When you develop a prototype, functionality and features need to be delivered in time. You push feature after feature, relying mostly on manual tests and maybe, occasionally using automatic test as well. It’s not that you don’t want to test. Its more that time constraints make developing a stable code base and a stable test suite more tedious then beneficial. How to cope with this challenge?
Recently I had a similar situation. I wanted to implement an application in a couple of days, but still use automatic tests. Halfway through implementing, I found myself using a particular cycle: write a function, write a test, disable the test and continue with the next functions. In each iteration, I introduced several, often breaking changes to the code base. Tests from earlier iterations become unusable for two reasons. First, the data model and/or functions evolved so that old tests simply are not applicable any more. Second, the tests were working on dynamic, external data which could only be stabilized at the time of writing a particular test, but not after this time. Instead of fixing the complete test suite, I only enabled tests for the code base that I did not change.
I call this style Drive-By-Testing, a development method to produce prototypes supported by automated tests. The goal is to keep development speed high and to have just enough tests for regression and for the current feature iteration.
By reading this article, you will get an understanding of the Drive-By-Testing approach and can see if it's something you can apply in your projects as well. Its divided in two parts. The first part explains the development iterations in a nutshell. The second part is a development example where you get more context about Drive-By-Testing.
This article originally appeared at my blog.
Drive-By-Testing: Iterations in a Nutshell
Iterations are time-boxed phases in which you deliver functionality or features. The first iterations are about setup, getting sample data, and getting familiar with the libraries that you want to use. Then the next iterations deliver core features. Finally, you ship the application to production.
Iteration 1: Setup
As the very first step, setup your development environment and tool chain. Generic steps include:
- Create a new Git repository
- Create required directories
- Add application libraries
- Add test libraries and utilities
- Add IDE helpers
Then start to develop the very first feature of your data, for which you will need sample data
Iteration 2: Get Sample Data
Sample data is needed to feed your functions. If you develop a data model for yourself, just write the sample data yourself. If you use an existing data model, then add a library to your project and use its methods for fetching data.
Do you need a test here? Strong no! Familiarize with the library, work on your program until you get it running.
Iteration 3: Processing and Filtering Data
In the third iteration you are using the sample data for further processing and filtering. Concretely: You either directly store the data or parts of it, or you are transforming the data so that it fits your application needs.
In this iteration you start to write tests. I even encourage to write the tests first, then the functions because it helps you to think about what you want to do with this data.
Iteration 4: Core Features
You have the data, you transform and store the data, now work on your core features. In this phase, you will spend some time working out which features you need to fulfil the core requirements of your application.
In protoyping you will face evolving data structures and features. Naturally, old code becomes cold, and associated unit test obsolete. This iteration is at the center of drive-by-development: Keep moving, abandon functions and tests that are not providing any more value.
Iteration 5: Stabilizing for Production
You have implemented a solid internal data model. Core features are working. It’s time to finish up your work and release it.
In this iteration you review your application from the inside out. It’s possible to discover assumptions that you made early on are not applicable any more. You might reconsider how your service is used, or even tweak your internal data model.
Tests from iteration 4, from features that survived, and tests remaining from iteration 2 will be the foundation on which you build. Try to keep as many as possible to be still usable with the last finishing touches.
Drive-By-Testing: Development Example
To see this approach applied in practice, I will explain the development journey of my Kube Log Exporter, or short KubeLog. This tool is a a helper to persist Kubernetes log data in files, either on your local machine or running as a periodically scheduled Cron Job in the cluster. To follow this example, you should be familiar with NodeJS, Jest and know about Kubernetes resources like pods and namespaces.
Iteration 1: Setup
No surprises here: Creating the Git repository, all required directories, and then import the required libraries. I'm using the official Kubernetes Node.JS API.
Iteration 2: Get Sample Data
My first task in KubeLog is to get a list of pod objects from my Kubernetes cluster. So I need to import the library, create an instance and define the configuration. With this, I can use the library to connect to the Kubernetes cluster and fetch a list of pod objects. This data can then be used the sample data.
My program creates a k8s.KubeConfig() instance which loads my local .kubeconfig file. Then I use this instance to call listNamespacedPod which returns a list of podObjects. This list is stored in the file seed.json.
const fs = require('fs');
const k8s = require('@kubernetes/client-node');
let k8sApi = {};
const configure = (fromCluster = false) => {
try {
const kc = new k8s.KubeConfig();
kc.loadFromDefault();
k8sApi = kc.makeApiClient(k8s.CoreV1Api);
} catch (e) {
console.log(e);
}
}
const getPodsInNamespace = async (namespace = 'default') => {
const podObjectList = (await k8sApi.listNamespacedPod(namespace)).body;
fs.writeFileSync("seed.json", JSON.stringify(podObjectList));
}
Iteration 3: Processing and Filtering Data
The Pod Objects that are returned from the API are complex. I just want to filter the names of the pods.
