![Cover image for WebScraping [Part-1]](https://media.dev.to/cdn-cgi/image/width=1000,height=420,fit=cover,gravity=auto,format=auto/https%3A%2F%2Fdev-to-uploads.s3.amazonaws.com%2Fi%2Fugnoe4u4u31ea8hrdgto.jpeg)
 aletisunil
/
Scraping_IMDB
aletisunil
/
Scraping_IMDB
Scrapes the movie title, year, ratings, genre, votes
Hey everyone,
You doesn't need to be a guru in python, just a basics of HTML and python is sufficient for this web scraping tutorial.
Let's dive in..
The tools we're going to use are:
- Request will allow us to send HTTP requests to get HTML files
- BeautifulSoup will help us parse the HTML files
- Pandas will help us assemble the data into a DataFrame to clean and analyze it
- csv(optional)- If you want to share data in csv file format
Let's Begin..
In this tutorial, we're going to scrape IMDB website, which we can get title, year, ratings, genre etc..
First, we'll import the tools to build our scraper
import requests
from bs4 import BeautifulSoup
import pandas as pd
import csv
Getting the contents of webpage into results variable
url = "https://www.imdb.com/search/title/?groups=top_1000"
results = requests.get(url)
In order to make content easy to understand, we are using BeautifulSoup and the content is stored in soup variable
soup = BeautifulSoup(results.text, "html.parser")
And now initializing the lists to store data
titles = [] #Stores the title of movie
years = [] #Stores the launch year of the movie
time = [] #Stores movie duration
imdb_ratings = [] #Stores the rating of the movie
genre = [] #Stores details regarding genre of the movie
votes = [] #Store the no.of votes for the movie
Now find the right movie container by inspecting it, and hover over the movie div, which looks like below image
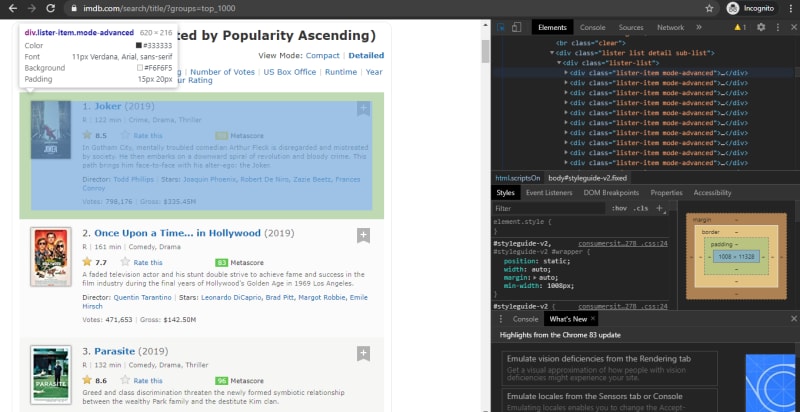
And we can see 50 div with class names:lister-item mode-advanced
So, find all div's with that classname by
movie_div = soup.find_all("div", class_="lister-item mode-advanced")
find_all attribute extracts all the div's which has class
name:"lister-item mode-advanced"
Now get into each lister-item mode-advanced div and get the title, year, ratings, genre, movie duration
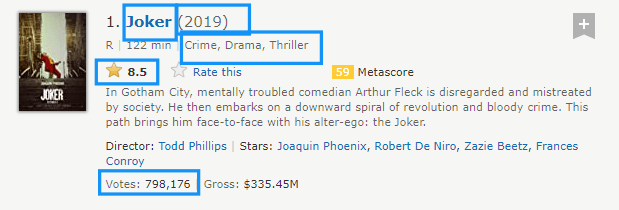
So we iterate every div to get title, year, ratings etc..
