The situation with Covid-19 limits the possibility of face-to-face communication. Remote work is now a reality, and the demand for video conferencing such as Jitsi Meet continues breaking records.
Could it be possible that Jitsi’s software development activity and community are on high-demand too?
 Jitsi@jitsinews
Jitsi@jitsinews 👋 We are seeing high volumes of traffic from our friends all over the world (specially in Italy) and we just wanted to let everyone know that we tripled our deployment size in the busiest regions! 📈
👋 We are seeing high volumes of traffic from our friends all over the world (specially in Italy) and we just wanted to let everyone know that we tripled our deployment size in the busiest regions! 📈
Happy Meetings! ❤️13:15 PM - 06 Mar 2020


This post summarizes one of the analysis that my colleagues David Duran, Gerardo Aguirre and I did for our M.S. in Data Science. Following the GQM approach, we defined a clear goal and some related questions. Then, we decided the best metrics to answer those questions.
Goal
Analyze the impact that a global pandemic such as Covid-19 has on Jitsi
Questions
Did Covid-19 countermeasures change:
- Jitsi’s activity patterns?
- Jitsi’s diversity patterns?
- Jitsi’s community risk?
As we are trying to measure impact, we need to see potential changes. For instance, did software development activity change during covid-19 outbreak compared to last year?
We selected Feb 1st- May 31st 2019 and 2020 as our timeframe to measure such impact.
Metrics
| Contributor Activity | Contributor Diversity | Community Risk |
|---|---|---|
| Total Contributors | Organization Diversity | Bus Factor |
| Total Commits | Gender diversity | |
| Timezone Diversity |
Total Contributors: number of authors that made a commit over a period of time
Total Commits: number of commits over a period of time

- Organization Diversity: different email domains over a period of time. Here we can find company’s domains (e.g jitsi, 8x8, etc) or individual’s (gmail, users, etc)

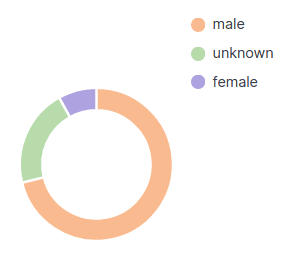
- Gender Diversity: total share of female and male author names that made a commit
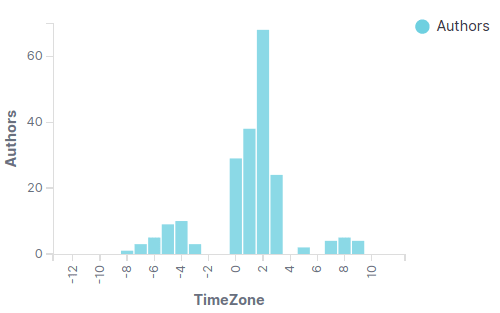
- Timezone diversity: existing authors on each timezone
- Bus Factor: minimum number of contributors needed to make the 50% of git code on Jitsi over a period of time
Tools used

Data gathering and storage
For data gathering we used an open source tool called Perceval. Perceval offers a Python module for retrieving data from repositories related to software development. It works with many data sources, from Git repositories and GitHub projects to mailing lists, Gerrit or StackOverflow.
For this specific analysis, we will just need Jitsi Git data.
If you are running Jitsi-data.py available in this Gitlab repo, make sure you have installed perceval first
$ pip install perceval
You can simply use perceval git module on python with perceval.backends.core.git:
import json
from elasticsearch import Elasticsearch
import logging
from datetime import datetime # to specify a specific timeframe
import gender_guesser.detector as gender
from perceval.backends.core.git import Git
from dateutil.parser import parse
Perceval has 2 arguments for Git:
- URI: the repository or list of repos from GitLab or GitHub you want to analyze
- Gitpath: usually something like /tmp/repo-name.git
# It has 2 arguments, uri and gitpath: repo = Git(uri=repository, gitpath='/tmp/'+repository.git)
data_repo = Git(uri='https://github.com/jitsi/jitsi-meet', gitpath='/tmp/jitsi-meet.git')
Moreover, we use Python Elasticsearch client to store data and mapping from python script to our ElasticSearch instance.
# Instance of elasticsearch to put the data into ElasticSearch/Kibana system (it is necessary to have both up on localhost)
elastic = Elasticsearch()
# Read mapping json file to ElasticSearch
mapping_file = open("mapping.json", "r")
mapping = json.load(mapping_file)
# Creation of ElasticSearch index using the mapping
index_name = "repo_jitsi_index_def"
response = elastic.indices.create(
index=index_name,
body=mapping,
ignore=400 # ignore 400 already exists code
)
Data transformation and mapping
Perceval gives us raw git data with a lot of information over a period of time (we specify this thanks to datetime python package): Commit, Author, Lines added, Lines removed, Email, Commit Date and more.
However, in order to analyze contributor diversity, we need to create new fields with the data provided. That's why we add organization (based on email domains), gender (using a gender detector python package) and timezone fields (cleaning item field)
You can see how we iterate through the different fields provided by Perceval to get the data in our GitLab repo
Once we generate these new fields, we create our Elasticsearch mapping, transforming item data into a new structure matching the mapping for ElasticSearch
Data visualization
If you are running unity-data.py script with your Elasticsearch and Kibana instance opened, you can go to your Kibana localhost (usually 5601) > management > index patterns and click on create index pattern. You should see the index name given at jitsi-data.py (by default is repo_jitsi_index_def)
We then elaborate a Kibana dashboard with the specific visualizations that fits best with our defined metrics. We called it “impact_dashoard”
At a first glance, we can see an uncommon behavior on Jitsi’s activity since February 2020:

