When doing event-driven applications using Kafka, on the consumer side, after receiving the Kafka message, your application needs to do something with it. For this blog post, let's call this part "Processing the message".
What is Kafka again?
But before we dive into that, let's make sure we're all on the same page and refresh our memory on what exactly Kafka is.
Apache Kafka is a super powerful distributed streaming platform that allows applications to process, store, and analyze large streams of data in real time. It's built to handle a high volume, high throughput, and low latency data streams.
In Kafka, a consumer is an application that reads messages from one or more topics. Consumers subscribe to one or more topics and consume the messages that are produced on those topics. Consumers keep track of the offset of the messages that they have consumed so that they can pick up where they left off in case of failures or restarts.
Consumers can also be part of a consumer group, where each consumer in the group is assigned a subset of the partitions for a topic, allowing for parallel consumption of the data.
Working with examples
Now that we're all on the same page, let's create an example. Imagine you work for a company named ACME, and you have a Kafka topic that receives a new message every time a new customer is created. This customer needs to receive an email saying that their account is fully created and that they need to verify their email.
When we read something like "when something happens" do "something else," always think about events! Events, in Kafka, are messages!
We're going to create a microservice that will:
- Receive this new customer message from Kafka.
- Compose a nice email.
- Send it to the customer.
- Add a new message to another topic saying that the message was sent!
Let's diagram that for more visibility:

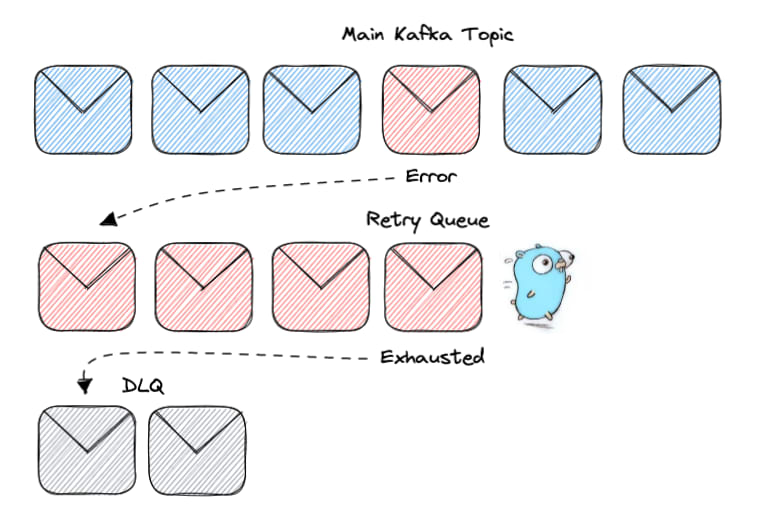
Where are the retries?
Cool, but, this is a blog post about retries right? Where are the retries in all of it?
Well, any part of the processing can go wrong, and we don't want our customers to miss out on their account creation emails, do we? So, let's talk about a few things that could go wrong and how we can handle them with retries:
- The email template database might be down. No problem, we'll just keep trying to connect until it's back up.
- The template persisted inside of it might be invalid. We'll check for this and alert the team to update it if needed.
- The SMTP server might be down or drop a message. We'll keep trying to send the email until it goes through.
- The application might compose the SMTP message badly and the SMTP server reject it. We'll catch this error and fix the composition before trying again.
- Producing the message to the other Kafka topic might return an error on Kafka's server side. We'll keep trying until it's successfully sent.
Some of the errors mentioned may require code or data modifications to resolve, such as updating a template or correcting the way the application composes an SMTP message. These types of errors may not be suitable for retries as they may require manual intervention.
On the other hand, other errors such as temporary database downtime, flaky message production, or overloaded SMTP servers can potentially be resolved by retrying the operation.
Unlocking Kafka Consumer Retries
As a daily challenge in several of our microservices, the lack of a built-in retry mechanism in Kafka can be frustrating. I've experimented with various software architectures for retrying message processing, but none of them was the perfect solution - but there's one that's easiest to deal with.
Before diving into the solution, let me share some background on my previous attempts.
AWS SQS: A Great Option, But With Limitations
As a strong advocate for AWS, my first thought when considering retries was AWS SQS.
Amazon Simple Queue Service (SQS) is a fully managed message queuing service that enables the decoupling and scaling of microservices, distributed systems, and serverless applications. It comes with built-in retry capabilities, such as a backoff algorithm, a maximum retry limit before moving to a dead-letter queue, and supports a maximum message size of 256 KB.
