C++ has out of the box cross-platfrorm atomic operations since C++11.
There are several types of atomic operations.
Here I want to compare 2 types of them:
-
atomic_fetch_add,atomic_fetch_sub, etc... atomic_compare_exchange
This kind of atomic ops existed in computer programming long before C++11.
For example Compare-and-swap (CAS) and Fetch-and-add (FAA) where implemented as CPU instructions in Intel 80486 - CMPXCHG and XADD.
Here I will not talk about origin of atomic operations and problem they are designed to solve - data races.
Here I want to concentrate only on next 2 points:
- Comparison of semantic and typical use cases of atomic CAS and FAA.
- Comparison of performance of CAS and FAA in typical and abnormal cases.
Differences and similarity
Most understandable description of atomic operation that I know is equivalent code:
int atomic_fetch_add(int* target, int add)
{
int old = *target;
*target += add;
return old;
}
bool atomic_compare_exchange(int* target, int* expected, int desired)
{
if (*target == *expected) {
*target = desired;
return true;
}
return false;
}
Difference in behaviour:
compare_exchange |
fetch_add |
|---|---|
| can fail | can't fail - always succeeds |
| leaves memory unchanged if fails | always changes memory |
succeeds only within narrow contition - equality of values pointed to by target and expected
|
rollback of changes requires another memory write operation |
| implies a loop of retries | no loops |
Both compare_exchange and fetch_add are equivalent, in the sense that it is possible to define (implement) one through another.
But differences are huge and sometimes (you'll see) usage of inappropriate atomic operation leads to significant performance impact up to complete inoperability of program.
Basic use cases:
compare_exchange |
fetch_add |
|---|---|
| program thread waits for some changes made by the other thread | program thread can continue progress in any case |
| lock, mutual exclusion (mutex) | atomic counter, refcounter (shared_ptr, ...) |
Benchmarks
Basically, implemented shared_ptr and spinlock each with both compare_exchange and fetch_add.
And compared their performance under aggressive concurrent read/write access.
Also compared to standard std::mutex and std::shared_ptr.
Code: https://github.com/agutikov/faa_vs_cmpxchg
shared_ptr implementaion
Instead of posting complete code of shared_ptr here, I provide just difference between two implementations.
Main part is decrement of reference counter.
Implemented with fetch_sub:
int decref(std::atomic<int>* r)
{
return std::atomic_fetch_sub(r, 1);
}
Implemented with compare_exchange:
int decref(std::atomic<int>* r)
{
int v;
do {
v = r->load();
} while (!std::atomic_compare_exchange_weak(r, &v, v-1));
return v;
}
Benchmark contains both implementations of decref: with std::atomic_compare_exchange_weak and std::atomic_compare_exchange_strong.
spinlock implementation
Main part of spinlock is .
Implemented with fetch_add:
struct spinlock
{
std::atomic<int> locked = 0;
void lock()
{
while (std::atomic_fetch_add(&locked, 1) != 0) {
locked--;
}
}
void unlock()
{
locked--;
}
};
Implemented with compare_exchange:
struct spinlock
{
std::atomic<bool> locked = false;
void lock()
{
bool v = false;
if (!std::atomic_compare_exchange_weak(lock, &v, true)) {
for (;;) {
if (locked.load() == 0) {
if (std::atomic_compare_exchange_weak(lock, &v, true)) {
break;
}
}
// benchmarked both variants with "pause" and without
__asm("pause");
}
}
}
void unlock()
{
locked = false;
}
};
Benchmark contains both implementations of spinlock: with std::atomic_compare_exchange_weak and std::atomic_compare_exchange_strong.
Benchmark for shared_ptr
- Creates single instance of
shred_ptr<int>. - Pass it into variable number of benchmark threads.
- Each thread do copy and move of shared_ptr N times in loop.
- N = Total_N / n_threads. So each run of benchmark with different number of thread do the same total number of lopp iterations.
Workload function:
template< template<typename T> typename shared_ptr_t >
void shared_ptr_benchmark(shared_ptr_t<int> p, int64_t counter)
{
while (counter > 0) {
shared_ptr_t<int> p1(p);
shared_ptr_t<int> p2(std::move(p1));
if (!p1 && p2) {
// try to protect code from been optimized out by compiler
counter -= *p2;
} else {
fprintf(stderr, "ERROR %p %p %p\n", p, p1.block, p2.block);
std::abort();
}
}
}
How to get callable for benchmark threads:
shared_ptr_t<int> p(new int(1));
auto thread_work = [p, counter] () {
shared_ptr_benchmark<shared_ptr_t>(p, counter);
};
}
Benchmark for spinlock
- Create single instance of
spinlock. - Pass it into variable number of benchmark threads.
- Each thread do fast modifications of global variables with holding a lock, N times in loop.
- N = Total_N / n_threads. So each run of benchmark with different number of thread do the same total number of loop iterations.
Workload function:
struct spinlock_benchmark_data
{
size_t value1 = 0;
uint8_t padding[8192];
size_t value2 = 0;
};
template<typename spinlock_t>
void spinlock_benchmark(spinlock_t* slock,
int64_t counter,
size_t id,
spinlock_benchmark_data* global_data)
{
while (counter > 0) {
slock->lock();
size_t v1 = global_data->value1;
global_data->value1 = id;
size_t v2 = global_data->value2;
global_data->value2 = id;
slock->unlock();
if (v1 != v2) {
fprintf(stderr, "ERROR %lu != %lu\n", v1, v2);
std::abort();
}
counter--;
}
}
How to get callable for benchmark threads:
spinlock_t* slock = new spinlock_t;
spinlock_benchmark_data* global_data = new spinlock_benchmark_data;
return [slock, counter, global_data] () {
std::hash<std::thread::id> hasher;
size_t id = hasher(std::this_thread::get_id());
spinlock_benchmark<spinlock_t>(slock, counter, id, global_data);
};
Measurements
Measured:
- Complete wall-clock time of execution of all benchmark threads with
std::chrono::steady_clock. - CPU time spent, by
std::clock. Then results divided by total number of iterations performed to evaluate approximate read and CPU time spent for each iteration.
Resulting charts
Benchmarks ran on a laptop with i7-8550U.
shared_ptr: average CPU time per loop iteration, nanoseconds, less is better:

shared_ptr: average CPU time per loop iteration, relative to baseline std::shared_ptr, less is better:
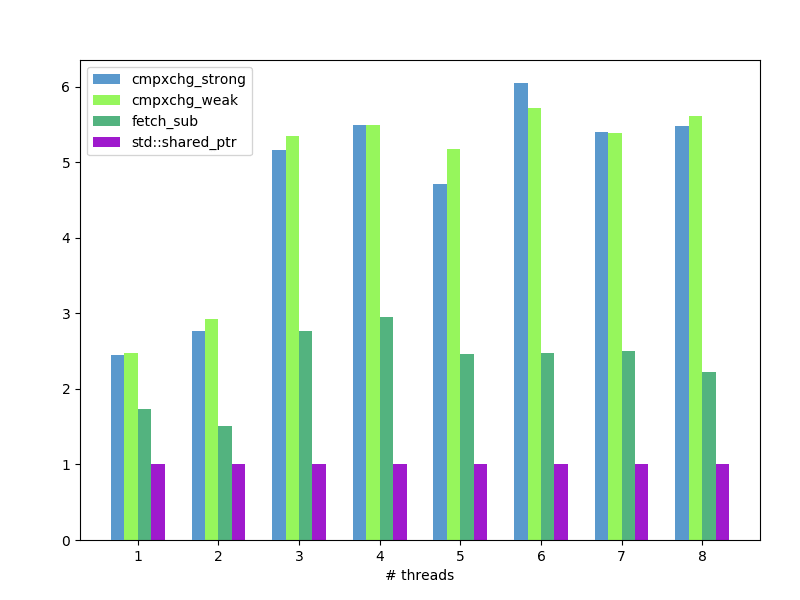
shared_ptr: average wall-clock time per loop iteration, nanoseconds, less is better:
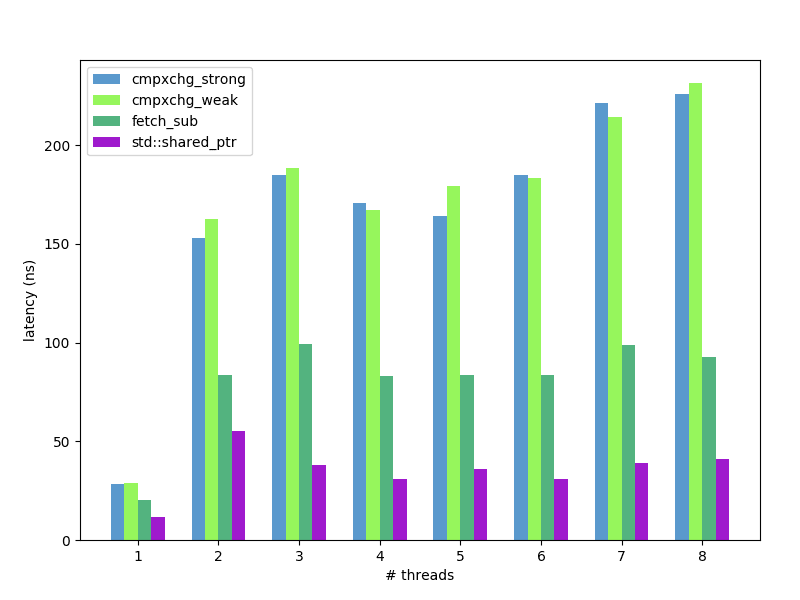
shared_ptr: average wall-clock time per loop iteration, relative to baseline std::shared_ptr, less is better:

spinlock: average CPU time per loop iteration, nanoseconds, less is better:

spinlock: average CPU time per loop iteration, relative to baseline std::mutex, less is better:
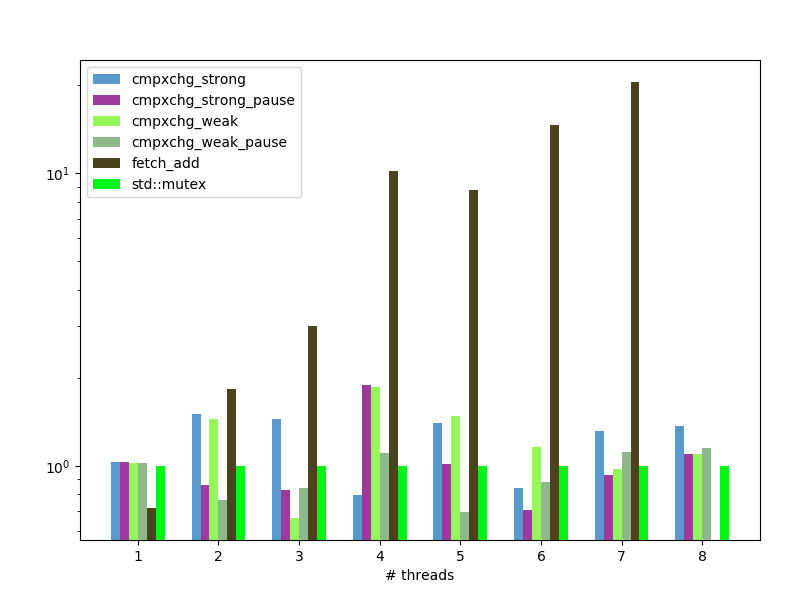
spinlock: average CPU time per loop iteration, without fetch_add, nanoseconds, less is better:

