
Open-source data integration is not new. It started 16 years ago with Talend. But since then, the whole industry has changed. The likes of Snowflake, Bigquery, Redshift have changed how data is being hosted, managed, and accessed, while making it easier and a lot cheaper. But the data integration industry has evolved as well.
On one hand, new open-source projects emerged, such as Singer.io in 2017. This enabled more data integration connectors to become accessible to more teams, even though it still required a significant amount of manual work.
On the other hand, data integration was made accessible to more teams (analysts, scientists, business intelligence teams). Indeed, companies like Fivetran benefited from Snowflake’s rise, empowering non-engineering teams to set up and manage their data integration connectors by themselves, so they can use and work on the data in an autonomous way.
But even with this progress, a large majority of teams still build their own connectors in-house. The build vs. buy leans strongly on the build. That’s why we think it’s time to have a fresh new look at the landscape of the open-source technologies around data integration.
However, the idea for this article came from an awesome debate on DBT’s Slack last week. The discussion centered around two things:
- The state of open-source alternatives to Fivetran, and
- Whether an open-source (OSS) approach is more relevant than a commercial software approach in addressing the data integration problem.
Even Fivetran’s CEO was involved in the debate.

We already synthetized the second point in a previous article. In this article, we want to analyze the first point: the landscape of open-source data integration technologies.
TL;DR
Here is a table summarizing our analysis.
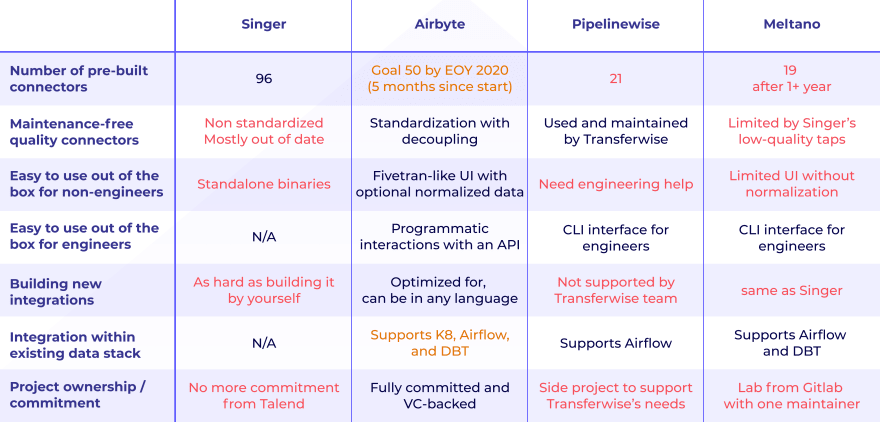
In orange is what we’re currently building at Airbyte in the next few weeks.
To better understand this table, we invite you to read below the details of our analysis on the landscape.
Data integration open-source projects
Singer
Singer was launched in 2017, and was until now the most popular open-source project. It was initiated by StitchData, which was founded in 2016. Over the years, Singer grew to support 96 taps and targets.
- Increasingly outdated connectors: Talend (acquirer of StitchData) seems to have stopped investing in maintaining Singer’s community and connectors. As most connectors see schema changes several times a year, more and more Singer’s taps and targets are not actively maintained and are becoming outdated.
- Absence of standardization: each connector is its own open-source project. So you never know the quality of a tap or target until you have actually used it. There is no guarantee whatsoever about what you’ll get.
- Singer’s connectors are standalone binaries: you still need to build everything around to make them work.
- No full commitment to open sourcing all connectors, as some connectors are only offered by StitchData under a paid plan.
In the end, a lot of teams will use StitchData for the connectors that work well, and will build their own integration connectors if they don’t work out of the box. Editing a Singer connector is not easier than building and maintaining the connector yourself. This defeats the purpose of open source.
Airbyte
Airbyte was born in July 2020, so it is still new. It was born out of frustration with Singer and other open-source projects. It was built by a team of data integration veterans from Liveramp, who individually built and maintained more than 1,000 integrations, so 8 times more than Singer. Their ambition is to support 50+ connectors by the end of 2020, so in just 5 months since the inception of the project.
Airbyte’s mission is to commoditize data integration, and we have made several significant choices towards this goal:
- Airbyte’s connectors are usable out of the box through a UI and API, with monitoring, scheduling and orchestration. Airbyte was built on the premise that a user, whatever their background, should be able to move data in 2 minutes. Data engineers might want to use raw data and their own transformation processes, or to use Airbyte’s API to include data integration in their workflows. On the other hand, analysts and data scientists might want to use normalized consolidated data in their database or data warehouses. Airbyte supports all these use cases.