While SQS is a great option for retries, it falls short when it comes to messaging size. Kafka messages can have a size of up to 1 MB by default and can even exceed that.
But then you tell me "OK Alex, but that's not a big deal", well it kinda is, because we have no good way of controlling the message size, it can grow and break your application without you even realizing it! And by that time you will have lost messages or will have a big production incident on your hands.
So, while SQS is a great option, it's not the best fit for our Kafka-based microservices. But don't worry, we've found a solution that works even better.
Kafka
Yes, that's exactly it, since SQS isn't a suitable solution, why not use Kafka itself?
I attempted to create an internal application Kafka topic that would only be used by the application, where the application would push messages to it, and in case of a failure, it would enqueue the message again with a new count attribute in the header. Let me diagram that to make it more clear:
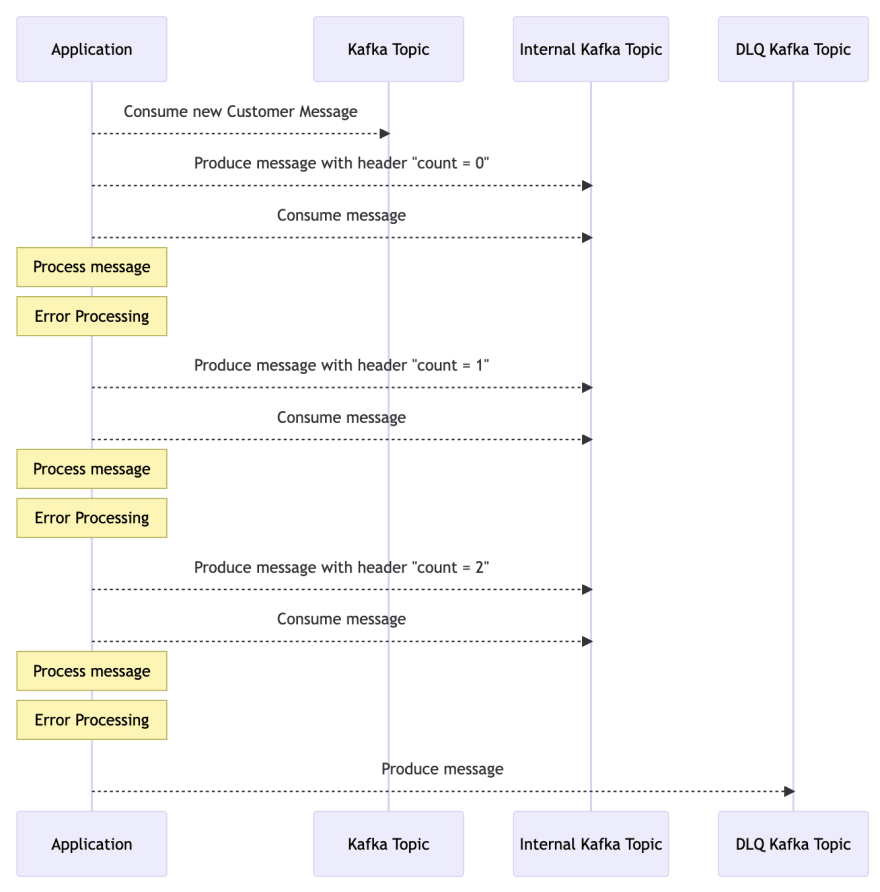
While this approach does work, it has some significant downsides. Firstly, setting up Kafka topics is not as straightforward as SQS, creating multiple topics can be somewhat cumbersome, and dealing with all the consumers and producers within the code can become quite messy.
Furthermore, Kafka doesn't support retries built-in. This is because the Kafka protocol is designed for high-throughput and low-latency data streaming, and retries add overhead and complexity to the system.
Databases
Desperate Times Call for Desperate Measures, right?
As a last resort, I turned to use databases for message retries. Modern SQL databases have LOCKING mechanisms that can be leveraged to use a table as a queue.

To my surprise, this approach worked! However, it's not a perfect solution. Databases are not designed to function as queues, and using them in this way can be a stretch. There are a few downsides to this approach:
- Databases are built for consistency using transactions, which can make them performant, but they will never perform as well as a specialized tool like Kafka. This can easily become a bottleneck in the system.
