A request

This request comes straight at you from u/Jimmyxavi. Looks like he’s working on a project for university and wanted to get the steam file size for all early access games.
So, here we goooooooooo….
Puppeteer was my weapon of choice for this scrape. I’ve wrote a few times about it and it’s still one of my favorite weapons. I probably could have done the scrape a bit quicker with Axios but any time I’m going to hit a website thousands of times, I kind of like the imposed speed slow down that puppeteer gives me. It also allows me to easily do some of the interactions that were helpful here, like change a dropdown.
The gatekeeper called Algolia
I dug around on steamdb.info to look to see if I could navigate directly to any pages. At first I tried the instant search beta which is a really cool tool but kind of crappy for web scraping. It uses something called Algolia which is like Elastic search and just makes for very powerful, fast searching.
I just so happened to have just discussed Algolia with my good friend Matt (see his cool packaging company Citadel Packaging) two weeks ago. I was looking for some tools in order to improve the search over at Cobalt Intelligence (great business leads there!) and Aloglia was one of the things that he suggested.
Algolia is built for quick searching but limits total results to 1,000. It depends on you passing a query and it will limit those results to 1,000. If I don’t pass a query, I can’t get more than 1,000 even if the total amount is closer to 5,000. I tinkered around with it a little bit but just decided to go with their other search option.
Enter their old search
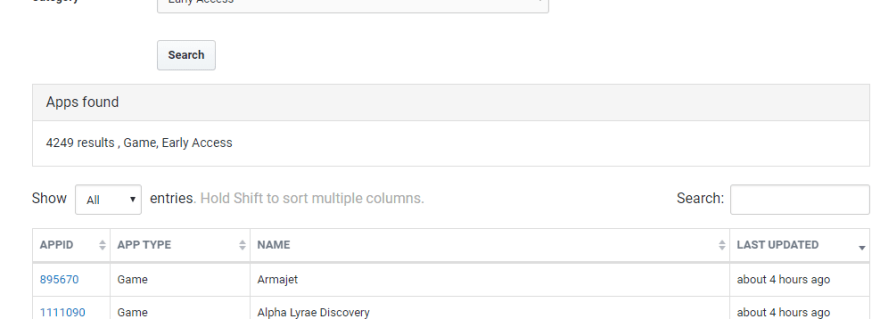
Here is the first helpful link –
https://steamdb.info/search/?a=app&q=&type=1&category=666 . Type 1 I’m guessing is “Game” and category 666 is “Early Access”. As you can see, this page offers 4,249 games. By default it only shows 25 results. This is where puppeteer shines. With a command as simple as await page.select('#table-sortable_length select', '-1'); I can set the dropdown to whatever value I want. In this case, -1 is ‘All’.
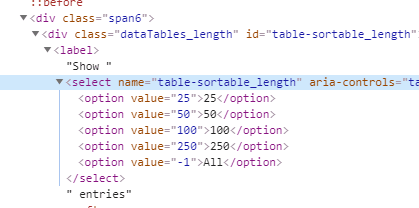
From here, I just loop through each row and get the url for each app and the name. I then push them into an array that I will later loop through and open each page stored.
const appsInfo: any[] = [];
for (let app of apps) {
const url = await getPropertyBySelector(app, 'a', 'href');
const name = await getPropertyBySelector(app, 'td:nth-of-type(3)', 'innerHTML');
appsInfo.push({
url: url,
name: name
});
}
The next helpful link is the actual location of the depots which displays the size information. https://steamdb.info/app/570/depots/ – this is the depot for one of the best games ever invited, Dota 2. As you can see, it lists a bunch of builds and the size of each.

export async function handleDepots(app: any, page: Page) {
await page.goto(`${app.url}depots/`);
const table = await page.$('#depots table:first-of-type tbody');
if (!table) {
return Promise.resolve();
}
const depots = await table.$$('tr');
console.log('depots length', depots.length);
for (let i = 0; i < depots.length; i++) {
const depotSize = await depots[i].$eval('[data-sort]', elem => elem.textContent);
const actualDepotSize = await depots[i].$eval('[data-sort]', elem => elem.getAttribute('data-sort'));
const depotName = await getPropertyBySelector(depots[i], 'td:nth-of-type(2)', 'innerHTML');
const macRow = await depots[i].$('.icon-macos');
if (!macRow) {
app[`depot${i + 1}Size`] = depotSize;
app[`depot${i + 1}ActualSize`] = actualDepotSize;
app[`depot${i + 1}Name`] = depotName;
}
}
}
This function is to handle the depot page. It navigates to that page and then finds the depots table with const table = await page.$('#depots table:first-of-type tbody');. Then it loops through the rows and gets the size of the specific depot and the depot name.
I had a bit of a tricky part with this because the actual depot size is stored in a data-sort attribute, which is actually slightly different than the displayed value. I would guess the data-sort attribute is the correct one because that is what it sorts the column by. It was also kind of tricky to pull from the attribute and I ended up having to use const actualDepotSize = await depots[i].$eval('[data-sort]', elem => elem.getAttribute('data-sort'));instead of my normal helper function.
The end

And there we have it. After it all completes (and it took close to 70 minutes!) it outputs to a csv file.
const csv = json2csv.parse(appsInfo);
fs.writeFile('steamApps.csv', csv, async (err) => {
if (err) {
console.log('err while saving file', err);
}
});
Looking for business leads?
Using the techniques talked about here at javascriptwebscrapingguy.com, we’ve been able to launch a way to access awesome business leads. Learn more at Cobalt Intelligence!
The post Jordan Scrapes SteamDB appeared first on JavaScript Web Scraping Guy.





Top comments (2)
Nice! If algolia has all the data used to render the page, you can directly call the algolia APIs instead of navigating to each page and scraping it. Should be more performant, simpler code, and less likely to get rate limited / blocked by SteamDB since you only hit them once to inject your javascript payload.
I looked at calling aloglia directly and it DID work but it's limited to just 1,000 results. I'm only a little familiar with algolia but I believe the algolia engine here is built for filtering. They don't expect anyone to want more than 1,000 results so there is no way for me to just "get all" without a filter.
I like your thinking, though!