And when comparing 2019 period with 2020, results are also quite interesting:

Image below highlights major changes regarding contributor’s diversity and activity:
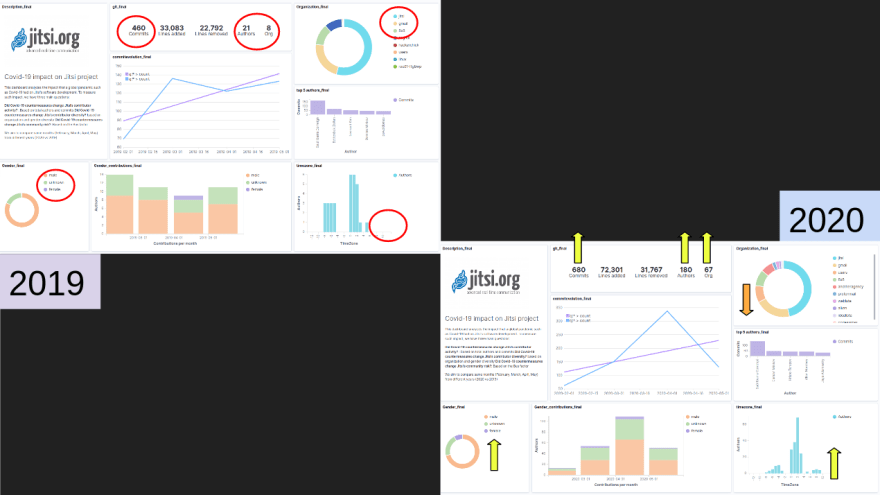
We can see that:
Contributor’s Activity increased: there is an increase in commit activity, lines added and removed, authors and organizations involved on Jitsi’s software development
Contributor's Diversity increased: It’s interesting to see that women activity was under 1% last year and since covid-19 started, it increased to 8%. Still a low number, but is a good indicator.
Also, we see some author activity in Asia that didn’t existed before.
Disclaimer: there are “unknown” data that our gender detector couldn’t guess. The main reason is because some Jitsi’s developers have non-occidental characters and our gender detector is optimized for occidental names. We did an exhaustive cleaning for the most relevant names though, reducing our “unknown” data, but we couldn’t erase it completely.
What about Community Risk?
To answer our last question and metric, we work on a query using Jupyter Notebook.
The Bus Factor for developers isn’t something new: It is the minimum number of team members that have to suddenly disappear from a project before the project stalls due to lack of knowledgeable or competent personnel. In other words:

Our Bus Factor approach for our specific goal answers the question Which is the minimum number of contributors needed to make the 50% of git code on Jitsi?
As a result, we get that in 2019, Jitsi only needed 2 developers to make the 50% of git code while in 2020 Jitsi needs at least 9 developers. This fact is indeed good for Jitsi’s project health!
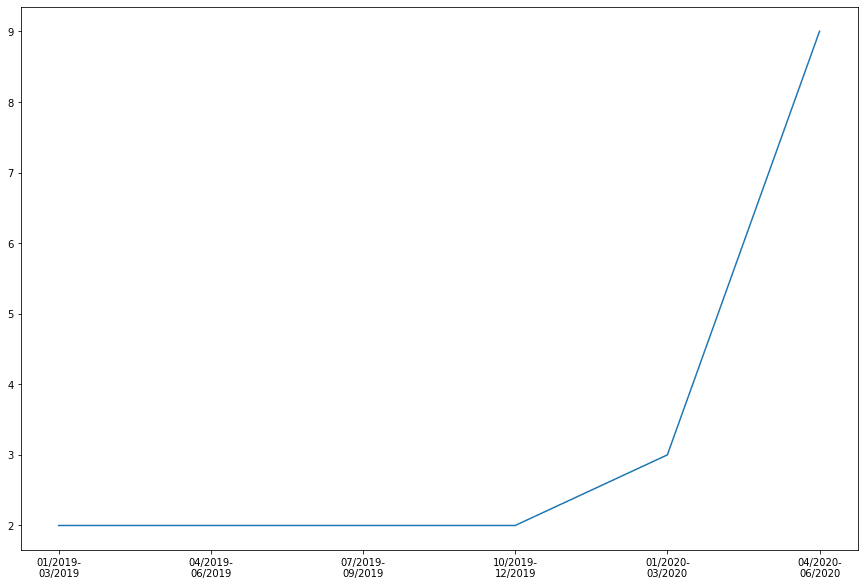
You can see Jupyter Notebook query in our GitLab repo
Future Work
This is just a very introductory analysis to measure covid-19 impact on Jitsi. Of course, we can improve a lot of things. Some future work might be:
Improve author affiliation: We know an existing open source tooling called SortingHat, that can be implemented with Perceval and other GrimoireLab components. SortingHat is an identity affiliation management. Thus, identities corresponding to the same real person can be merged in the same unique identity with a unique uuid.
Filter “unknown” category within gender term: Maybe gender-guesser package is not the best one to use. Do you know other python packages we can use? Leave your comments below :)
Work on new metric for risk assessment, such as the Gini coefficient.
And last but not least: Correlation does not imply causation. We don’t have all the domain knowledge Jitsi maintainers and community specialists might have. A relationship between Covid-19 and contributor's activity might be just coincidence





Top comments (0)