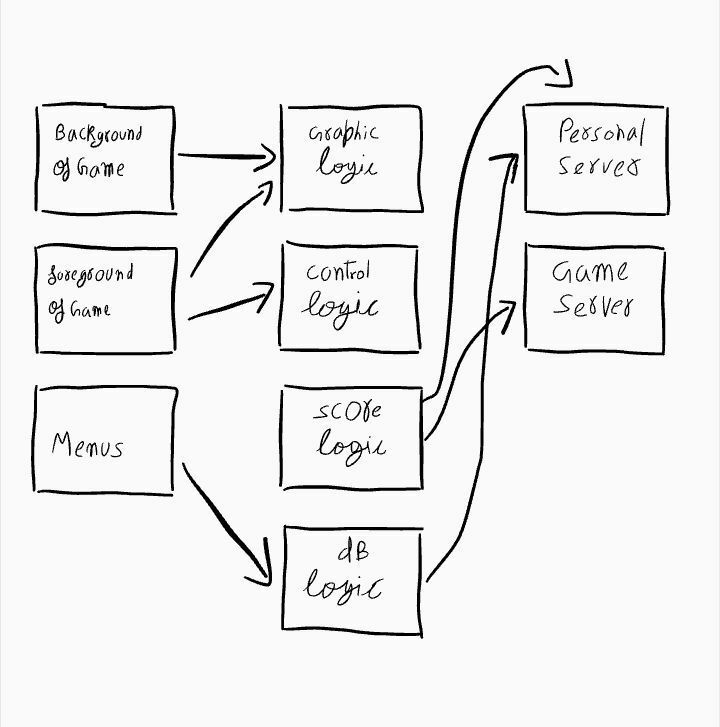
3.now we will add another layer that controls the interaction between frontend and game logic.
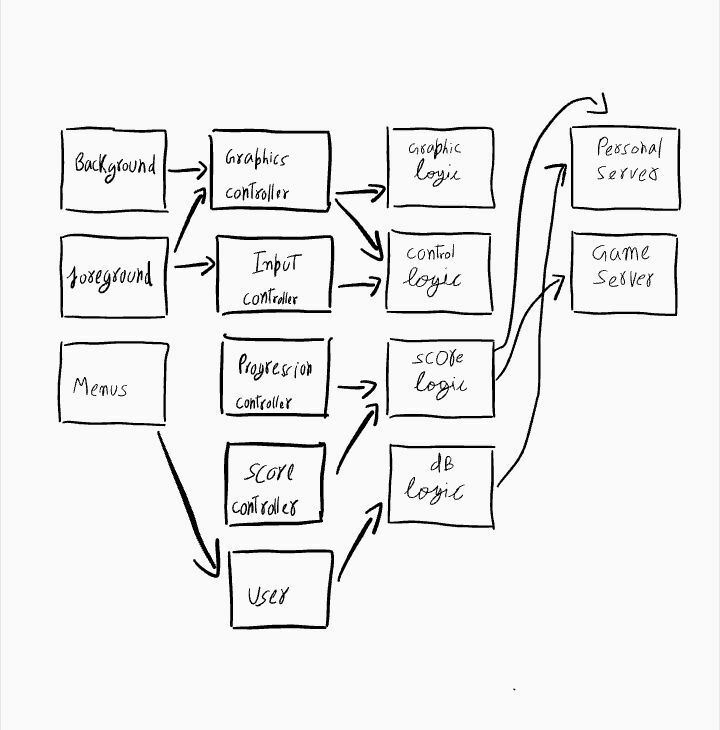
🟢Architecture Patterns
📌Pipe-and-Filter
The pipe and filter pattern is a good pattern to use to process data through multiple different layers. The key to this pattern is the ability of each step to input, and output the same type of data. So if you send a set of numbers in one side, you will get a set of numbers out the other side.