- Managing all of this code can easily become problematic, and it is not an easy pattern to share across an entire company.
So, what now? Memory!
After trying all of the above solutions and being unsatisfied with the results, I decided to look at how other companies and frameworks handle retries.
One framework that stood out to me is Spring, an open-source Java framework that provides a comprehensive programming and configuration model for building modern enterprise applications.
The Spring way
One of the modules within Spring is Spring Kafka, which provides several ways to handle retries when consuming messages. These include using the RetryTemplate and RetryCallback interfaces from the Spring Retry library to define a retry policy, using the @KafkaListener annotation to configure retry behavior on a per-method basis, or using AOP to handle retries by using a RetryInterceptor.
Spring Kafka allows developers to choose the approach that best fits their use case, whether it is a global retry policy or a more fine-grained per-method retry configuration.
Has been a long time since I don't work with Java, and Spring code is far from easy to understand (it's pretty advanced stuff), but after diving deeper into the Spring Kafka framework, I discovered that it implements an error handler using a strategy for handling exceptions thrown by the consumers.
When an exception that is not a BatchListenerFailedException (which Spring knows is impossible to retry) is thrown, the error handler will retry the batch of records from memory. This prevents a consumer rebalance during an extended retry sequence and allows for a more elegant solution.
In my honest opinion, the Spring Kafka framework offers a robust and flexible approach to handling retries that is well worth considering for any enterprise application.
It provides a range of options for developers to choose from and allows for more fine-grained control over retry behavior, making it a great choice for any organization looking to implement a retry mechanism for their messaging system.
Recreating Spring Kafka's Retry Mechanism in Go
I currently work with (and love 💙) Go, and, as far as my research went, I didn't find any rewrite of the Spring Kafka and Retry framework in Go, so, let's build our own!
Here, I want to point out one key difference in my implementation compared to Spring Kafka's approach. I appreciate the idea of pausing the Consumer and going back to the previous record of the batch in case of a catastrophic failure. However, I don't believe it's necessary and have chosen to implement it differently.
My approach includes:
- Creating a Consumer that reads from the topic.
- Creating a Go channel that handles retries.
- If a message fails to process, it is sent to the retry channel.
- The main consumer continues to process the main topic while the other messages are retried.
- If retries are exhausted, the message is sent to a persisted DLQ for later investigation.
⚠️ It's important to note that this approach assumes that your application doesn't strongly rely on the order of the messages. If that is the case, you will need to stop the consumer while retrying a message. This approach, however, allows for progress to be made on the topic while retries are being attempted.
Here's the code
Explanation in plain text
The kafka_retry_dlq package provides a mechanism for consuming messages from a Kafka topic with a retry mechanism in case of processing errors.
Types
-
ProcessRetryHandler: An interface that must be implemented by types that will handle the processing of messages. It has the following methods:-
Process(context.Context, kafka.Message) error: processes a message, returns an error if the processing failed. -
MoveToDLQ(context.Context, kafka.Message): moves a message to the dead letter queue. -
MaxRetries() int: returns the maximum number of retries for a message. -
Backoff() backoff.BackOff: returns a backoff strategy for retrying a message.
-
Variables
-
retryQueue: A channel ofkafka.Messagewith a buffer of 1000 messages.
Functions
-
NewConsumerWithRetry(ctx context.Context, brokers []string, topic string, partition int, handler ProcessRetryHandler): creates a new Kafka consumer with a retry mechanism.- It creates a new Kafka reader with the provided brokers, topic, partition, and buffer size.
- It starts a goroutine that reads messages from the Kafka topic and processes them using the provided
handler. - If the processing of a message returns an error, the message is sent to the
retryQueuechannel. - It starts another goroutine that listens to the
retryQueuechannel and processes the messages with the providedhandleruntil the maximum number of retries is reached or the message is successfully processed. - If the maximum number of retries is reached, the message is moved to the dead letter queue using the
MoveToDLQmethod of thehandler.
In conclusion
Retries play an important role in improving the resiliency of event-driven systems by allowing them to handle unexpected failures and errors. However, it's crucial to also combine retries with metrics, Service Level Objectives (SLOs), and Service Level Agreements (SLAs) to ensure that the system is not in a faulty state all the time. The goal is to only have the application retry in exceptional cases, and the combination of retries with SLOs and SLAs helps to guarantee this.





Latest comments (0)