Reading through some articles on the subject it seems easy to assume that the deep web and dark web are the same thing, but looking deeper into their nature that doesn't quite seem to be the truth. I think the confusion comes from the level of accessibility that they seem to share. One is unindexed, the other is unindexed whats the difference? Well let me tell you har har.
To start I think I should do a little bit of overview to clarify how I see this distinction and then I'll take a deep dive and try and explain a popular dark web. As I've seen it defined the internet falls into roughly two categories with each having some slight overlap and each containing subcategories. Feel free to correct me bellow if I'm wrong, but let me explain.
--The internet has two levels, that which is indexed and that which is not.--
SURFACE WEB
or websites with specific indices, hosted by a server or sets of servers, that allow most users to access them by through their internet service provider(ISP). These 'surface web' website's indices are stored in a cache in one of a few places. A cache on ones computer (ie their web browser), an ISP's own cache, or a myriad of Root Name Servers(RNS) and other lower tier servers distributed throughout the world. Together all of these stores of specific Internet Protocol(IP) addresses collectively make up a network of what's typically called the Domain Name System(DNS).Visit Yutaro's blog post to learn more but this is a basic overview of my knowledge on the subject.
Now one important thing is that most of these Uniform Resource Locator(URL) or Uniform Resource Identifier(URI) that are connected to their IP addresses through the DNS are basically public access. As long as someone has a browser and internet they can type the URI or URL into the browsers search bar and Voila they are at the website they want to view. In most cases these same URLs that link to an IP address can be found by typing some key words or phrases into a search engine and sifting through a few hundred pages making them even more accessible. Now the really interesting thing is that these public access surface level websites make up either roughly 5% or .03% (depending on who you ask) of "the internet" or web of connections linked to information that exists today. Now you may be wondering, "What about the deep web and the dark web?" Well good question.
THE DEEP WEB
is weird and kind of murky and hard to define in my honest opinion. Its mainly unindexed and when its not and still considered 'deep web' it requires specific validation to access and it definitely doesn't show up through conventional searches or search engines. Deep web websites don't have classical indices in the DNS and as such is much harder to locate. Although there are some instances otherwise Instead of typing into your browser some fancy URI or URL to query a cache of IP address these websites need to be routed to directly through their IP address in order to gain access to them. In other cases they have indices stored in a cache somewhere, but additional resources are needed to view the pages. For this later category think of pay-to-view or pay-to-access content or Application Programming Interfaces(APIs) databases or medical, and banking information that have restricted access through some level of encryption or token system. This information still exists on the internet and has a URL that can be accessed in the right conditions through ones browser, but it isn't necessarily public access or very accessible. This deep web information makes up the other approximately 95% of the web.
"But Anders! thats like 100% of the interwebnt what about the 'Sour horse-purple of tha infawkcalypse' er whatever" Well I say to you stop reading ghost stories
Naw im just playing I'm here to talk about Onionland and all the darkness that media loves to call the deep web! But is actually not that and is really--
THE DARK WEB
So I said there is indexed and unindexed content on the internet and that's what I meant, DNS severs and other caches of URI/URL connected IP addresses exist that direct users to where they want to go, but that makes distinctions between password protected and other restricted content and not password protected and restricted content and unindexed/non-cached-URI/URLS hard to draw out. This murky distinction seems to give the wide disparity in estimations of the size of each category relative to each other and the the internet as a whole some credence (arguments against the actual size of the internet aside(I mean how much information is really on the internet anyway)), but that distinction aside the truly darknet(add sound of wind whispering by) is neither of those things.
THE DARK WEB
exists in a weird web of its own that's generally hidden under layers of encryption and accessed through networks of routers outside of ones accessed by surface web browsers. What does this mean you may be wondering. Well it means that unlike surface web websites these websites are hard to access and are accessed via networks outside of conventional routing networks. Most of these networks also require a browser apart from the common and well known browsers like Firefox or Chrome. Some people may know of one that's popular in the realm of the dark web, Tor browser
which when downloaded and opened up would look something like this.
Wow so similar! It's got a search bar and it has access to a search engine. It can access most of the surface websites people love to browse as well! So what's the big deal!? Much like a supey-sube, mufflers and spoilers are fancy and all but it's whats under the hood that really matters.
Let me take a second to sidebar right now. So maybe you know a thing a two about the dark web and all of its facets and you might be thinking "But Anders! What about other facets of the dark web like Freenet or I2P and all of their technologies?" Well maybe in another blog post (even though those two in particular have similarities to Tor, ie onioney layers and such). In this last section I want to focus on one subset of the dark web, Tor.