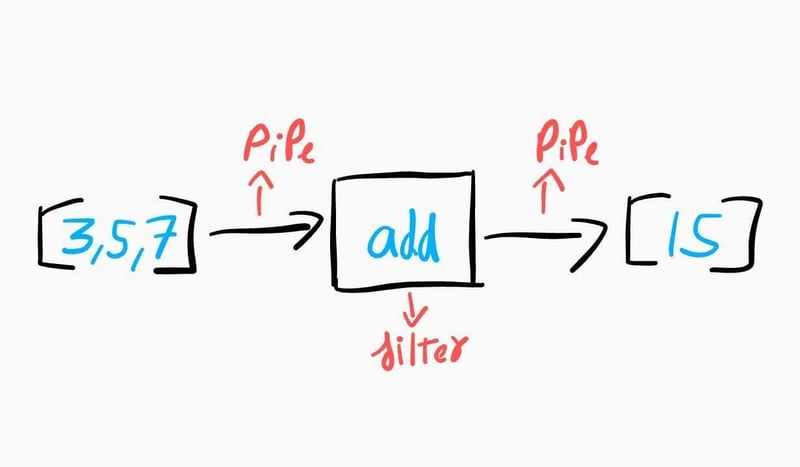
🟢 Architecture Patterns
📌 Pipe-and-Filter
The pipe and filter pattern is a good pattern to use to process data through multiple different layers. The key to this pattern is the ability of each step to input and output the same type of data. So if you send a set of numbers in one side, you will get a set of numbers out the other side.
This key constraint makes it so you can mix and match the logic in any order and still have the program work. These different filters can also be set up across multiple servers.
There is definitely an added complexity with this pattern. Setting it up can be tricky to get correct. Also, if the data is lost at any step, the entire process is broken.
📌 Client-Server
The client-server pattern is one that is quite common today. Every single website and most phone apps use this architecture. With this pattern, there are two parts to the software, the client, and the server.
Software Engineering
Let's take an iPhone app, for example. What you download in the app store is what is known as the "client software". This is the version of the app built to talk to the server. It doesn't store any of the server's data locally. It is just set up to make the appropriate server calls when necessary.
The other part of this is, of course, the "server software". This is the software that is installed onto a server to receive the requests from the client. The server holds and updates the data. It also processes requests and sends the data to the clients. Servers have to be tuned correctly, as there can be a near unlimited number of clients requesting information.
This is a great pattern for accessing and updating a single repository of information. It's great for keeping track of accounts and regulating which data is given automatically.
📌 Master-Slave
The master-slave pattern consists of two elements, the master, and the slave. The master is in full control of all slaves associated with it. This is good for a multitude of different applications.
Software Engineering
One such application is with duplicate backup servers. You don't want these backup servers all acting independently of one another. This will create a bunch of different states of memory. Each server will have a different set of data. Instead, you have a master server, which is the main server of operation.
The master server is the one dealing with all of the normal day-to-day operations. Then at some point during the day, it sends a signal out to all of the slave servers to tell them to begin their backup operation. The slave servers all start up, copy the data from the master server, and then go back to sleep.
This pattern is also used with "multi-threading". Here we break up an operation into a bunch of small parts. Each of those parts is given a thread and fed through the CPU. If a CPU has multiple cores, it can process multiple threads at the same time.
We typically have a master thread that controls the creation and tracking of all slave threads. The slaves do exactly what the master thread has told them. The master thread keeps reassessing the situation both creating and deleting slave threads. Once the operation is finished, the master thread ceases as well.
📌 Layered Pattern
The layered pattern consists of divvying up the program into layers of technology. These layers only communicate with adjacent layers. Let's say we have an architecture with 9 layers. In this model, 8 would only be able to communicate with 9 and 7, 4 with 3 and 5, etc.
Software Engineering
This simplifies the communication channels and helps to better distinguish the areas of the program. Overall, this helps to make the program more maintainable. The downside to this is that there can be added complexity in some areas. For example, if you need to send a message from layer 1 to layer 9, there will have to be a function in each layer to pass that message along.
🟢 Architecture Conclusion
There is no one-size-fits-all plan when it comes to software development. The process must be taken on a case-to-case basis. Us, as engineers, seek to find the best pattern or set of patterns that solve the problem.