- One platform, one project with standards: This will help consolidate the developments behind one single project, some standardization and specific data protocol that can benefit all teams and specific cases.
- Connectors can be built in the language of your choice, as Airbyte runs them as Docker containers.
- Decoupling of the whole platform to let teams use whatever part of Airbyte they want based on their needs and their existing stack (orchestration with Airflow, Kubernetes, or Airbyte, transformation with DBT or again Airbyte, etc.). Teams can use Airbyte’s orchestrator or not, their normalization or not; everything becomes possible.
- A full commitment to the open-source MIT project with the promise not to hide some connectors behind paid walls.
The number of connectors supported by Airbyte and its community is growing fast. Their team anticipates that it will outgrow Singer’s by early 2021. Note that Airbyte’s data protocol is compatible with Singer’s. So it is easy to migrate a Singer tap onto Airbyte, too.
PipelineWise
PipelineWise is an open-source project by Transferwise that was built with the primary goal to serve their own needs. They support 21 connectors, and add new ones based on the needs of the mother company. There is no business model attached to the project, and no apparent interest from the company in growing the community.
- As close to the original format as possible: PipelineWise aims to reproduce the data from the source to an Analytics-Data-Store in as close to the original format as possible. Some minor load time transformations are supported, but complex mapping and joins have to be done in the Analytics-Data-Store to extract meaning.
- Managed Schema Changes: When source data changes, PipelineWise detects the change and alters the schema in your Analytics-Data-Store automatically.
- YAML based configuration: Data pipelines are defined as YAML files, ensuring that the entire configuration is kept under version control.
- Lightweight: No daemons or database setup are required. Compatible with Singer’s data protocols: PipelineWise is using Singer.io compatible taps and target connectors. New connectors can be added to PipelineWise with relatively small effort.
Meltano
Meltano is an orchestrator dedicated to data integration, built by Gitlab on top of Singer’s taps and targets. Since 2019, they have been iterating on several approaches. They now have one maintainer for this project that is CLI-first. After one year, they now support 19 connectors.
- Built on top of Singer’s taps and targets: Meltano has the same limitations as Singer’s in regards to its data protocol.
- CLI-first approach: Meltano was primarily built with a command line interface in mind. In that sense, they seem to target engineers with a preference for that interface.
- A new UI: Meltano has recently built a new UI to try to appeal to a larger audience.
- Integration with DBT for transformation: Meltano offers some deep integration with DBT, and therefore lets data engineering teams handle transformation any way they want.
- Integration with Airflow for orchestration: You can either use Meltano alone for orchestration or with Airflow; Meltano works both ways.
Related noteworthy open-source projects
Here are some other open-source projects that you might have heard of, as they’re often used by data engineering teams. We thought they deserved to be mentioned.
Apache Airflow
We see a lot of teams building their own data integration connectors using Airflow for the orchestration and scheduling. Airflow wasn’t built with data integration in mind. But a lot of teams use it to build workflows. Airbyte is the only open-source project to offer an API so teams can include data integration jobs in their workflows.
DBT
DBT is the most widely used data transformation open-source project. You need to be proficient in SQL to use it properly, but a lot of data engineering / integration teams use it to normalize raw data coming into the warehouses or databases.
Both Airbyte and Meltano are compatible with DBT. Airbyte will offer teams the ability to choose between raw or normalized data for each connection they need, which addresses the needs of both data engineering and data analyst teams. Meltano doesn’t provide normalized schemas, and relies solely on DBT for that.
Apache Camel
Apache Camel is an open-source rule-based routing and mediation engine. That means you get smart completion of routing rules in your IDE whether in your Java, Scala, or XML editor. It uses URIs to enable easier integration with all kinds of transport and messaging models including HTTP, ActiveMQ, JMS, JBI, SCA, MINA and CXF, together with working with pluggable Data Format options.
Streamsets
Streamsets is a data-ops platform that includes a low-level open-source data collection engine named DataCollector. This open-source project is not supported by any community, and is mostly used by the company to assure their enterprise clients that they will still have access to the code whatever happens.
Let us know if we missed any open-source projects or any valuable information on the listed ones. We will try to keep this list up to date and precise.





Top comments (1)
hi, want to know more