In the 2nd article about Infrastructure@Home, I will show how to use the configuration management tool Ansible. We will see how to setup Ansible and how to execute a simple command that connects to all nodes.
This article originally appeared in my blog.
Ansible: Basic Concepts
Ansible is an open source configuration, deployment and provisioning tool. Invented in 2012 and battle tested at companies with very complex IT systems, it showed a scalable approach how infrastructure can be expressed as code.
Ansible has three essential requirements: It needs to be installed on one control node from which ansible commands are executed, it needs an SSH access to its managed nodes, and pythons needs to be installed on all nodes. The managed nodes do not need any additional software, such as an agent.
An Ansible project defines the inventory, a list of managed nodes, and the tasks which are to be executed on the nodes. Tasks rely on modules, wrapper for programs in the managed nodes, such as apt or yum for installing packages, copy or template for copying files, and command for executing shell commands. Variables can be defined and used in the tasks or files. And finally, the playbook is the ordered collection of all tasks that are executed against the nodes.
Ansible: Basic Directory Layout
Before we can start to use Ansible, we need to:
- Install Ansible on the control machine
- Copy our public SSH key to all nodes (see this guide)
Then, we create a new folder and use the following simplified directory layout.
infrastructure/
ansible.cfg
hosts.ini
connection_test.yml
As we see, there is a central configuration file ansible.cfg. This file defines the general behavior of task execution. For now, we just need to define where our inventory comes from:
[defaults]
inventory=hosts
The hosts file contains grouped entries of all nodes that we want to manage. We will use the hostnames for our machines. I differentiate into raspis and server to remind myself that different Linux distributions are running on these servers. The file looks as follows:
[raspis]
raspi-3-1
raspi-3-2
raspi-4-1
raspi-4-2
raspi-0
[server]
linux-workstation
Unfortunately, hostname lookup did not work, so I need to add explicit IP addresses. Be sure to give your devices static IP addresses with your router/dhcp server.
raspi-3-1 ansible_host=192.168.2.107
raspi-3-2 ansible_host=192.168.2.104
raspi-4-1 ansible_host=192.168.2.102
raspi-4-2 ansible_host=192.168.2.105
Also, on the server I use a different username to execute the ansible commands.
[server]
linux-workstation ansible_host=192.168.2.200 ansible_user=devcon
Now we have created the Ansible configuration file and our inventory. Keep in mind that we use a simplified directory structure: Ansible documents several best practices which are helpful for experienced users that need to share Ansible files with other colleagues. And also, the configuration file can contain other options that help to boost the task execution speed, like using SSH multiplexing, pipelining and executing tasks asynchronous.
Test: Connect to all Nodes
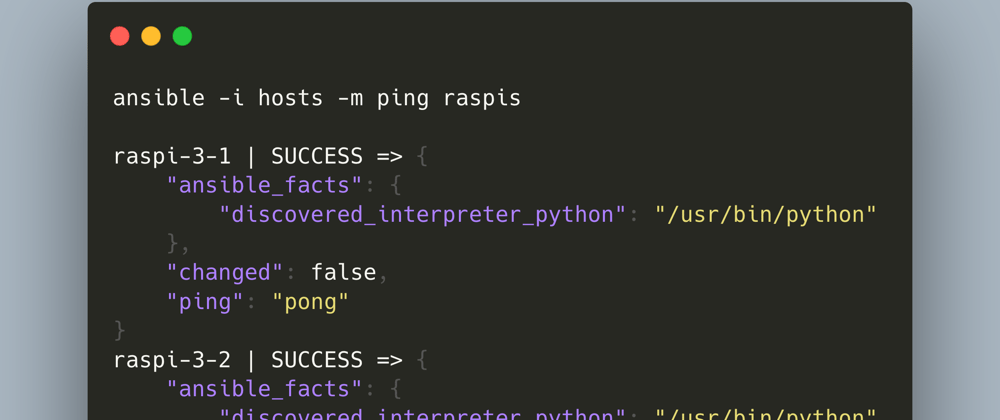
With Ansible, you can execute ad-hoc commands on the nodes simply in the command line. Lets ping our nodes:
ansible -i hosts -m ping raspis
We see this. Output:
raspi-3-1 | SUCCESS => {
"ansible_facts": {
"discovered_interpreter_python": "/usr/bin/python"
},
"changed": false,
"ping": "pong"
}
raspi-3-2 | SUCCESS => {
"ansible_facts": {
"discovered_interpreter_python": "/usr/bin/python"
},
"changed": false,
"ping": "pong"
}
…
This looks good, we can reach all machines. Now we will put this command into a task file and execute the task. Open the file connection_test.yml and input this text:
- name: Test if we can connect to all nodes
hosts: all
tasks:
- name: Ping the node
ping:
Let’s go through all of these lines:
- Line 1: A descriptive name for this playbook
- Line 2: A reference to the nodes to which this playbook is applied. We reference the group names that we defined in the hosts.ini file
- Line 5: The tasks that we will execute on the node
- Each task has a descriptive name and it uses an Ansible module
- We execute the command ping
Let’s execute the playbook:
ansible-playbook connect.yml —limit "raspi-3-1"
We will see the same output as before. If we only want to connect to one specific node, we can use this command:
ansible-playbook connect.yml —limit "raspi-3-1"
Now, let’s reorder the directory as follows:
infrastructure/
ansible.cfg
hosts.ini
system/
connection_test.yml
Conclusion
This article shows how to setup Ansible. The requirements are to install Ansible on the control machine and to have SSH access to all nodes. Then, we create a basic directory layout with an Ansible conjuration file, an inventory of all nodes, and the first playbook. We also learned how to execute Ad-Hoc commands via the command line and how to write a playbook that tests if we can connect to all nodes.





Top comments (0)