
# Git Under the hood

“Git is modern distributed version control system helps developers or anyone who want to keep track of changes in their file system” We can name it as a timeline of our project from beginning to end.
As an software engineers lot of us use Git ,only few know the exact internals or what happens under the hood.
what happens internally when you do a file change and commit it?
How is git tracking all the changes occurred for the file?
Sometime you may run into issues which you won’t know how to resolve without understanding how git works in the backend.
In this article, I am sharing a deep dive understanding on How Git works under the hood by taking simple examples.
Note : This article is to understand how git works using low level commands and what happens behind the scenes. It is not a guide to work with Git
Initialize a Git Repository
Lets start with initializing a Git repository using git init command.
It creates a hidden folder called .git which contains different files and folders inside

This folder contains all information and configuration needed for git to version control. Here we are mainly concentrated on objects folder where this will contain the tracking information of our file system.
Git 3 states or repository states
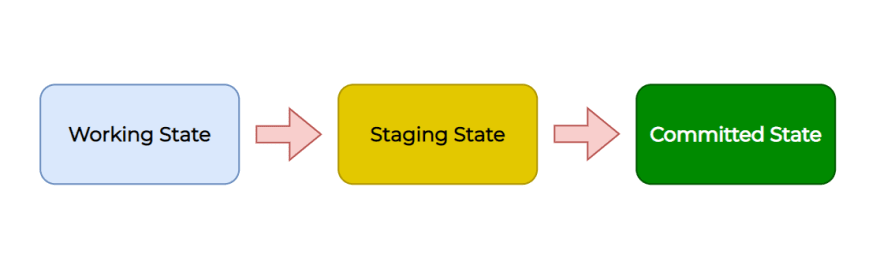
Working State - This is when you add, remove or modify something in the file. Git will notice the change but you will not formerly inform Git to save the changes. In traditional way these are “Untracked/ Not Staged Changes”
Staging State - This is when you inform Git of the change and tell Git to take note of that change. Commonly Known as Staging area. Staging changes can be done using git add command. Modification of file can be done even after staging it, which lets you see the file both in Working state and staged state.
Committed Stage - This is the stage where Git has saved your Working state changes in .git folder in the form of git objects. In Traditional way It is achieved using git commit command.
Here lets look into the Git Internals/ Behind the scenes How Git stores the changes
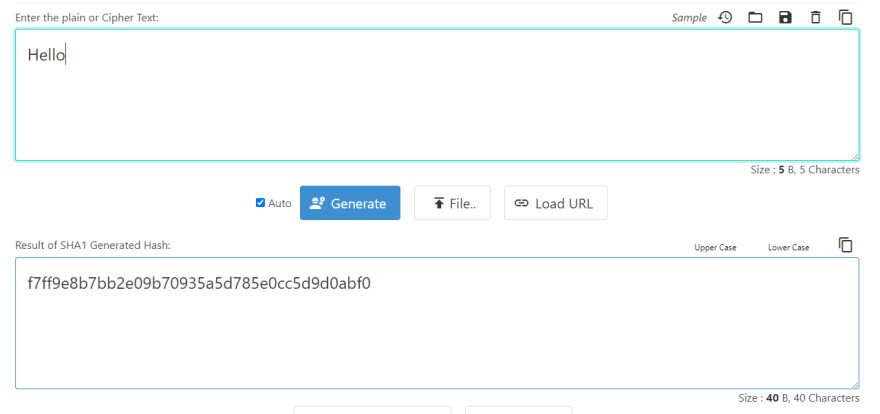
Git is a content-addressable file system or a simple key value data file system. That means If you insert any kind of content into the Git It will return you hand you back with a unique key so you can use that later to retrieve the content.
Unique Key is nothing but a Secure hash algorithm (SHA-1), which is a cryptographic hash function that takes an input and produces a 160-bit (20-byte) hash value typically rendered as a hexadecimal which is 40 digits long*.*
Using this Hash function we can reference any file content, commits etc.
A single space change in content will lead to different Hash value/ Unique key generation
Each Hash value generated will be linked with the git objects in Git to understand the changes made by developer in working stage to save it in committed stage.
Now its time for Git Objects. Git File system uses 4 types of git objects. These are the only object types required for git to save the necessary data
- Blob - any type of files it may be photo, video or any file extensions is stored as a blob
- Tree - Information of Directories is stores as a Tree. Tree can contain a set of Blobs and even it can contain set of trees with blobs. Tree is representation of folder/directory in Git
- Commit - With the help of commit object type, You can save different versions of our project
- Annotated Tag - Its actually persistent text pointer to specific commit
Lets create a sample file named gitsample.txt. lets stage and commit it and see how the file is stored in .git folder as an object types
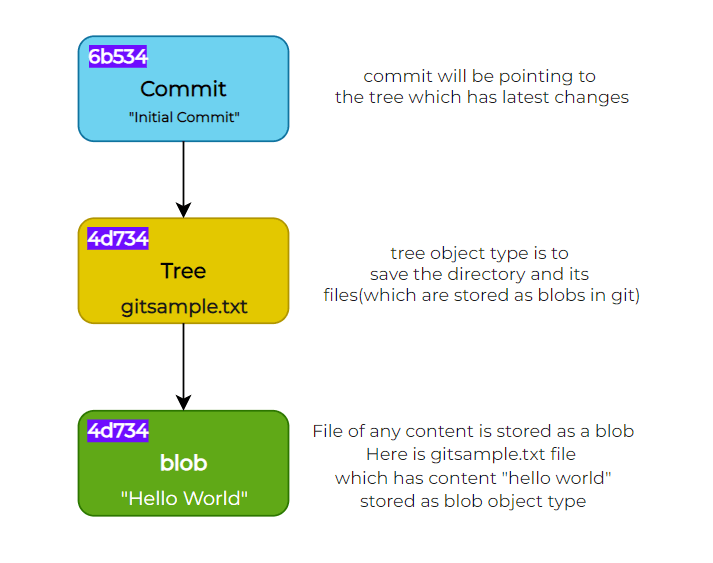
According to above explanation there will be three object types created when we commit the file.
Blob to store the content, tree which has information of the latest blob which was created when file is created/Changed and next is Commit object type which has information of the latest tree created
Hierarchy can be assumed like this for object types
Steps to reproduce the above scenario
- Create a file named gitsample.txt inside the git repository. Save “Hello World” inside the file
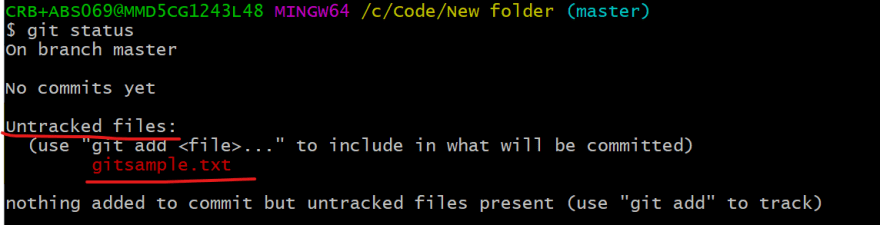
- Run git status command in git bash pointing to the git repo folder. As we previously discussed the file changed/ created will be in the Working state or also known as Untracked changes so now here gitsample.txt will be shown as an untracked change.
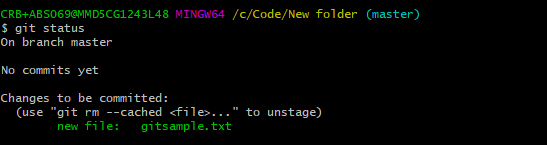
- Next step is to move file from Working state to Staging state by running command git add . Run git status after this command. gitsample.txt will be moved to Staging state.
One more thing to observe i.e. in .git/objects folder new blob object will be created with a unique key/ SHA 1 key as a file name. First 2 numbers of hash key will be used for a folder name.
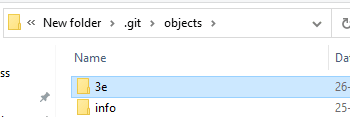
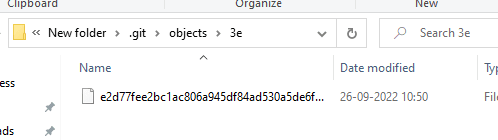
Combining both folder name and file name will be the hash key of gitsample.txt file. so the hash key will be 3ee2d77fee2bc1ac806a945df84ad530a5de6fd8
- To ensure this run a git low level command git cat-file -p . This should retrieve the content “Hello World” used in gitsample.txt