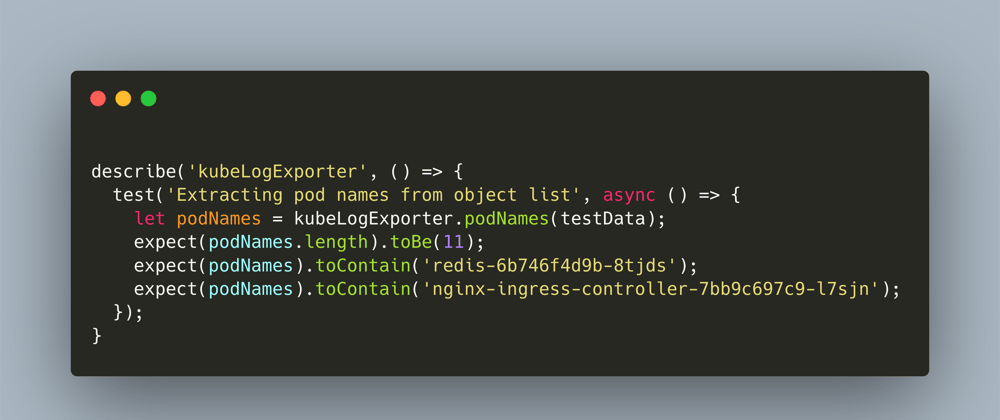
In this iteration, I started to write the unit test file first.
describe('kubeLogExporter', () => {
test('Extracting pod names from object list', async () => {
let podNames = kubeLogExporter.podNames(testData);
expect(podNames.length).toBe(11);
expect(podNames).toContain('redis-6b746f4d9b-8tjds');
expect(podNames).toContain('nginx-ingress-controller-7bb9c697c9-l7sjn');
});
...
As you see, this test code is tied to the contents of seed.json. I test for the length of the returned array, and I test for the names of pods contained in the list.
To find out where the pod names are stored, I load the contents of seed.json in an interactive node cli session. Turns out the correct path is this: item.metadata.name:
{
"apiVersion": "v1",
"items": [
{
"metadata": {
"creationTimestamp": "2020-04-25T11:13:16.000Z",
"generateName": "svclb-nginx-ingress-controller-",
"labels": {
"app": "svclb-nginx-ingress-controller",
"controller-revision-hash": "777f6998cf",
"pod-template-generation": "1",
"svccontroller.k3s.cattle.io/svcname": "nginx-ingress-controller"
},
"name": "svclb-nginx-ingress-controller-5sw92",
...
}
Iteration 4: Core Features
In KubeLog, once I had the name of the pods, I need the right API call to fetch the log data, and an efficient, reliable method for merging log data with data already stored in the log files.
I considered several options: Using regexp to check for duplicate data, using git-like dives, and simple string comparison. Halfway through implementation, I identified the essential behavior of the merges with four cases:
- A No data in file, log data from pod
- B Data in file, no log data from pod
- C Data in file, log data from pod partly overlaps
- D Data in file, log data from pod completely supplements this data
For each case, I wrote distinct unit tests like this one:
test('consolidate synth logs 1', async() => {
const redis1Log = fs.readFileSync('tests/redis1.log', 'utf8');
const redis2Log = fs.readFileSync('tests/redis2.log', 'utf8');
const synthMergeLog = fs.readFileSync('tests/redis_merge_1_2.log', 'utf8');
const mergedLog = kubeLogExporter.mergeLogTexts(redis1Log, redis2Log);
expect(mergedLog).toBe(synthMergeLog);
});
And this actually led me to recognize the essential solution: Divide each line of text from the log file and the log data, merge these two arrays and remove all duplicates. The final implementation is:
const mergeLogTexts = (log1, log2) => {
const unified = [... new Set(log1.split("\n").concat(log2.split("\n")))]
return unified.join("\n");
}
Iteration 5: Stabilizing for Production
To execute log date extraction, you define a namespace to list of pod name patterns as shown:
exportToLocalDir('default', [/redis/, /lighthouse/]);
So far, all log date extraction was successful. But when I wanted to export data from core services, like the Ingress controller or load balancer, they failed. The reason: When a Pod has more than one container, the log data extraction needs to mention the container name as well!
The changes from this observation lead to a new set of tests and the removal of several methods from iteration 3. This change is crucial, so I disabled older tests and used the following one.
test('accesing logs from pods with multiple containers', async() => {
var podNames = await kubeLogExporter.getPodContainers('default', [/svclb-nginx-ingress-controller-5sw92/, /redis/])
expect(podNames.length).toBe(3);
expect(podNames[0][0]).toBe('svclb-nginx-ingress-controller-5sw92')
expect(podNames[0][1]).toBe('lb-port-80')
expect(podNames[1][1]).toBe('lb-port-443')
expect(podNames[2][0]).toBe('redis-6b746f4d9b-8tjds')
expect(podNames[2][1]).toBe('redis')
With these final changes, log file export works fully.
Conclusion
Drive-by-testing is a software development approach for prototyping applications and supporting automated tests. It acknowledges the absolute changeability of a rapidly evolving code base and it encourages you to use automated tests on per development cycle. New cycles bring new features and new data models that will break old tests. You do not go back and fix those tests, but only keep what is stable. Stable means: It’s based on synthetic data, this data is still relevant, and the features are still in your code base. Drive-By-Testing produces prototypes with a suitable number of tests, but tests won’t slow you down, but keep a fast development speed.





Top comments (0)