spinlock: average CPU time per loop iteration, without fetch_add, relative to baseline std::mutex, less is better:
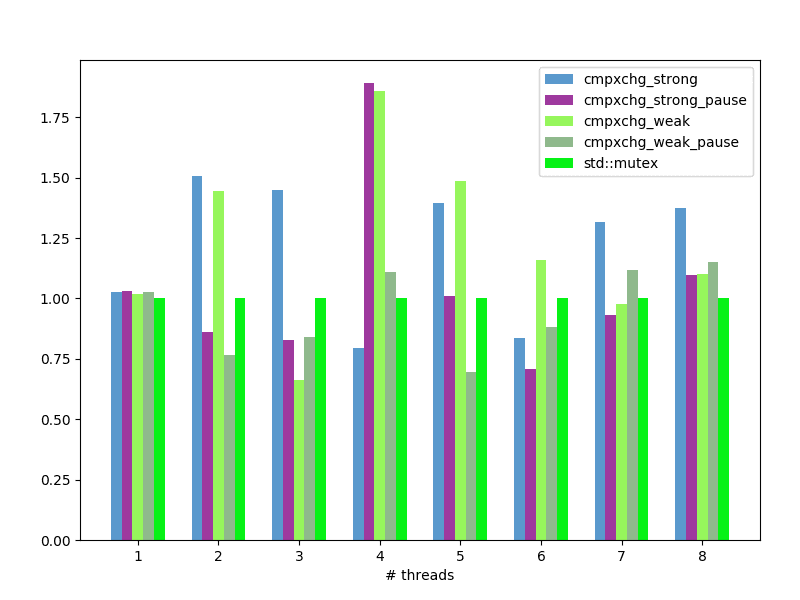
spinlock: average wall-clock time per loop iteration, nanoseconds, less is better:
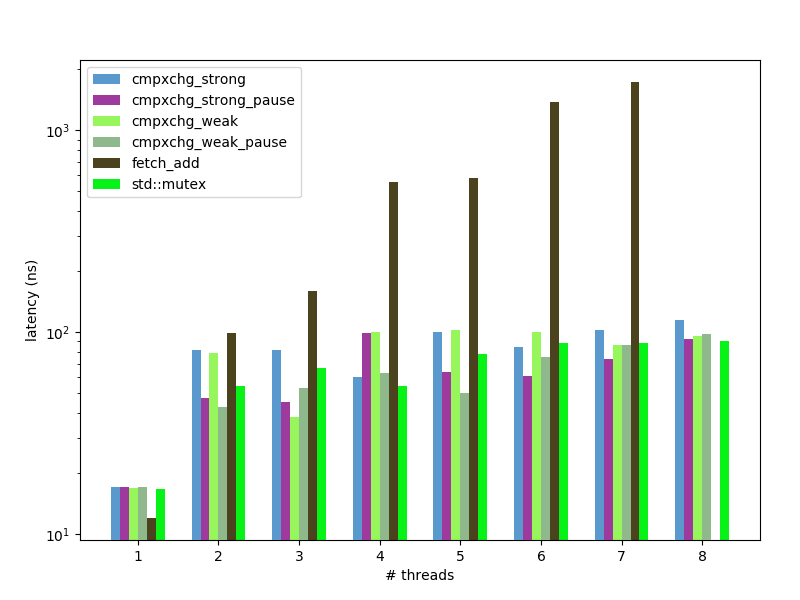
spinlock: average wall-clock time per loop iteration, relative to baseline std::mutex, less is better:
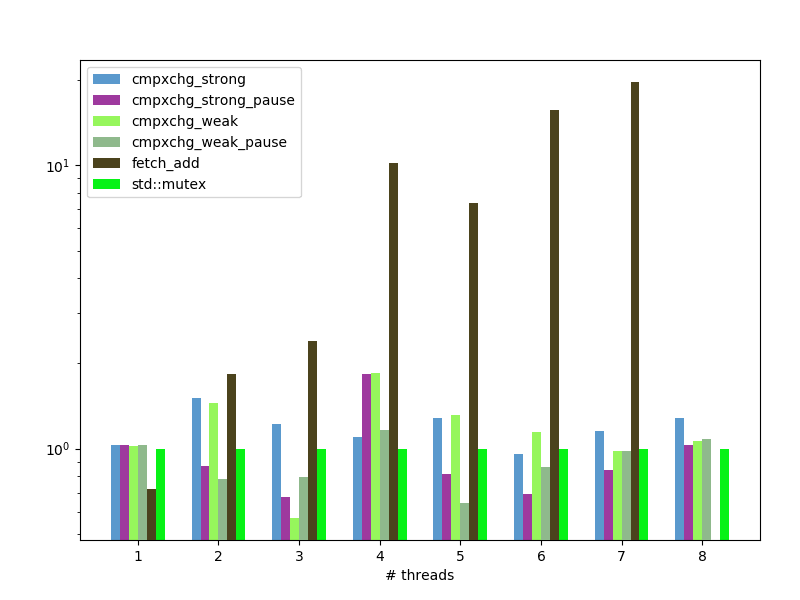
spinlock: average wall-clock time per loop iteration, without fetch_add, nanoseconds, less is better:

spinlock: average wall-clock time per loop iteration, without fetch_add, relative to baseline std::mutex, less is better:

Conclusion
-
fetch_subis twice faster thencompare_exchangefor reference counters. - But standard
std::shared_ptris much faster than my implementation, but I still do not understand why. - Spinlock implemented with
fetch_addcause so many memory modifications that it drastically (x100) increase time required for lock operation. It shows unacceptable performance while used in 4 threads and more. - Simple spinlock implemented with
compare_exchangecan be as fast asstd::mutexand even little-bit faster.
Update
Right after publication I realized that atomic_fetch_or is much more suited for spinlock implementation. Here it is:
struct for_spinlock
{
std::atomic<int> locked = 0;
void lock()
{
while (std::atomic_fetch_or(&locked, 1) != 0) {
__asm("pause");
}
}
void unlock()
{
locked = 0;
}
};
And here is benchmark results:
spinlock: average CPU time per loop iteration, nanoseconds, less is better:
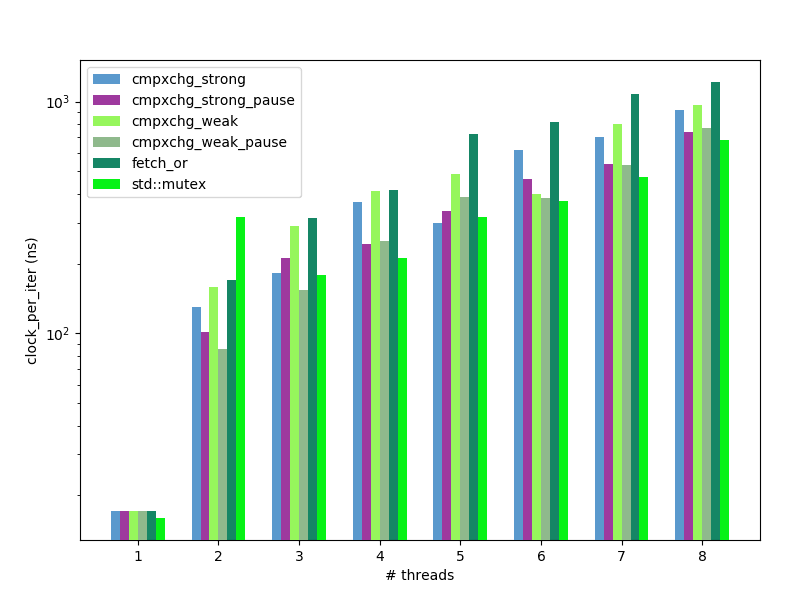
spinlock: average CPU time per loop iteration, relative to baseline std::mutex, less is better:

spinlock: average wall-clock time per loop iteration, nanoseconds, less is better:

spinlock: average wall-clock time per loop iteration, relative to baseline std::mutex, less is better:

So, better implementation of spinlock with atomic_fetch_or is only 2 times slower than compare_exchange one.




Top comments (1)
Very well written, thanks for sharing