MariaDB's ColumnStore is an engine that stores data in a columnar fashion. Although it shines in distributed architectures where you have a massive amount of data, you can see non-trivial performance improvements in single-instance architectures. This article shows how to:
- install ColumnStore using Docker in your development machine,
- create a simple Java web application to generate realistic test data,
- run test SQL queries to compare execution times of the ColumnStore vs InnoDB engines.
To follow this article, you need Java, a Java IDE, and Docker installed on your computer.
What is ColumnStore?
ColumnStore is a pluggable engine for MariaDB and MySQL. You can install it on top of an existing database instance. It is possible to have tables in the same database using multiple storage engines. For example, you can create a table called book for OLTP using the general-purpose InnoDB engine, and a table called book_analytics for OLTP using the column-oriented ColumnStore engine. Both tables can live in the same database schema and you can run queries that mix the two. Check these online resources to learn more about OLTP/OLAP and the different storage engines available in MariaDB:
- The place between transactions and analytics – and what it means for you
- Choosing the Right Storage Engine
Installing MariaDB and ColumnStore using Docker
Make sure you have Docker installed and running on your machine and use the following commands to download an image and create a container with CentOS, MariaDB and ColumnStore preconfigured:
docker pull mariadb/columnstore
docker run -d -p 3306:3306 --name mariadb_columnstore mariadb/columnstore
Configuring the database
If you want to configure the instance you can connect to the container using:
docker exec -it mariadb_columnstore bash
For example, you can edit the /etc/my.cnf file to increase the buffer pool size (this is an optional step):
[mysqld]
innodb_buffer_pool_size=1G
Remember to restart the container when you make this kind of change:
docker restart mariadb_columnstore
Connecting to the MariaDB instance
Use any SQL client that supports MariaDB to connect to the instance. For example, you can use IntelliJ IDEA's database view, or the command-line tool, mariadb. If you have MariaDB in your host machine, you already have the tool:
mariadb --protocol tcp -u user -p
Since a Docker container is not really a virtual machine, you connect to the database like if it was running natively on your matching, that is, the host is localhost.
Setting up the test user and tables
Create a new database user:
docker exec mariadb_columnstore mariadb -e "GRANT ALL PRIVILEGES ON *.* TO 'user'@'%' IDENTIFIED BY 'password';"
Create a new database schema and two tables, one using the InnoDB engine and another using ColumnStore:
CREATE DATABASE book_demo;
USE DATABASE book_demo;
CREATE TABLE book
(
id int(11) NOT NULL AUTO_INCREMENT,
title varchar(255) DEFAULT NULL,
author varchar(255) DEFAULT NULL,
publish_date date DEFAULT NULL,
pages int(8) DEFAULT NULL,
image_data longtext DEFAULT NULL,
PRIMARY KEY (id)
) engine = InnoDB;
CREATE TABLE book_analytics
(
id int(11) NOT NULL,
title varchar(255) DEFAULT NULL,
author varchar(255) DEFAULT NULL,
publish_date date DEFAULT NULL,
pages int(8) DEFAULT NULL
) engine = ColumnStore;
Generating test data using Java
Create a new project using the Spring Initializr and add the Spring Data JPA, MariaDB Driver, Lombok, and Vaadin dependencies. Also, add the following dependency to the pom.xml file:
<dependency>
<groupId>com.vaadin</groupId>
<artifactId>exampledata</artifactId>
<version>4.0.0</version>
</dependency>
Configure the database connection in the application.properties file:
spring.datasource.url=jdbc:mariadb://localhost:3306/book_demo
spring.datasource.username=user
spring.datasource.password=password
Create a new JPA Entity class to encapsulate the test data and persist it in a table row:
package com.example;
import lombok.Data;
import lombok.EqualsAndHashCode;
import javax.persistence.*;
import java.time.LocalDate;
@Data
@EqualsAndHashCode(onlyExplicitlyIncluded = true)
@Entity
@Table(name = "book")
public class Book {
@EqualsAndHashCode.Include
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Integer id;
private String title;
private String author;
private LocalDate publishDate;
private Integer pages;
@Lob
private String imageData;
}
Create a new repository:
package com.example;
import org.springframework.data.jpa.repository.JpaRepository;
import org.springframework.stereotype.Repository;
@Repository
public interface BookRepository extends JpaRepository<Book, Integer> {
}
Create a service class with logic to generate realistic random test data in batches:
package com.example;
import com.vaadin.exampledata.ChanceIntegerType;