This process is an iterative one. We come up with an idea, get feedback, rework it, and repeat the process many times. After a series of iterations, we have the architecture that will work best for the problem.
Design: Modularity🔽
The design is where we really plan out our system. We can go as detailed as possible in this step.
The main focus here is to break up the project into subsystems and modules.
- Subsystem: Independent system that holds independent value.
- Module: Component of a subsystem that cannot function as a standalone.
We should slowly refine and reorganize the systems and sub-modules until they make the most sense.
Software Engineering
Design is two things:
- Activity: Working to design the software.
- Product: A document or set of documents detailing the design of the software.
Information Hiding - Hiding the complexity of the program inside of a "black box".
Data Encapsulation - Hiding the implementation details from the user, providing only an interface.
Both of these work to hide the implementation details and protect the integrity of the data. We want to control the flow of data and provide the user with an easy-to-use experience.
With these ideas, we can take the most complex of code and make it accessible to anyone. Doing this at each step in the design process also helps make the code easier to maintain.
With it implemented properly, we don't need to know the entire codebase to make a change. We only need to know the part of the program we are working on. The encapsulation of all the other levels of the program makes things easy to test and change.
🟢 Goals of Modularity
1) Abstraction
2) Composability
3) Decomposability
4) Protectibility
5) Continuity
6) Module understandability
🟢 Coupling Introduction
Coupling is one of the major things to look at when designing the modularity of the system. It details how dependent each module is on every other module. A set of modules with tight coupling is bad design. It creates hard-to-maintain code.
We don't want our modules to be dependent on one another. We want to be able to swap one module out with another and only have to update code in the swapped module. The more dependent our program is, the more and more modules we will have to rewrite for every change.
📌 Tight Coupling
This is the worst form of coupling. Tight coupling means there is a strong dependence between modules. Changes will be very hard to make, and bugs will be difficult to track down.
- Content Coupling: When one module modifies or relies on the internal working of another module.
- Common Coupling: When several modules have access to the same global data.
- External Coupling: When several modules have direct access to the same external Input/Output.
📌 Medium Coupling
Here the coupling is getting better, but we still have room for improvement.
- Control Coupling: This is when data is passed that influences the internal logic of another module.
- Data Structure Coupling: This is when multiple modules share the same data-structure.
📌 Loose Coupling
- Data Coupling: This is when two modules share the same data. This is a good form of coupling.
- Message Coupling: This coupling is when messages or commands are passed between modules.
- No Coupling: No communication between modules whatsoever.
🟢 Cohesion Introduction
Cohesion is the other area to focus on when we are talking about modularity. Cohesion is the measurement of how focused our module is on a single task. The more focused the module, the higher the cohesion.
With cohesion, higher is better. We want modules that only do one thing and one thing only. The reason for this is with maintainability.
What we want to find is the point where we can maximize the effects of both. We want to create loose coupling and high cohesion.
📌 Weak Cohesion
- Coincidental Cohesion: The tasks within the module are only linked because they are in the same module. This is the weakest form of cohesion. Here, the modules are completely random. There is nothing linking the tasks within a module, except the fact that they were simply put into the same file.
- Temporal Cohesion: The tasks within the module are only linked because events happen around the same time.
- Logical Cohesion: The tasks within the module are linked due to being in the same general category.
📌 Medium Cohesion
- Procedural Cohesion: The order of execution passes from one command to the next. Here we have a relationship of time. This is different from temporal because the tasks are both linked and essential for one another. There is an order by which these must be executed to work properly.
- Communicational Cohesion: When all tasks support the same input and output data.
- Sequential Cohesion: A combination of the previous two. When all tasks work in which the output data for one is the input data for the next. With this, we have a procedure of tasks, and these tasks all share the same data.
📌 Strong Cohesion
- Functional Cohesion: This is when all tasks within a module support activities needed for one and only one problem-related task. In essence, the module only does a single action.
- Object Cohesion: This can either be lumped in with functional cohesion or by itself. Object cohesion is when all activities modify a single object.