for movieSection in movie_div:
Extracting the title
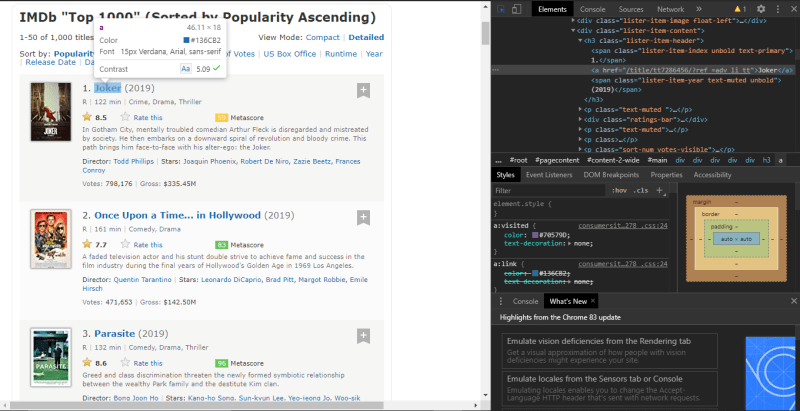
From image, we can see that the movie name is placed under div>h3>a
name = movieSection.h3.a.text #we're iterating those divs using <b>movieSection<b> variable
titles.append(name) #appending the movie names into <b>titles</b> list
Extracting Year
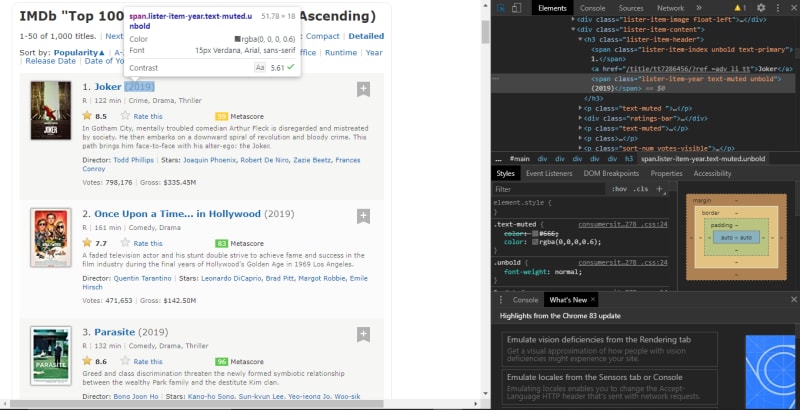
From image, we can see that the movie launch year is placed under div>h3>span(class name="lister-item-year") and we extract it using text keyword
year = movieSection.h3.find("span", class_="lister-item-year").text
years.append(year) #appending into years list
Similarly, we can get ratings, genre, movieDuration w.r.t classname
ratings = movieSection.strong.text
imdb_ratings.append(ratings) #appending ratings into list
category = movieSection.find("span", class_="genre").text.strip()
genre.append(category) #appending category into Genre list
runTime = movieSection.find("span", class_="runtime").text
time.append(runTime) #appending runTime into time list
Extracting votes

As from the image, we can see that we have two span tags with classname="nv". So, for votings we need to consider nv[0] and for gross collections nv[1]
nv = movieSection.find_all("span", attrs={"name": "nv"})
vote = nv[0].text
votes.append(vote)
Now we will build a DataFrame with pandas
To store the data we have to create nicely into a table, so that we can really understand
And we can do it..
movies = pd.DataFrame(
{
"Movie": titles,
"Year": years,
"RunTime": time,
"imdb": imdb_ratings,
"Genre": genre,
"votes": votes,
}
)
And now let's print the dataframe

As we can see on row 16 and 25, there is some inconsistent of data. So we need to clean
movies["Year"] = movies["Year"].str.extract("(\\d+)").astype(int) #Extracting only numerical values. so we can commit "I"
movies["RunTime"] = movies["RunTime"].str.replace("min", "minutes") #replacing <b>min</b> with <b>minutes</b>
movies["votes"] = movies["votes"].str.replace(",", "").astype(int) #removing "," to make it more clear
And now after cleaning we will see, how it looks
print(movies)
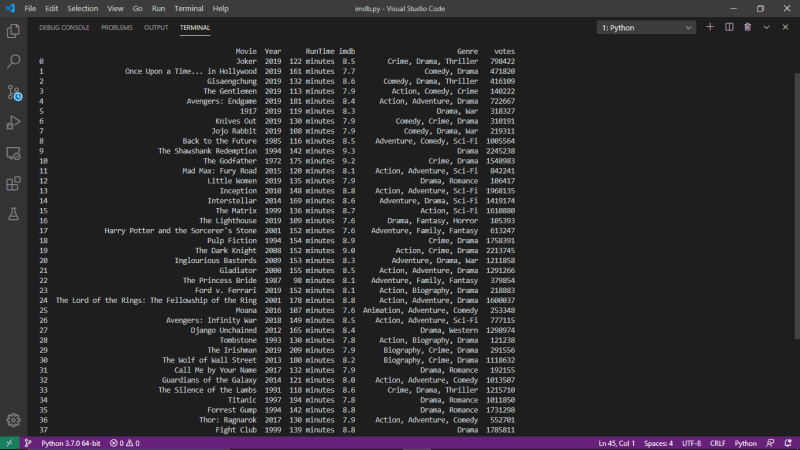
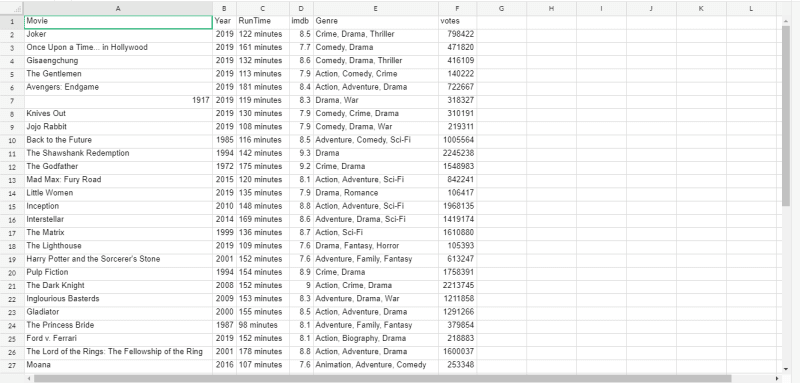
You can also export the data in .csv file format.
