
In this blog post I’ll be giving a brief and basic introduction regarding Apache Kafka and the terminology that would be necessary to know in order to get started with Kafka.
You can check out the full article here
Kafka — What is it?
In a nutshell, Kafka is a distributed system that allows multiple services to communicate with each other via its queue based architecture. With that out of the way, let’s get to know about some basic Kafka terminology. Let’s get started ;)
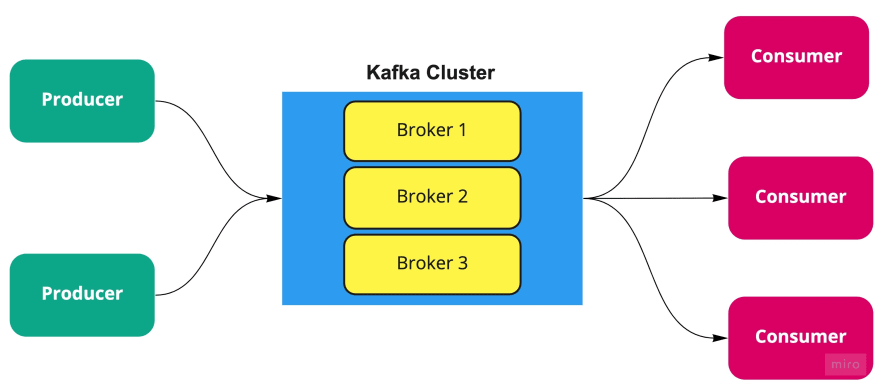
Broker: A Broker is a server which has Kafka running on it and is responsible for the communication between multiple services. Multiple brokers would form a Kafka cluster.
Event: The messages that are produced to or consumed from the Kafka broker are called events. These messages are stored in the form of bytes in the broker’s disk storage.
Producer and Consumer: The services that produce these events to Kafka broker are referred to as Producers and those which consume these events are referred to as Consumers. It could also be possible that the same service can both produce and consume messages from Kafka.
Topic: In order to differentiate the type of events stored in Kafka, topics are used. In short, a topic is like a folder in a file system where only events or messages related to a specific type are stored. For example: “payment-details”, “user-details”, etc.
Partition: A topic can be further divided into partitions in order to attain higher throughput. It is the smallest storage unit which holds a subset of data of a topic.
Replication Factor: A replica of a partition is a backup of that partition. The replication factor of a topic decides how many replicas of a partition in that topic should be maintained by the Kafka cluster. A topic with partition as 1 and replication factor as 2 would mean that two copies of the same partition with same data would be stored in the Kafka cluster.
Offset: To keep a track of which events have already been consumed by the consumer, an index pointing to the latest consumed message is stored inside Kafka, this index is called the offset and helps keep a track of which events have already been consumed by the consumer. So if a consumer were to go down, this offset value would help us know exactly from where the consumer has to start consuming events. A producer producing messages to a kafka topic with 3 partitions would look like this:

Zookeeper: Zookeeper is an extra service present in the Kafka cluster that helps maintain the cluster ACLs, , stores the offsets for all the partitions of all the topics, used to track the status of the Kafka broker nodes and maintain the client quotas (how much data a producer/consumer is allowed to read/write)
Consumer Group: A bunch of consumers can join a group in order to cooperate and consume messages from a set of topics. This grouping of consumers is called a Consumer Group. If two consumers have subscribed to the same topic and are present in the same consumer group, then these two consumers would be assigned a different set of partitions and none of these two consumers would receive the same messages. Consumer Groups can help attain higher consumption rate, if multiple consumers are subscribed to the same topic.
You can check out the next article of the Kafka series here
Follow for the next Kafka blog in the series. I shall also be posting more articles talking about Software engineering concepts.





Latest comments (0)