This only works in object-oriented languages. An example might be a module that only modifies a user object. All tasks within this module update the user module in some way.
🟢 Cohesion Conclusion
Cohesion is really important to make code that is easy to understand and maintain. The more focused the modules, the easier the code will be to debug.
Remember, however, that this must be a balance with coupling. A group of extremely cohesive modules might also be tightly coupled together. We are looking for the balance between the two. If you remember one thing from these sections, it's that we want "loose coupling and strong cohesion".
Implementation & Deployment🔽
Good design allows us to see our entire project before it is built. With this, we can decide which areas we want to build and which areas we want to purchase. The great thing about purchasing code is that it is almost always cheaper.
It's almost always a win-win situation to purchase instead of build. Coding, however, is usually very specific. This makes it rare to find software that perfectly fits the problem. However, do some research before you begin building; you can save a lot of money.
🟢 Take Care of Programmers
Implementation is where most time is spent and where a lot of time can be lost.
Always program while alert and focused.
35 hours of programming can be just as productive as 70.
Programming takes focus; constant interruptions will reduce overall focus.
🟢 Coding Principles
- Use a style guide so all the code looks relatively the same.
- Code is written for people, not for computers.
- Make modules easy to understand.
- Go into everything with a plan.
🟢 Deployment Introduction
Deployment is a mix between testing and implementation; it mostly happens after testing but it requires implementations too.
The level of planning in this space is directly related to how the deployment affects the overall project.
Deployment should be built with the idea of retreat. If something goes wrong, how can we revert?
🟢 Deployment Planning
- Amount of planning is dependent on the size of change.
- We look at which areas which most likely have the biggest problems.
- Areas to look at:
- Database
- Software Integration
- Runtime changes
- Training
- Downtimes
- Backups
- Network
- Memory
- Finally, we need to look at planning steps to turn back.
🟢 Deployment Rollback
Rollback is the act of reverting a system back to the previous working state.
- Look for a point of no return.
- This is a point where it takes longer to go back than it does to just continue through.
- Knowing this will help make a decision during deployment.
- Every step of the deployment process makes a decision whether rollback is a better option.
Testing Overview🔽
Testing is the process of finding errors. These errors can either be failures within the code, or they can be failures to meet requirements. If the app doesn't do what it was set out to do, then that is a problem. In testing, we work to make sure the program works for all requirements.
- Test Data: Inputs that are designed to test the system.
- Test Cases: Ways in which we operate the system with the given data.
- Oracle: The set of "good" outcomes.
🟢 Bugs
Bugs are, in essence, a deviation from expected behavior. For example, if you have a website, a potential bug might be that the website doesn't load. The code fatally breaks during loading and results in a lack of the service. This is, of course, a deviation from the expected behavior of being able to access the website.
Another bug could be if the website logged you into someone else's account by mistake. The website in this scenario is still up and functioning. However, a deviation from expected behavior, only being able to access your own account, has happened.
- Failure: The event by which the code deviates from expected behavior.
- Error: The part of the code that leads to the failure.
- Fault: What the outcome actually was.
Testing can be used to show the presence of bugs but never to ensure the absence of them. This is because the only way to ensure this would be to test EVERY single possible test case. This could easily be in the billions to trillions for a typical system. This would be nearly impossible to do. The cost of testing alone could far exceed that of the entire rest of development times 10.
So what we do instead is try to do the smallest set of test cases to cover the greatest amount of ground. We use a mixture of different testing practices to accomplish this task. There will always be bugs, but we can actively remove most of them if we are smart.
🟢 Verification and Validation
- Verification: Are we building the thing right? Does the software work compared to the given specifications.
- Validation: Are we building the right thing? Does the software work compared to what the user/client needs?
A way of violating verification would be if the program accesses the wrong database. In this situation, we are not building the system correctly. It is deviating from expected behavior.
A way of violating validation would be if the program calculates car payments, instead of house payments. Our car payment calculator could be the most stable calculator in the world. However, we were supposed to build a house payment calculator. We are not building the right system. We are building a system that solves problems that it was not designed to solve. (And conversely doesn't solve problems that it was designed to solve.)