In order to export,
Create a file with .csv file extension
movies.to_csv(r"C:\Users\Aleti Sunil\Downloads\movies.csv", index=False, header=True)
You can get Final code from my Github repo
In my next part, I’ll explain how to loop through all of the pages of this IMDb list to grab all of the 1,000 movies, which will involve a few alterations to the final code we have here
Hope it's useful
A ❤️ would be Awesome 😊





Top comments (12)
Good tutorial. Well explained..!
Thanks 😊
how to scrap news post in bulk which are dynamic? I searched lot unable to find
Yes, it's very difficult to scrape dynamic sites because the data is loaded dynamically with JavaScript.
In such cases, we can use the following two techniques:
And will definitely make a tutorial in future 🤞
You can download most IMDB data without scraping their website. They provide bulk download options in tab-separated format (TSV) files:
datasets.imdbws.com/
The only glaring thing missing from the dataset is MPAA/TV rating codes. But everything you show in your final spreadsheet is readily available in those dataset files.
I recently used the IMDB dataset plus a couple of other datasets to programmatically produce a ranked list of the Top 250 family-friendly movies of all time:
cubicspot.blogspot.com/2020/02/the...
It was an ambitious multi-week project to gather all the data, merge roughly three disparate datasets together without common keys within a 5.4GB SQLite database, and finally generate the list. The oldest movie in the list is from 1925! But, yeah, if you are looking for IMDB's data, they basically make it available without scraping their website.
The main aim of this tutorial is to make understand people "How and What is Scraping?" I dont have any intentions or work to scrape data. It's just a popular website and it also is easy to explain through this website 🙂
It's against IMDB's Terms of Service (ToS) to scrape their content. Not that their ToS has actually stopped anyone in the past from scraping their site, my response was just to point out an alternative to scraping their content that doesn't violate their ToS.
Scraping websites of private entities is a legal minefield. U.S. government websites, however, are completely legal to scrape as all of the content on them is in the public domain and they usually have data worth scraping that's more up-to-date than what shows up on data.gov. There are also massive multi-petabyte public datasets on Amazon S3 available too that require the use of a scraper toolset to properly retrieve and process (e.g. commoncrawl.org/the-data/get-started/) but that might be a tad more advanced than a beginner's tutorial might be able to cover.
Anywho, just a couple of thoughts.
Any public data is legally scrapable by law. And it should remain legal.
Terms of Service are unsigned contracts unless you sign the contract by doing something like create an account and agree to the ToS. Then contract law may apply and "no scraping" clauses in such contracts might be legally binding. I'm not a lawyer but the law is a lot more complex than you think and each region of jurisprudence is different in how it applies its own laws. Your blanket assertion that scraping anything published on a website is legal is false. If someone has to login to obtain content (i.e. agree to a ToS) or they knowingly obtain content that is known to be sourced via illegal means, then civil or even criminal actions can be taken against that person.
Legal issues aside, web server operators can also block those who make excessive requests to their servers. IMDB has official data dumps of their database. It's not perfect since some information is missing but it is a good enough starting point for most purposes. Since IMDB makes data dumps available for direct download and is more efficient than scraping, IMDB has every right to block anyone scraping their main website.
Awesome
simple and precise explanation
Thanks