Tor
So Tor, what makes it different. Well the first and most obvious difference is that unlike conventional web browsers, that can access URLs with different domain names like ".com" or ".org" and unconventional domain names like ".ly" or ".le", Tor can also connect to the domain name ".onion" which requires the technology Tor uses to provide some anonymity. These technologies are described through some fancy terms that I must admit I don't fully understand, but will try to cover as best I can and will hopefully inform you enough to work as a building off point to look into them yourself if you so desire.
To start Tor uses layers, hence the onion moniker, of encryption to hide the content of what is being sent from a user as well as a distributed and overlaid network of routers that randomly reroute information that is split apart to and sent through different paths to the same end. Im not going to talk about overlay networks here. I don't understand them well. I'm going to stick with onioniness and the onion network that makes Tor what it is.
This onion network as it is commonly termed starts with the user or originator who sets up a connection with an 'entry node' that establishes a secure connection with the user. This entry node works as an intermediary that then connects to another node creating basically a link between the user and the second node through itself (like one person holding two other peoples hands). Through this link the user then sends an encrypted message through the first node to the second node that only the second node can partially decrypt to the point that the next node (determined by the user) is viewable. In this interaction only the entry node knows of who the user is but knows nothing of the message that is sent and has no knowledge of where the message is going other then the next node in the network. At the same time the second node knows nothing of where the message originated or its content, but knows where the next node in the network is. The second node now acts as the intermediary and connects to a third node that the originator through the first and second node can interact with. The originator then sends an encrypted message to the third node which only it can decrypt continuing the chain until the final location that the originator wanted to connect to is connected to. At this point the last node, the 'exit node' has been connected to the originator through a chain of nodes that have no knowledge of where the chain started or where it will end and no knowledge of who is connected to this web outside of the two nodes its connected to. In essence each link in the chain is like a person with a blindfold passing an envelope of envelopes with different routing information to the person next to them until the second to last envelope is opened and passed to the last address. Now the encrypted message that only the last person knows how to read can be read and knows hows to decrypt. In this way every node along the network only knows of the node proceeding it and the node that it reroutes to and nothing else except for the originator that knows of all the nodes along the way.
How does the information get back to the originator though? Well the process is now reversed. The end node re-encrypts, rewraps the message in all its layers, and the message is sent back to the originator. The message is passed back through the same nodes used to reach the location the originator wanted to connect to and following the same rules as before. The difference is on this journey instead of wrapping the message in encryptions the originator decrypts the last layer of encryption and sees the response from the site it connected to. If this seems confusing I think these diagrams may help clarify things:
The first outlines the basic structure of the layers of encryptions and who can see what: 
and this second one outlines slightly better the specific nodes that are tor specific and the final routing process from originator to desired location:
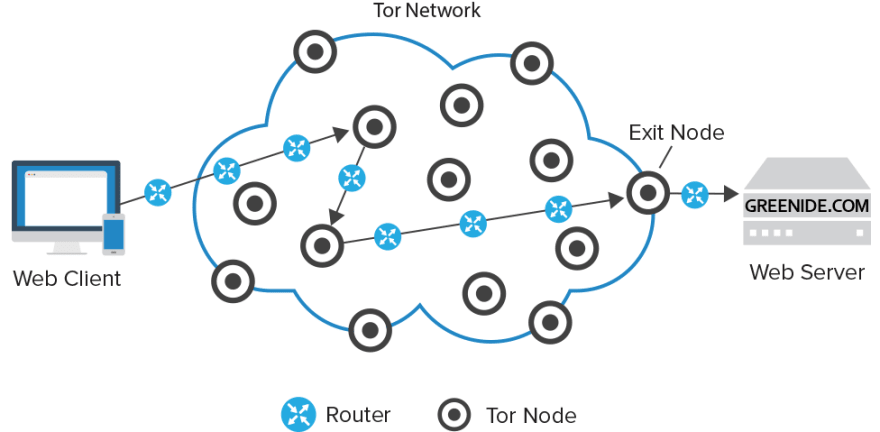 .
.
Now this may be a reductionist explanation, but as opposed to the surface web Tor and most Dark web browsers are networks of anonymized connections that link through heavily encrypted means and route to each other anonymously. In this way the classical routing methods that allow search engines and surface web browsers to operate and track information are hampered by a lack of accessibility to such information. In the same way the dark web is unforgiving and difficult to access keeping it hidden and relatively misunderstood.
Anyway there's always more to say on the subject so feel free to comment below and clarify where I went astray or identify where I can learn more. Maybe in a later blog post I'll cover some of the other dark web browsers and rehash what I didn't explain well or know about Tor. Thanks for reading!





Top comments (0)