A more real-world example of this would be if a company has a really specific way of collecting information, and we designed a system that collects that information differently. All of the same information has been collected, but not in the right way. We aren't building the correct system.
Knowing and testing both of these are important to delivering high-quality software!
🟢 Testing
📌 Unit Testing
Unit testing to focus on the smallest unit of software. We are trying to isolate different areas, repeating until we test every module of the program. In this, we take a module, and we give it test cases. We then check these test cases against the oracle.
Overall, we are trying to make sure that the modules are doing what they were designed to do. We don't want to have bugs from other modules ruin the module we are testing. So for unit tests, we typically supply dummy values to isolate the module. This way, we know if a bug is happening, it's happening from the area we are testing.
📌 Integration Testing
Integration testing is the next step. Once we are satisfied that the modules are all working how we want them, we need to begin testing them together. With integration testing, we begin testing the architecture and the communication as a whole.
Where in unit testing we came up with test cases for individual modules, with integration testing, we will come up with test cases for groups of modules. For example, we might want to test an entire form, instead of just testing each box within the form.
📌 Incremental Testing
One of the issues with integration testing is that if a bug arises, it can be difficult to tell exactly what module introduced that bug. Incremental testing is one way of making this process easier.
With incremental testing, we slowly add one module after the next into the testing environment. This way, if a bug arises, we know which module caused the bugs to be introduced.
📌 Top-Down Testing
With Top-Down Testing, we begin testing at the highest possible level and then work our way down. To have this work, we need to have a set of dummy modules that we slowly replace with regular modules.
- Stub: A template of the model that will be implemented. Typically returns hard-coded values.
A stub is typically used for this. It's a module that doesn't have any logic in it. All it has are functions that return hard-coded values. Hard-coded here means nothing that was calculated, just values that we put in there. So for example, a stub might have a function "getUser(int 45)". Instead of going through and finding information about a user, it just returns a user object that we have hard-coded into it.
This way, we can test our module's ability to use the user information without having to introduce another module. Once we test everything and make sure it works, we can then add in the actual module and do our next round of testing.
📌 Bottom-Up Testing
Bottom-Up Testing is the opposite of Top-Down. Here we work from the bottom and use things called drivers to make our way upwards.
- Driver: Templates which execute commands and initialize the needed variables.
When we work from bottom up, we need the logic which calls our bottom modules. For example, if our module is the module with getUser() in it, then we need to figure out a way to properly test this. What we right is a driver, which initializes the variables and then makes multiple calls to the functions we need it to.
So in this situation, the driver might call getUser() 1,000,000 times with random values. We would then look at the results to see if the function is working the way we want it. Once we are satisfied, we add another layer and keep going.
📌 Back to Back Testing
Back to Back testing is good to do when you already have a working program. With this, we run a set of tests on the system before we make a change. We then make a change, by either updating, adding, or deleting a module. We then run the same set of tests.
We now have two sets of data. The before and the after. We compare these two sets to make sure that there are no differences. If there is a difference, we know the change did more than we like. We can then revert or go fix the bug.
📌 Manual vs Automatic Testing
There are two different ways we can set up tests. We can do it manually, where we enter values ourselves, or automatically, where we set up another system to do the test.
- Automatic
Both of these have their own merits. Automatic testing is nice because we can cover a much larger area than manual testing. We can set up a system and have it test millions of test cases. Once we set it up, we can run it every time we change our code, guaranteeing we didn't break anything with a new update.
This all, however, comes with a lot more overhead. The testing system is a system itself. This means more planning and development time. On top of this, we will have to design tests which can be done from the computer and provide oracles to check their data. If we are testing out millions of test cases, the oracle will most likely have to be a complex algorithm.
There also comes the issue of testing the tester. What if our tester is designed incorrectly and it gives us false positives or negatives? We then spend unnecessary time chasing down phantom bugs or deploy bad software.
- Manual
Manual testing involves a human being testing the code. They user goes in expecting to do an action. They then test to see if there is expected behavior. Bugs are noted down, and then given to developers.