- Next from Staging state it should be moved to Committed State,
To Commit we have to run the command git commit -m “Initial Commit”.

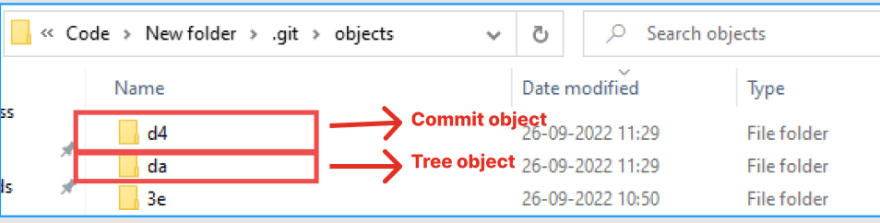
- When changes are moved to committed state it creates other 2 objects Tree and commit object.
- Tree will also have its own new Hash key generated and It will be holding the file name and hash key of the blob object created during staging
- Commit will also have its own Hash key generated and it will be holding the the tree objects hash key which newly got created and the commit message.
To ensure these are the tree and commit objects run the low level command git cat-file using -t extension and respective hash keys. It will show the type of the object


- With these object changes in .git/objects folder, HEAD file in .git/refs folder will have a file naming branch name master with latest commit hash key inside it.
What happens when there is a change in same file and its committed?
- Again the same process repeats which will create new blob, commit and tree with their own hash keys.
- Commit will hold information of previous commit key.

What happens when New Branch Created and checked out?
- .git/refs/HEAD folder will have another file with branch name and latest commit hash key derived from the parent branch
![]()
- HEAD in .git folder will point to that branch.
![]()
Wrapping Up
I hope this article gives you a clear understanding on how Git works on back scenes. And hopefully you will be aware of most crucial parts of the git after reading this article.
If you have reached this point, thanks for reading. I am Abilash S, You can check my latest posts regarding technology in these platforms. Feel Free to connect in any of these platforms





Latest comments (0)