import com.vaadin.exampledata.DataType;
import com.vaadin.exampledata.ExampleDataGenerator;
import lombok.RequiredArgsConstructor;
import lombok.extern.log4j.Log4j2;
import org.springframework.stereotype.Service;
import java.time.LocalDateTime;
import java.util.List;
import java.util.Random;
@Service
@RequiredArgsConstructor
@Log4j2
public class GeneratorService {
private final BookRepository repository;
public void generate(int batchSize, int batches) {
var generator = new ExampleDataGenerator<>(Book.class, LocalDateTime.now());
generator.setData(Book::setTitle, DataType.BOOK_TITLE);
generator.setData(Book::setAuthor, DataType.FULL_NAME);
generator.setData(Book::setPublishDate, DataType.DATE_LAST_10_YEARS);
generator.setData(Book::setPages, new ChanceIntegerType("integer", "{min: 20, max: 1000}"));
generator.setData(Book::setImageData, DataType.BOOK_IMAGE_URL);
for (int batchNumber = 1; batchNumber <= batches; batchNumber++) {
List<Book> books = generator.create(batchSize, new Random().nextInt());
repository.saveAllAndFlush(books);
log.info("Batch " + batchNumber + " completed.");
}
}
}
Create a web UI:
package com.example;
import com.vaadin.flow.component.button.Button;
import com.vaadin.flow.component.html.H1;
import com.vaadin.flow.component.notification.Notification;
import com.vaadin.flow.component.orderedlayout.VerticalLayout;
import com.vaadin.flow.component.textfield.IntegerField;
import com.vaadin.flow.router.PageTitle;
import com.vaadin.flow.router.Route;
import lombok.extern.log4j.Log4j2;
@Route("")
@PageTitle("Data generator")
@Log4j2
public class GeneratorView extends VerticalLayout {
public GeneratorView(GeneratorService service) {
var batchSize = new IntegerField("Batch size");
var batches = new IntegerField("Batches");
Button start = new Button("Start");
start.addClickListener(event -> {
service.generate(batchSize.getValue(), batches.getValue());
Notification.show("Data generated.");
});
add(new H1("Data generator"), batchSize, batches, start);
}
}
Running the generator web application
The project includes an Application class with a standard Java entry point method. Run this application as you would with any other Java application using your IDE or the command line with Maven (make sure to use the name of the JAR file that your project generated):
mvn package
java -jar target/test-data-generator-0.0.1-SNAPSHOT.jar
The first build and run of the application take time, but further builds and runs will be faster. You can invoke the application in the browser at http://localhost:8080:
I generated 100 batches of 10000 rows each for a million rows in the database. This takes some time. Check the log if you want to see the progress.
Challenge: Try using the ProgressBar class, the @Push annotation, and the UI.access(Command) to show the progress in the browser.
Running a simple ETL process for analytics
To populate the book_analytics table, we can execute a simple SQL INSERT statement that serves as an Extract, Transform, Load (ETL) process. In concrete, the image_data column stores the image potentially used in a web application that shows the cover of a book. We don't need this data for OLAP, which is the reason we didn't include the image_data column in the book_analytics table. Populate the data with the following SQL statement:
INSERT INTO book_analytics(id, author, pages, publish_date, title)
SELECT id, author, pages, publish_date, title FROM book;
The process should take only a few seconds for a million rows.
Comparing the performance of analytical queries
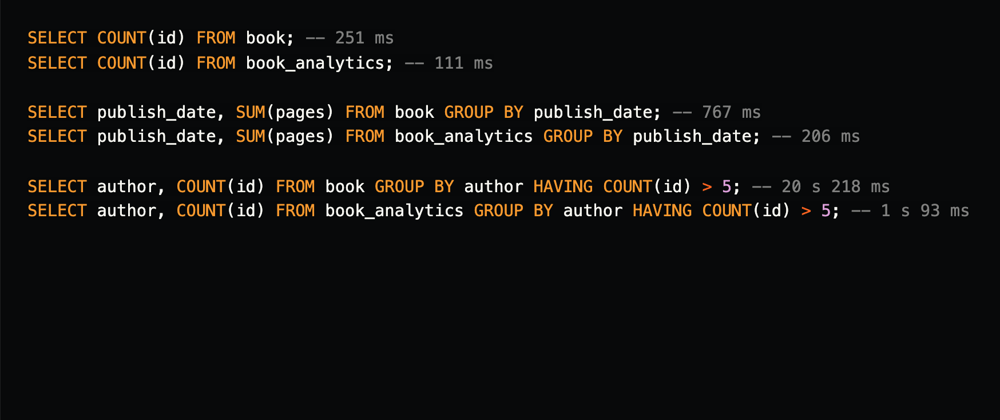
Below are some examples of queries that you can use to compare the performance of the ColumnStore engine vs InnoDB. I used an empiric approach and run each query several times (5 to 10 times) taking the fastest run for each. Here are the results:
SELECT COUNT(id) FROM book; -- 251 ms
SELECT COUNT(id) FROM book_analytics; -- 111 ms
SELECT publish_date, SUM(pages) FROM book GROUP BY publish_date; -- 767 ms
SELECT publish_date, SUM(pages) FROM book_analytics GROUP BY publish_date; -- 206 ms
SELECT author, COUNT(id) FROM book GROUP BY author HAVING COUNT(id) > 5; -- 20 s 218 ms
SELECT author, COUNT(id) FROM book_analytics GROUP BY author HAVING COUNT(id) > 5; -- 1 s 93 ms
The biggest difference is in the last query. 20 seconds vs 2 seconds approximately. All the queries show a non-trivial advantage in favor of ColumnStore.
Take into account that for other kinds of database operations, ColumnStore could be slower than InnoDB. For example, queries that read several columns without aggregate functions involved. Always make informed decisions and experiment with queries before deciding on InnoDB, ColumnStore, or other engines for your database tables.





Latest comments (0)