These testers can be developers, stakeholders, or specially trained testers. They can more easily come up with oracles and perform a wide range of tests.
However, humans are very slow when compared to a computer. They can only test so much of a system. Often times, this means many parts of the system don't get properly tested.
Overall
The best way to test is to combine these two. Have a good set of automatic tests and a good set of testers. This will allow the speed of automatic, and the ease and flexibility of manual.
📌 Black Box vs White Box Testing
Depending on who tests can also have a large difference on testing. In the testing world, there is this idea of "white box" and "black box" testing.
With black box testing, we are testing the device based on what it is supposed to do. This is what most users will do when they get the software. They will try to perform all the actions they want. Test all of the expected behavior and make sure the program is working for them. If a bug arises, it will typically be because of a failure to meet the requirements of the program.
With white box testing, we are testing the system on the inside. This is where our automatic testing comes in. We test all different angles and aspects of the program to make sure it works. Here we are looking to test different combinations of different situations. For example, with a program that calculates house payments, we will want to test multiple interest rates, home prices, etc.
This is the technical side of things. This allows us to test all different sides of the system.
Software Maintenance🔽
Software Maintenance is the process of modifying the software after it has been delivered. In essence, it's the time after the honeymoon. This is the longest and most expensive part of the life of the software.
The majority of maintenance is usually spent fixing bugs.
🟢 Types of Maintenance
There are three types of maintenance:
📌 Corrective Maintenance
Corrective maintenance is where we go in and fix bugs. We fix the code, so it does what it was supposed to do in the first place. This type of maintenance is a reaction to the unexpected issues that arise during use. It typically consumes a large portion of maintenance budgets.
📌 Adaptive Maintenance
Adaptive maintenance is where we change the software to handle a change in the environment. This is when something in the environment changes, and we need to change our software to accommodate that.
For example, let's say we are building an application that uses the Facebook API. Facebook changes their API. Now our software is no longer functioning correctly because Facebook changed. Adaptive maintenance is the process of going into our software and making sure it works again.
📌 Perfective Maintenance
Perfective maintenance is where we go in and add functionality to the system. We don't fix anything, and we don't change the system to handle a new environment. Instead, we go in and make the system better.
For example, we have a program that calculates house payments. We might add functionality that lets us calculate car payments as well. This is now additional functionality that we have added. This is now what we will be doing the majority of the time. A well-crafted program should be able to be easily maintained and expanded in the future.
🟢 Version Control Systems
Version control is the means by which we track changes in our codebase over time. It's a record of all the changes we have made and is stored in a way to allow us to see exactly how we got to where we are today.
📌 Why Do We Use It?
Version control is important because it allows us to do a few things:
- Revert to Old Versions: If we ever make a mistake, we can revert back to an old version of the code.
- Branching: We can split off from the main version of the code to add a feature or try something new.
- Collaboration: Multiple people can be working on the same code at the same time.
- History: Every change is recorded, along with who made the change and why.
📌 Basic Concepts
- Repository: This is the record of all of the different versions of the code.
- Commit: This is when a user decides that they want to record the changes that have been made to the code. This is like a save point in a game.
- Branch: A separate path of the code that isn't the main version.
- Merge: When you take the changes that you have made in a separate branch and add them to the main branch.
- Pull Request: This is when you have made a branch, made changes, and then asked for those changes to be merged into the main version of the code.
🟢 Conclusion
We've covered a lot of ground in this guide, from the fundamentals of software engineering to various architecture patterns, design principles, and the importance of modularity, coupling, cohesion, implementation, deployment, testing, and software maintenance. Additionally, we explored version control systems as a crucial tool for managing code changes and collaboration.
Remember, software engineering is an ever-evolving field, and staying curious, open to learning, and adaptable will serve you well in navigating the dynamic landscape of technology. Whether you are a seasoned developer or just starting on your software engineering journey, continue to explore, experiment, and build as you contribute to the exciting world of software development.





Oldest comments (0)